Автор: Leonid Filatov
Эксклюзивно для форума: xss.pro
Часть: [3/3]
Ссылка на первую статью: xss.pro/threads/125338/
Ссылка на вторую статью: xss.pro/threads/125492/
В предыдущих двух статьях (см. самый верх статьи) мы узнали что такое HTTP запросы и как работать с ними, узнали что такое защита в виде CSRF токена и успешно обошли её.
После чего мы создали Brute/Checker с помощью OpenBullet 2, который как раз таки обходит защиту в виде CSRF токена.
Если вы новичок, то чтобы вы лучше понимали о чём здесь идёт речь я настоятельно рекомендую вам ознакомиться с первыми двумя статьями! Потому что сегодня мы будем делать очень много похожих действий и заново объяснять это всё я не вижу смысла!
Заранее прошу прощения, если будет какое-то количество графомании и самоповторов, стараюсь всё разжевать.
Итак, давайте теперь сразу к делу. Сегодня мы будем обходить ReCaptcha/HCaptcha и т.д с помощью встроенных возможностей OpenBullet 2.

Сервисы решения капчи:


Сначала выберем сервис, с помощью которого мы будем гадать капчу. Как я уже сказал ранее - я буду использовать CaptchaGuru.




>Этап 1.1. Ловим и разбираем POST запрос на авторизацию.<
Итак, давайте теперь найдём наш POST запрос на авторизацию и посмотрим его содержимое.




>Этап 1.2. Что такое captchaToken и как его получить?<
Для получения captchaToken и успешного обхода капчи нужно сначала найти sitekey на сайте - это уникальный ключ, связывающий капчу конкретно с этим сайтом. Затем этот ключ отправляется в сервис решения капчи, где капча решается, и на выходе возвращается captchaToken. Этот captchaToken мы подставляем в запрос на сайт, чтобы пройти проверку и успешно получить доступ.
Таким образом сайт считает, что капча была решена настоящим пользователем, и разрешает вход. Ниже будет немного терминологии и порядок действий для закрепления.
Что такое captchaToken?
СПОСОБ 1. Поиск SITEKEY в HTML коде страницы авторизации.
Данный метод вообще почти ничем не отличается от получения CSRF токена, который мы находили в моей второй статье [кликабельно] на этапе 3.
На некоторых сайтах sitekey хранится прямо в HTML коде страницы, на которой расположена капча. Но так работает не на всех сайтах, например, у нашей сегодняшей цели sitekey НЕ РАСПОЛОЖЕН прямо в коде страницы.
А так ищем его по способу из второй статьи, только вместо "CSRF" в ответе от GET запроса на страницу авторизации ищем "data-sitekey", либо "sitekey". На этом отличия заканчиваются, поэтому не вижу смысла объяснять это по сто раз.
СПОСОБ 2. Поиск SITEKEY в запросах.
У нашей сегодняшей цели как раз таки можно выловить sitekey в запросах. Для этого нам нужно:


Теперь давайте получим captchaToken с помощью этого ключа.
Наши действия:
Теперь в настройках "Solve ReCaptcha V2" пишем следующее:

Для данного проекта настройки капчи закончились, на этом всё.
Но давайте ещё обсудим чекбоксы "Enterprise", "Is Invisible" и "Use Proxy".
Получение токена может занять время. (Максимальное кол-во времени мы указали на Этапе 0!)

Как мы можем видеть на скринштоте - мы успешно получили токен и сохранили его в пременную RECAPTCHA_RESULT.
Сейчас нам осталось только добавить полученный токен в POST запрос на авторизацию!
Давайте теперь отправим POST запрос, в котором мы будем использовать наш captchaToken.


Теперь сохраняем проект, загружаем валидный аккаунт от сервиса в OB2 и жмём "Start". Ждём пока скрипт отработает и смотрим что выйдет в логе.

Как мы видим - по результатам выходит у нас всё очень даже хорошо! Мы успешно авторизовались в аккаунте, а как бонус мы ещё прям сразу после авторизации видим очень много полезной информации для прикручивания чекера!
А именно:
1. ОПРЕДЕЛЕНИЕ GOOD/BAD:

2. ПАРСИНГ НЕОБХОДИМЫХ ДАННЫХ:
Сейчас мы спарсим fullName, hasBtcCampaigns, customerType и token.




>Этап 4.3. Создание Brute/Checker. Ищем запрос, который отвечает за отображение баланса.<
Мы успешно вошли в аккаунт, спарсили все нужные нам значения и сохранили их в переменные.
ЧТО ЗДЕСЬ НЕ ТАК? ДАВАЙТЕ ПРОВЕРИМ:




Забиваем болт и идём курить бабмбук, ведь у нас ничего не получится.
На самом деле всё очень легко! НАМ ПРОСТО НУЖНО НАЙТИ ВЕРНЫЙ GET ЗАПРОС. (Капитан очевидность в деле!)
Порядок действий:


СОБИРАЕМ НУЖНУЮ ИНФОРМАЦИЮ В КУЧУ:
На данный момент мы имеем:
Мы установили наш User Agent из переменной <USER_AGENT> и добавили наш Bearer токен из переменной <AUTH_TOKEN> в "Authorization: Bearer " (Bearer не нужно удалять).
ПОЛУЧАЕМ БАЛАНС АККАУНТА:

На выходе получаем результат:

Бинго! Мы успешно получили:
Но ради эксперемента давайте попробуем удалить из нашего запроса Bearer токен, отправим запрос посмотрим на результат.
Вот что нам ответил сервер:
 Как можно судить по сообщению, которое мы получили в логе - сайт НЕ ДАЁТ НАМ ВЫПОЛНИТЬ ДЕЙСТВИЕ, потому что не видит у нас токена авторизации и соответственно говорит нам, ЧТО МЫ НЕ АВТОРИЗОВАНЫ!
Как можно судить по сообщению, которое мы получили в логе - сайт НЕ ДАЁТ НАМ ВЫПОЛНИТЬ ДЕЙСТВИЕ, потому что не видит у нас токена авторизации и соответственно говорит нам, ЧТО МЫ НЕ АВТОРИЗОВАНЫ!
>Этап 4.5. Создание Brute/Checker. Сохраняем балансы по переменным после парсинга для вывода в лог.<
На этом этапе нам предстоит то, чем мы занимались в первых двух уроках, поэтому я пробегусь быстренько, а вы просто смотрите скриншоты и повторяйте за мной!
Сейчас мы спарсим btc, btcPending, usd, usdPending и balanceCampaigns.





На этом разработка конфига окончена! Можем спокойно запускать наш конфиг в многопотоке и лутать балансы рекламных кабинетов с которых можно пускать трафик на нужное вам направление! Мне лично выпадал баланс более чем на 1к$ просто с логов, которые я нашёл на раздаче.
Спасибо за то, что уделил(а) время на прочтение этой статьи! Я надеюсь, что этот материал был полезен.
Изначально моей целью было в максимально сжатые сроки научить новичков в нашем деле создавать для себя не супер сложные Бруты/Чекеры на HTTP запросах и экономить на этом свои шекели.
И я думаю у меня получилось это сделать, так как я старался разжевать всё максимально подробно и без лишней информации, которая вам врядли пригодится на старте!
Не буду изменять свои традициям и прикреплю исходник конфига, ковыряйтесь кому интересно:
В следующих статьях в этом направлении (бруты/чекеры/парсеры) я расскажу как создавать конфиг для OpenBullet НЕ НА HTTP ЗАПРОСАХ, а через эмуляцию браузера с помощью Selenium/Puppeteer. Такой подход не всегда работает быстрее чем софт на HTTP запросах, но зато прёт как танк - медленно, но верно.
Хоть сейчас и в моде автоматизация антидетект браузеров с помощью BAS/Python, но нам ещё рано до этого, ведь я всё же хочу дать базовые навыки для старта. И для этого OpenBullet подойдёт очень хорошо, а человеку с опытом разработке на языках программирования не составит труда перенести все эти "кубики" в код, ИМХО.
Рано или поздно мы дойдём и до автоматизации антидетект браузеров, но как говорил классик: "это уже совсем другая история"
Удачи, путник!
Эксклюзивно для форума: xss.pro
Часть: [3/3]
Ссылка на первую статью: xss.pro/threads/125338/
Ссылка на вторую статью: xss.pro/threads/125492/
Предисловие
Доброго времени суток, бойзы и гёрлзы!
В предыдущих двух статьях (см. самый верх статьи) мы узнали что такое HTTP запросы и как работать с ними, узнали что такое защита в виде CSRF токена и успешно обошли её.
После чего мы создали Brute/Checker с помощью OpenBullet 2, который как раз таки обходит защиту в виде CSRF токена.
Если вы новичок, то чтобы вы лучше понимали о чём здесь идёт речь я настоятельно рекомендую вам ознакомиться с первыми двумя статьями! Потому что сегодня мы будем делать очень много похожих действий и заново объяснять это всё я не вижу смысла!
Заранее прошу прощения, если будет какое-то количество графомании и самоповторов, стараюсь всё разжевать.
Итак, давайте теперь сразу к делу. Сегодня мы будем обходить ReCaptcha/HCaptcha и т.д с помощью встроенных возможностей OpenBullet 2.
Что нам понадобится в этом уроке?
Знания:- Ссылка на первую статью: xss.pro/threads/125338/ - если ещё не читали.
- Ссылка на вторую статью: xss.pro/threads/125492/ - если ещё не читали.
- Понимание что такое капча и какие вообще её виды бывают: habr.com/ru/articles/846458/ - это поможет нам определить какая капча стоит на сайте, это будет нужно для успешного решения капчи, ведь мы должны правильно передать сервису решения капчи с какой именно капчей мы работаем.
- Что такое Bearer-token: ru.hexlet.io/qna/glossary/questions/bearer-token-chto-eto - данная информация будет нужна на Этапе 4.3 в этой статье.
- Сегодняшней целью выступит сайт Bitmedia.io. У них как раз на входе есть ReCaptcha 2, а из личного кабинета можно спарсить баланс на сайте, что позволит нам прикрутить чекер!
Сервисы решения капчи:
- Если вам нужно прогонять НЕ МИЛЛИОНЫ строк, то лучше использовать сервисы по решению капчи, а именно RuCaptcha/CaptchaGuru и так далее (полный список можете посмотреть в самом OB2). Сегодня мы будем использовать CaptchaGuru, потому что он дешевле!
- Для брута больших объёмов аккаунтов я бы лучше рекомендовал купить лицензию XEvil. Либо взять у кого-нибудь в аренду под гадание нужного вам типа капчи, тип капчи заранее нужно уточнять перед арендой!
- Валидный аккаунт от сайта Bitmedia.io. Регистрируем сами на временную почту, либо находим аккаунт логах.
- Раздел функций под названием "Captchas", который содержит в себе список со всеми типами капч, которые поддерживает OpenBullet 2.
- В нашем случае сайт использует ReCaptcha 2!
>Этап 0. Настраиваем OpenBullet 2 для обхода Captcha.<
Перед настройкой проекта для работы с капчей сначала настройте проект для работы с mail:pass и прокси (см. вторую статью)
Сначала выберем сервис, с помощью которого мы будем гадать капчу. Как я уже сказал ранее - я буду использовать CaptchaGuru.
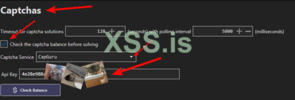
- Открываем OpenBullet 2.
- Нажимаем "RL Settings".
- Находим раздел "Captchas".
- В поле "Timeout for captcha solutions" вводим значение от 120 до 300 секунд (2-5 мин). - Здесь мы указываем количество секунд, которое мы даём скрипту на решение капчи. Если не удасться получить токен в течении этого времени, то скрипт завершится ошибкой.
- Ставим галочку в чекбокс "Check the captcha balance before solving". - Перед стартом скрипт будет проверять наличие баланса на сервисе решения капчи
- Рядом с полем "Captcha Service" есть выпадающий список, выбираем там свой сервис.
- В поле "API Key" Вводим свой API ключ, который мы получили на сайте сервиса решения капчи.
- Жмём на кнопку "$ Check Balance" и нам должен показаться наш баланс. Если баланс не отображается, то внимательнее смотрите на настройки.
- Снизу жмем "Save" и сохраняем настройки.
>Этап 1.1. Ловим и разбираем POST запрос на авторизацию.<
- Как и в первой статье сначала находим ссылку на страницу авторизации. Через Google Dork в этом случае не находится, просто нажимаем на кнопку "Login" в правом верхнем углу и попадаем на страницу авторизации, а именно - "bitmedia.io/app/login".
- Открываем сетевой монитор (CTRL + SHIFT + E), после чего вводим случайные данные, проходим капчу и жмем на кнопку "Login".
- Видим наш запрос, нажимаем на него.
- Открываем вкладку"Headers" и разворачиваем "Request Headers", после чего видим, что запрос отправляется на ссылку "https://bitmedia.io/api/auth/login", сайт использует HTTP версии 2.0, а так же тип отправляемого контента в этот раз у нас "application/json".
- Теперь открываем вкладку "Request" и можем видеть там, что в запросе кроме "email" и "password" вместе с ними ОБЯЗАТЕЛЬНО нужно отправить ещё и "captchaToken".
- После нажатия на "Raw" получаем настоящий вид нашего запроса:
{"email":"caseqafoj.tomocani@labworld.org","password":"41224142124","captchaToken":"03AFcWeA7_Jz_HGZ7y............."}>Этап 1.2. Что такое captchaToken и как его получить?<
Таким образом сайт считает, что капча была решена настоящим пользователем, и разрешает вход. Ниже будет немного терминологии и порядок действий для закрепления.
Что такое captchaToken?
Что такое sitekey?сaptchaToken - это уникальный код, который подтверждает, что капча была решена. Он нужен, чтобы сайт «поверил», что заходит реальный пользователь, а не бот. После успешного решения капчи мы получаем captchaToken и можем использовать его для входа на сайт.
Процесс обхода капчи кратко (теория):Sitekey - это статичный (НЕ ДИНАМИЧЕСКИЙ) ключ, который привязывает капчу к конкретному сайту. Он есть на каждой странице с капчей и находится в HTML-коде / либо в запросах (сетевом мониторе). Сайт с помощью этого ключа «запрашивает» капчу от сервиса, например, reCAPTCHA от Google.
- Шаг 1: Найдите sitekey на странице, где происходит вход (в HTML-коде страницы, либо в запросах).
- Шаг 2: Отправьте sitekey в сервис решения капчи (например, RuCaptcha или CaptchaGuru). Сервис решает капчу и возвращает captchaToken.
- Шаг 3: Подставьте полученный captchaToken в запрос на вход. Сайт принимает token, считая, что капча решена пользователем.
- Изучить встроенные возможности OpenBullet для работы с капчей.
- Получить sitekey и сохранить его в переменную.
- Создать Brute для сайта bitmedia.io с обходом капчи при помощи sitekey.
- Прикрутить Checker после успешного входа в аккаунт через API сайта с использованием Bearer токена.
>Этап 2. Ищем sitekey для дальнейшего использования.<
Sitekey обычно найти очень просто. Это делается двумя способами, давайте разберем их.
СПОСОБ 1. Поиск SITEKEY в HTML коде страницы авторизации.
Данный метод вообще почти ничем не отличается от получения CSRF токена, который мы находили в моей второй статье [кликабельно] на этапе 3.
На некоторых сайтах sitekey хранится прямо в HTML коде страницы, на которой расположена капча. Но так работает не на всех сайтах, например, у нашей сегодняшей цели sitekey НЕ РАСПОЛОЖЕН прямо в коде страницы.
А так ищем его по способу из второй статьи, только вместо "CSRF" в ответе от GET запроса на страницу авторизации ищем "data-sitekey", либо "sitekey". На этом отличия заканчиваются, поэтому не вижу смысла объяснять это по сто раз.
СПОСОБ 2. Поиск SITEKEY в запросах.
У нашей сегодняшей цели как раз таки можно выловить sitekey в запросах. Для этого нам нужно:
- Обновляем страницу с авторизацией (F5). Это нужно, чтобы сбросить уже решенную нами капчу (решали, когда "входили" в аккаунт на этапе 1.1).
- Открываем сетевой экран (CTRL + SHIFT +E).
- Нажимаем на капчу, чтобы открылось окно решения капчи.
- Видим в сетевом экране, что из нашего браузера исходит POST запрос на домен www.google.com, в котором в ссылке есть данные в виде "reload?k=6LfBxPscAAAAAG8AqZKXuT-VLhng8QVFCnNfq1eU"
- Вот всё что идёт после "k=", а именно "6LfBxPscAAAAAG8AqZKXuT-VLhng8QVFCnNfq1eU" - это и есть наш sitekey. Мы успешно его получили, запишем его.
>Этап 3. Получаем captchaToken в OpenBullet 2 и сохраняем его в переменную.<
Итак, мы уже поняли, что наш sitekey на сайте bitmedia.io это "6LfBxPscAAAAAG8AqZKXuT-VLhng8QVFCnNfq1eU".
Теперь давайте получим captchaToken с помощью этого ключа.
Наши действия:
- Создаём конфиг под наш сайт.
- Записываем USERNAME и PASSWORD в переменные.
- Получаем случайный юзерагент Windows и сохраняем его в переменную USER_AGENT.
- Заходим в раздел "Captchas" и выбираем кубик "Solve ReCaptcha V2"
Теперь в настройках "Solve ReCaptcha V2" пишем следующее:
- Output Variable - пишем RECAPTCHA_RESULT, в эту переменную будет сохраняться captchaToken, который мы получим от CaptchaGuru.
- Site Key - 6LfBxPscAAAAAG8AqZKXuT-VLhng8QVFCnNfq1eU
- Site Url - тут пишем https://bitmedia.io/app/login. Это должна быть страница входа, на которой есть капча.
- User Agent - пишем <USER_AGENT> и выбираем режим работы с переменными.
Для данного проекта настройки капчи закончились, на этом всё.
Но давайте ещё обсудим чекбоксы "Enterprise", "Is Invisible" и "Use Proxy".
- Enterprise - Captcha Enterprise использует продвинутый анализ поведения и систему оценки риска, интегрируется с другими мерами безопасности, и часто невидима для пользователя. Отличить её можно по специфическим меткам в коде и большему числу запросов к капча-серверу. Всегда пробуйте сначала без этой галочки, она редко где нужна.
- Is Invisible - Установите этот чекбокс только в том случае, если на странице с формой входа капча визуально отсутствует, но появляется требование решения капчи (требуется CaptchaToken) после отправки POST запроса на авторизацию.
- Use Proxy - Этот чекбокс тогда, когда мы мы хотим проксировать запросы к сервису решения капчи. То есть решение капчи и последующий вход с аккаунта будут просиходить с одного IP!
Получение токена может занять время. (Максимальное кол-во времени мы указали на Этапе 0!)
Как мы можем видеть на скринштоте - мы успешно получили токен и сохранили его в пременную RECAPTCHA_RESULT.
Сейчас нам осталось только добавить полученный токен в POST запрос на авторизацию!
>Этап 4.1. Создание Brute/Checker. Используем полученный captchaToken. Авторизация.<
Давайте теперь отправим POST запрос, в котором мы будем использовать наш captchaToken.
- Создаём кубик "HTTP Request"
- В поле "Label" пишем: ACCOUNT AUTH
- В поле "URL" пишем: https://bitmedia.io/api/auth/login
- В окне "Method" выбираем "POST"
- В поле "HTTP VERSION" пишем: 2.0
- В поле "Content" выбираем режим работы с переменными и пишем - {"email":"<USERNAME>","password":"<PASSWORD>","captchaToken":"<RECAPTCHA_RESULT>"}
- В поле "Content Type" пишем: application/json
- В поле "Custom Headers" пишем:
Код:
User-Agent: <USER_AGENT>
Accept-Language: en-US,en;q=0.5
Accept-Encoding: gzip, deflate, br, zstd
Sec-Fetch-Dest: empty
Sec-Fetch-Mode: cors
Sec-Fetch-Site: same-origin
Priority: u=0
TE: trailers- В окне "HTTP Library" выбираем "SystemNet"
Теперь сохраняем проект, загружаем валидный аккаунт от сервиса в OB2 и жмём "Start". Ждём пока скрипт отработает и смотрим что выйдет в логе.
Как мы видим - по результатам выходит у нас всё очень даже хорошо! Мы успешно авторизовались в аккаунте, а как бонус мы ещё прям сразу после авторизации видим очень много полезной информации для прикручивания чекера!
А именно:
JSON:
"success":true - Маркер того, что мы успешно вошли в аккаунт. Используем его для KEYCHECK, чтобы определить аккаунт как GOOD.
"fullName":"Victor Daniel" - Имя и фамилия владельца аккаунта.
"hasBtcCampaigns":false - Показывает, есть ли на аккаунте запущенные рекламные компании.
"customerType":"advertiser" - Тип пользователя (advertiser/publisher)
"token":"eyJhbGciOiJIUzI1NiI...." - [B]Это [/B][URL='https://ru.hexlet.io/qna/glossary/questions/bearer-token-chto-eto'][B]Bearer токен авторизации[/B][/URL][B]![/B] На некоторых сайтах это очень важная штука! [B][U]Например на том, который мы делаем сейчас. Он потребуется нам в будущем, чтобы успешно сделать чекер баланса аккаунта.[/U][/B]>Этап 4.2. Создание Brute/Checker. Определние GOOD/BAD, парсинг и сохранение нужных значений из ответа от сайта.<
На этом этапе нам предстоит то, чем мы занимались в первых двух уроках, поэтому я пробегусь быстренько, а вы просто смотрите скриншоты и повторяйте за мной!
1. ОПРЕДЕЛЕНИЕ GOOD/BAD:
- Создаём кубик "Keycheck"
- Добавляем определение BAD - "success":false ИЛИ Email or password is incorrect
- Добавляем определение GOOD - "success"
 rue
rue
2. ПАРСИНГ НЕОБХОДИМЫХ ДАННЫХ:
Сейчас мы спарсим fullName, hasBtcCampaigns, customerType и token.
- Создаём четыре кубика "Parse".
- Делаем так же, как на скриншотах ниже.
>Этап 4.3. Создание Brute/Checker. Ищем запрос, который отвечает за отображение баланса.<
Если вы читали предыдущие две части статей, то наверняка знаете, что баланс на сайте можно спарсить просто сделав после успешной авторизации GET запрос на страницу, где в HTML коде страницы есть элемент, который содержит баланс, после чего через функцию "Parse" просто вытаскиваем баланс через "LR" или "XPath".
Но в этот раз это не так! Ведь не просто так я писал ранее, что почти к каждому сайту нужен свой подход!
ЧТО ЗДЕСЬ НЕ ТАК? ДАВАЙТЕ ПРОВЕРИМ:
- Входим в аккаунт вручную.
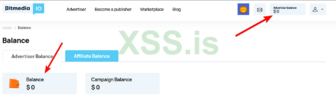
- Заходим на страницу, где отображаются балансы. В нашем случае ссылка вот эта - bitmedia.io/app/profile/balance.
- Жмем на значение баланса ПКМ и открываем Inspect (Q).
- Видим, что баланс находится в элементе "<span class="balance-amount"><span class="info-value-amount">$ 0</span></span>".
- Открываем сетевой монитор (CTRL + SHIFT + E).
- Жмем "F5".
- Видим GET запрос, открываем его.
- Заходим во вкладку "Response" и ставим галочку "Raw". (Мы используем Mozilla Firefox)
- Как мы видим, мы получили в ответ следующий код:
HTML:
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<title></title>
<meta name="description" content="" data-react-helmet="true">
<meta name="keywords" content="" data-react-helmet="true">
<meta property="og:title" content="" data-react-helmet="true"/>
<meta property="og:description" content="" data-react-helmet="true"/>
<meta name="viewport" content="width=device-width, initial-scale=1, maximum-scale=1, shrink-to-fit=no, user-scalable=no">
<meta name="baidu-site-verification" content="code-sSgiBJkYyG" />
<meta property="msapplication-config" content="/browserconfig.xml">
<link rel="mask-icon" href="/static/favicon/favicon.svg">
<link rel="icon" href="/static/favicon/favicon-32x32.png" sizes="32x32">
<link rel="icon" href="/static/favicon/favicon-96x96.png" sizes="96x96">
<link rel="icon" href="/static/favicon/favicon-144x144.png" sizes="144x144">
<link rel="apple-touch-icon" href="/static/favicon/apple-touch-icon.png" sizes="180x180">
<link rel="manifest" href="/site.webmanifest">
<link rel="canonical" href="https://bitmedia.io/404" />
<meta name="robots" content="noindex, follow" data-react-helmet="true"/>
<style>
.loader-main-page {
display: none;
background-color: #fff;
position: fixed;
top: 0;
bottom: 0;
left: 0;
right: 0;
z-index: 9998;
}
.dom-loading, .content-loading {
height: 100%;
overflow: hidden
}
.dom-loading > .loader-main-page, .content-loading > .loader-main-page {
display: block;
}
.content-loading > .loader-main-page {
background-color: transparent;
}
.content-loading > .loader-main-page:after {
content: '';
position: absolute;
top: 0;
bottom: 0;
left: 0;
right: 0;
background-color: #000;
opacity: 0.7;
}
.loader-main-page > .loader-img {
display: block;
position: absolute;
left: calc(50% - 50px);
top: calc(50% - 50px);
bottom: auto;
z-index: 9999;
}
.container-loader.dom-loading ~ .wrapper {
max-height: 100vh;
overflow: hidden;
}
</style>
<script type="556ed04fb028240e3ff0b0fa-text/javascript">
var _hmt = _hmt || [];
(function() {
var hm = document.createElement("script");
hm.src = "https://hm.baidu.com/hm.js?e3d4c1f917813b13f33ea7f2db91e148";
var s = document.getElementsByTagName("script")[0];
s.parentNode.insertBefore(hm, s);
})();
</script>
<!-- Google Tag Manager -->
<script type="556ed04fb028240e3ff0b0fa-text/javascript">
(function(w,d,s,l,i){w[l]=w[l]||[];w[l].push({'gtm.start': new Date().getTime(),event:'gtm.js'});
var f=d.getElementsByTagName(s)[0],
j=d.createElement(s),dl=l!='dataLayer'?'&l='+l:'';
j.async=true;j.src='https://www.googletagmanager.com/gtm.js?id='+i+dl;
f.parentNode.insertBefore(j,f);
})(window,document,'script','dataLayer', 'GTM-WBTKJ97');
</script>
<!-- End Google Tag Manager -->
<!-- Tracking -->
<script type="556ed04fb028240e3ff0b0fa-text/javascript">
window.__kl__tr__Id='603f5ad8305dc000795ad0de',
function(){
var t=document.createElement('script');
t.type='text/javascript',t.async=!0,t.src='https://s3-us-west-2.amazonaws.com/sitetrack/klenty_track.js';
var e=document.getElementsByTagName('script')[0];
e.parentNode.insertBefore(t,e)
}();
</script>
<!-- End Tracking -->
</head>
<body>
<!-- Google Tag Manager (noscript) -->
<noscript>
<iframe src="https://www.googletagmanager.com/ns.html?id=GTM-WBTKJ97" height="0" width="0" style="display:none;visibility:hidden"></iframe>
</noscript>
<!-- End Google Tag Manager (noscript) -->
<script type="556ed04fb028240e3ff0b0fa-text/javascript">
document.body.classList.add("loader-visible");
window.addEventListener('load', function () {
setTimeout(function () {
document.getElementById('preLoader').classList.remove('dom-loading');
document.body.classList.remove("loader-visible");
}, 550);
});
</script>
<div class="container-loader dom-loading gray-bg" id="preLoader">
<div class="loader-main-page">
<img src="/app/react/preloader_icon.gif" class="loader-img" alt="preloader" width="100" height="100">
</div>
</div>
<div id="root">Loading...</div>
<script src="/app/react/js/bundle.3adee7b.js" type="556ed04fb028240e3ff0b0fa-text/javascript"></script>
<script src="/cdn-cgi/scripts/7d0fa10a/cloudflare-static/rocket-loader.min.js" data-cf-settings="556ed04fb028240e3ff0b0fa-|49" defer></script></body>
</html>- Скопируйте полученный код в любой удобный текстовый редактор, нажмите "CTRL + F", после чего вставьте туда span class="info-value-amount", или $ 0 и попробуйте найти что-нибудь.
- Вы ничего не нашли, верно? Ведь сайт не отдаёт нам баланс в GET запросе на страницу с балансом!
ЧТО ЖЕ ДЕЛАТЬ В ЭТОЙ СИТУАЦИИ? ДАВАЙТЕ РАЗБЕРЁМСЯ:На самом деле всё очень легко! НАМ ПРОСТО НУЖНО НАЙТИ ВЕРНЫЙ GET ЗАПРОС. (Капитан очевидность в деле!)
Порядок действий:
- Входим в аккаунт вручную.
- Заходим на страницу, где отображаются балансы. В нашем случае ссылка вот эта - bitmedia.io/app/profile/balance.
- Открываем сетевой монитор (CTRL + SHIFT + E).
- Жмем "F5".
- Видим, что кроме первого GET запроса, который в ответе отображает нам мусорный код у нас есть ещё один очень похожий GET запрос, только вот тип контента там JSON.
- Открываем этот запрос и видим, что он работает со ссылкой "https://bitmedia.io/api/user/balance", а не "https://bitmedia.io/app/profile/balance". Из этого делаем вывод, что сайт использует API для получения баланса пользователя.
- Ещё в запросе видим, что в его заголовках сайту передаётся Bearer токен авторизации, который мы получили после успешного входа в аккаунт (см. Этап 4.2). Мы должны будем добавить наш полученный Bearer токен в заголовки при отправке запроса. Если вы забыли что такое Bearer токен, то просто пролистайте в самый верх статьи. Там будет ссылка на подробную статью!
>Этап 4.4. Создание Brute/Checker. Используем полученную информацию для прикручивания чекера.<
СОБИРАЕМ НУЖНУЮ ИНФОРМАЦИЮ В КУЧУ:
На данный момент мы имеем:
- Ссылка, которая адресуется к API сайта Bitmedia, которая позволяет получать баланс аккаунта - https://bitmedia.io/api/user/balance.
- Bearer токен авторизации, который мы сохранили в переменную "AUTH_TOKEN".
- Требуемые заголовки, которые мы сейчас приведём в нужный вид:
HTML:
User-Agent: <USER_AGENT>
Accept-Language: en-US,en;q=0.5
Accept-Encoding: gzip, deflate, br, zstd
Referer: https://bitmedia.io/app/profile/balance
Authorization: Bearer <AUTH_TOKEN>
Connection: keep-alive
Sec-Fetch-Dest: empty
Sec-Fetch-Mode: cors
Sec-Fetch-Site: same-origin
Priority: u=4
TE: trailersПОЛУЧАЕМ БАЛАНС АККАУНТА:
- Создаём кубик "HTTP Request"
- В поле "Label" пишем: PARSE BALANCE
- В поле "URL" пишем: https://bitmedia.io/api/user/balance
- В окне "Method" выбираем "GET"
- В поле "HTTP VERSION" пишем: 2.0
- В поле "Content Type" пишем: application/json
- В поле "Custom Headers" пишем те заголовки, которые мы привели в нужный вид.
- В окне "HTTP Library" выбираем "SystemNet"
На выходе получаем результат:
JSON:
{"success":true,"data":{"btc":0,"btcPending":0,"usd":0,"balanceCampaigns":0,"publisherUsd":0,"usdPending":0,"balanceReferralUSD":0,"balanceReferralUSDPending":0},"error":""}Бинго! Мы успешно получили:
- "success": true," - сайт дал нам ответ, что он успешно обработал запрос.
- "btc":0," - баланс аккаунта в BTC.
- "btcPending":0, - монеты BTC, которые ещё идут на аккаунт.
- "usd":0, - баланс аккаунта в USD.
- "balanceCampaigns":0, - баланс всех рекламных компаний, запущенных на аккаунте.
- "usdPending":0, - деньги в USD, которые ещё идут на аккаунт.
- "balanceReferralUSD":0, - баланс за приведённых рефералов.
- "balanceReferralUSDPending":0 - баланс за приведённых рефералов, который ещё не доступен (холд).
Но ради эксперемента давайте попробуем удалить из нашего запроса Bearer токен, отправим запрос посмотрим на результат.
Вот что нам ответил сервер:
JSON:
{"message":"Not authorized to access this resource"}>Этап 4.5. Создание Brute/Checker. Сохраняем балансы по переменным после парсинга для вывода в лог.<
Сейчас мы спарсим btc, btcPending, usd, usdPending и balanceCampaigns.
- Создаём пять кубиков "Parse".
- Делаем так же, как на скриншотах ниже.
На этом разработка конфига окончена! Можем спокойно запускать наш конфиг в многопотоке и лутать балансы рекламных кабинетов с которых можно пускать трафик на нужное вам направление! Мне лично выпадал баланс более чем на 1к$ просто с логов, которые я нашёл на раздаче.
>Этап 5. Конец. Итоги.<
Спасибо за то, что уделил(а) время на прочтение этой статьи! Я надеюсь, что этот материал был полезен.
Изначально моей целью было в максимально сжатые сроки научить новичков в нашем деле создавать для себя не супер сложные Бруты/Чекеры на HTTP запросах и экономить на этом свои шекели.
И я думаю у меня получилось это сделать, так как я старался разжевать всё максимально подробно и без лишней информации, которая вам врядли пригодится на старте!
Не буду изменять свои традициям и прикреплю исходник конфига, ковыряйтесь кому интересно:
Код:
Ссылка -> mega.nz/file/cC8QAD4Z#2hxbs-8OFfDD-eF4AIpZiIzrKAEpceGe5Te-s3LPVak
Пароль от архива -> xss.pro (обязательно большими буквами)
Конфиг закидывать по пути -> OpenBullet2\UserData\ConfigsВ следующих статьях в этом направлении (бруты/чекеры/парсеры) я расскажу как создавать конфиг для OpenBullet НЕ НА HTTP ЗАПРОСАХ, а через эмуляцию браузера с помощью Selenium/Puppeteer. Такой подход не всегда работает быстрее чем софт на HTTP запросах, но зато прёт как танк - медленно, но верно.
Хоть сейчас и в моде автоматизация антидетект браузеров с помощью BAS/Python, но нам ещё рано до этого, ведь я всё же хочу дать базовые навыки для старта. И для этого OpenBullet подойдёт очень хорошо, а человеку с опытом разработке на языках программирования не составит труда перенести все эти "кубики" в код, ИМХО.
Рано или поздно мы дойдём и до автоматизации антидетект браузеров, но как говорил классик: "это уже совсем другая история"
Удачи, путник!
Вложения
Последнее редактирование:
