автор Andrey_Biryukov
Статья подготовлена в рамках онлайн-курса «Внедрение и работа в DevSecOps».
Понятие DevSecOps (как, впрочем, и DevOps) до сих пор трактуют весьма широко, кто-то считает, что направление в разработке ПО, кто-то считает, что такой специалист «на все руки». Но, пожалуй, наиболее подходящим в контексте этой статьи будет следующее определение DevSecOps — это практика интеграции тестирования безопасности в каждый этап процесса разработки программного обеспечения. Отсюда можно сделать вывод, что и разработчики и тестировщики должны быть знакомы с базовыми уязвимостями, которые можно встретить в коде.
Однако, для того, чтобы лучше проникнуться тем, к чему могут привести уязвимости в программном обеспечении, я предлагаю не ограничиваться только поверхностным «общим» описанием того, как в принципе работает та или иная уязвимость, а пройти полный путь от выявления уязвимости до ее полноценной эксплуатации – запуска калькулятора в контексте уязвимой программы. В качестве примера такой уязвимости мы будем рассматривать переполнение буфера. В первой статье мы напишем уязвимую программу, правильно ее откомпилируем и поищем в ней уязвимости. Во второй статье мы проэксплуатируем найденную уязвимость, попутно разобрав все нюансы и подводные камни. В третьей статье мы поговорим о том, как можно выявлять уязвимости в исходном коде. При этом, так как та же уязвимость переполнения буфера «интернациональна», то есть и в Linux и в Windows, то первые две статьи мы посвятим разбору уязвимости в приложении под Windows 10, а в третьей статье будем рассматривать санитайзеры, работающие под Linux.
И наконец, отладчик. Я буду использовать x64dbg (32-битную редакцию), хотя здесь можно было бы воспользоваться и старым добрым OllyDebug.
Все приведенные далее манипуляции я проводил на своей хостовой машине, то есть виртуализация не требуется, ничего вредоносного, равно как и нарушающего статьи УК мы делать не собираемся.
Как видно во второй строке мы объявили буфер размером в 600 байт, а в следующей строке мы копируем данные из аргумента, переданного в командной строке в этот буфер. В случае, если пользователь передаст более 600 байт, произойдет затирание памяти и программа “упадет”.
Откомпилируем этот код:
Далее мы на время забудем, о том, что мы знаем об использовании небезопасной команды strcpy и будем искать уязвимости в откомпилированном файле методом черного ящика, то есть без доступа к исходному коду.
Для начала посмотрим, как программа реагирует на корректный ввод:

Далее можно пойти двумя путями. Можно написать скрипт, который будет побайтово увеличивая массив передаваемых данных запускать программу, наблюдая на каком шаге она упадет. Но это долго. А можно сразу подать на вход большой объем данных и посмотреть, что будет.
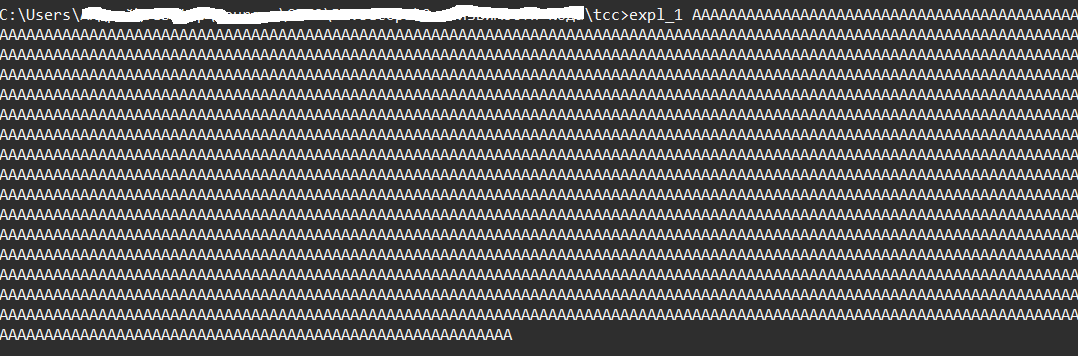
Передадим порядка килобайта данных, и программа не выводит Input:, значит она аварийно завершила работу.
Для дальнейших действий нам потребуется отладчик.
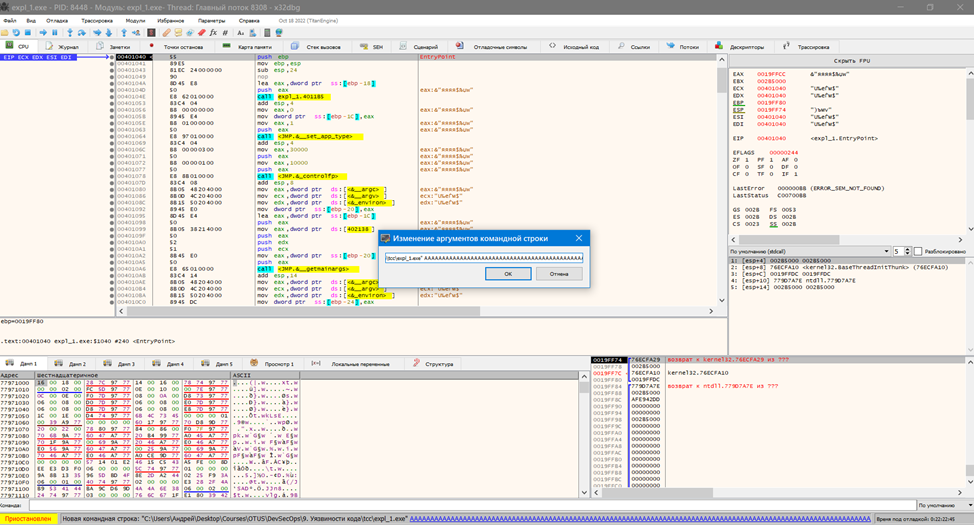
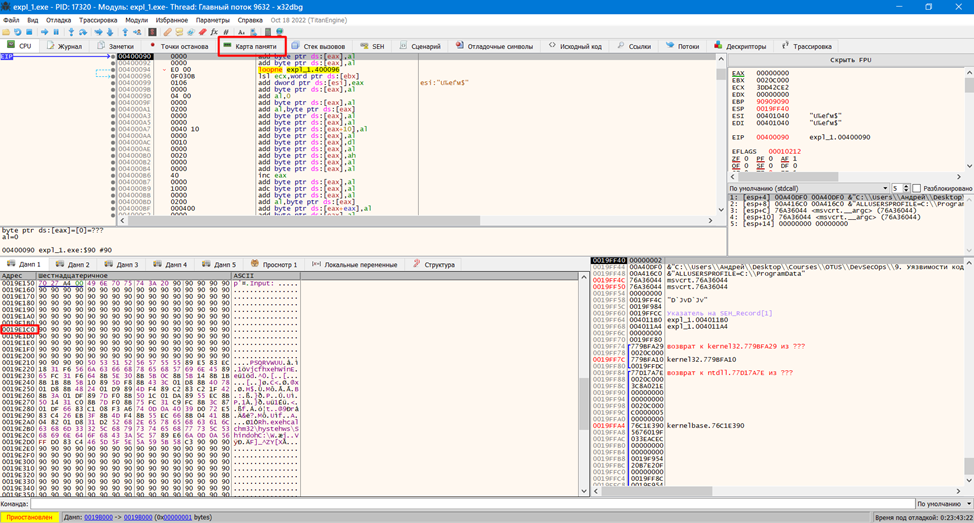
Далее нажимаем Выполнить, отладчик останавливается в состоянии Первая попытка исключения на 0x41414141. Также 0x41 должен быть в значении регистра EIP.
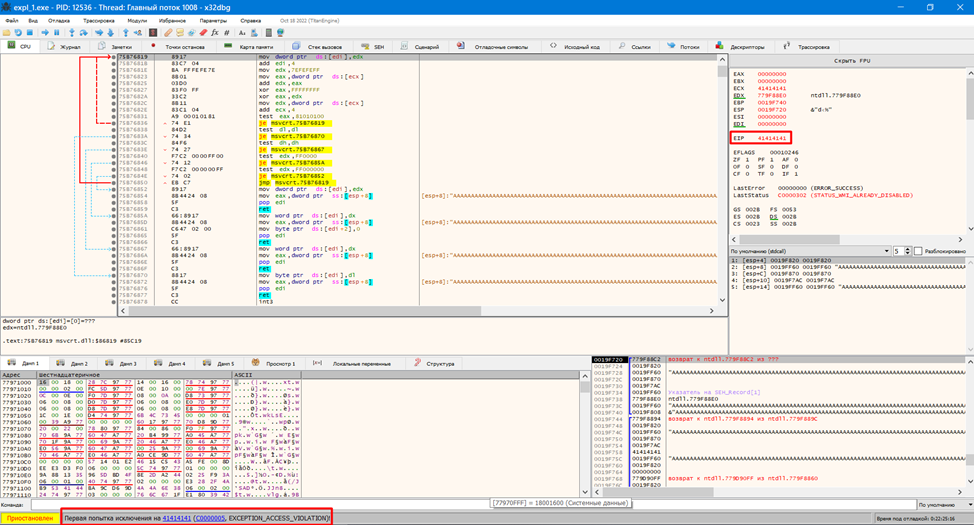
Если отладчик остановился на других значениях, следует выполнить Отладка -> Расширенный -> Выполнить (проглотить исключение).
Что же мы в итоге получили? Переданный нами массив данных затер значение регистра EIP. Данный регистр (Instruction Pointer) содержит адрес следующей машинной команды. То есть, вместо того, чтобы после копирования нашего буфера перейти к выполнению команды по следующему, корректному адресу, программа перейдет по адресу 0x41414141 (0x41 это код буквы А), который естественно корректным не является.
Теперь нам важно узнать, на каком именно объеме данных программа падает. Это нужно для того, чтобы впоследствии мы могли поместить в этот блок наш эксплоит. Здесь самый простой способ это подготовить специальную сигнатуру, которую скормить программе и посмотреть, какие именно байты затрут значение EIP.
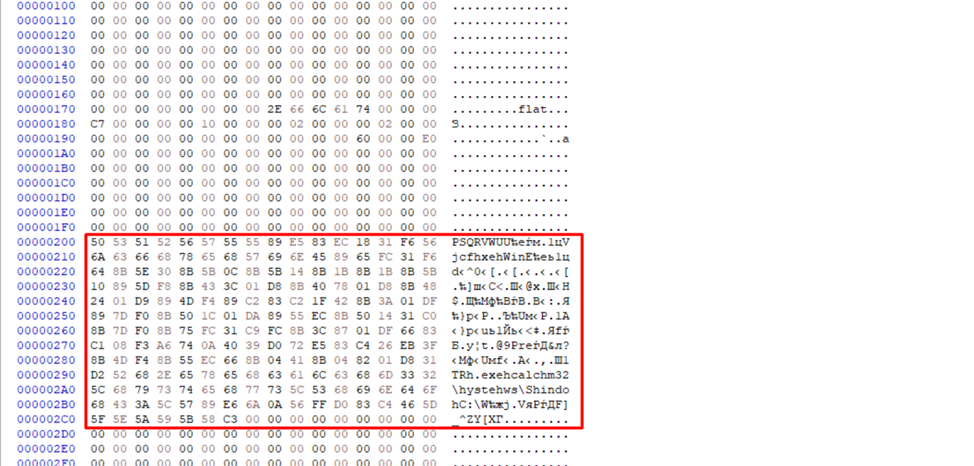
У меня для этих целей сгенерирован следующий паттерн.

В нем 1024 байта и как видно символы представлены блоками по четыре байта, где первая буква всегда заглавная. Передадим этот массив в отладчике нашей уязвимой программе и запустим ее.
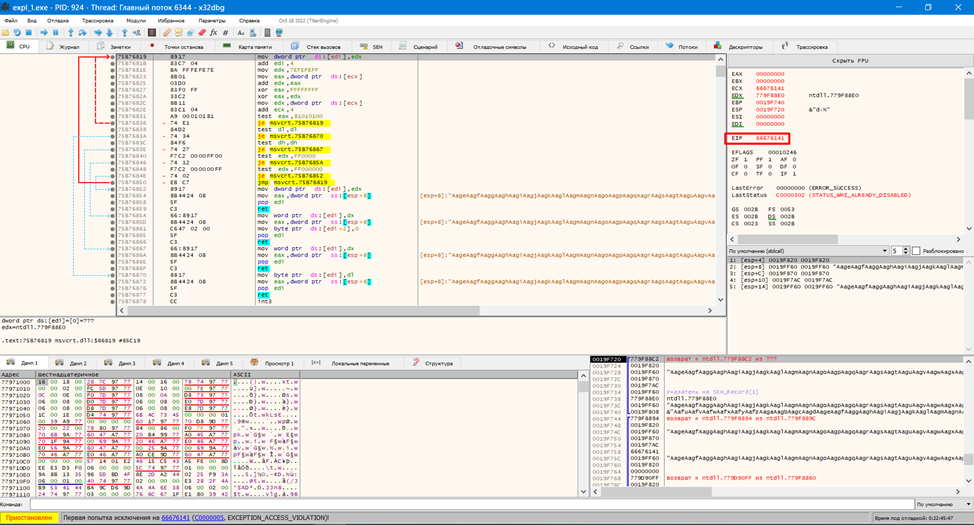
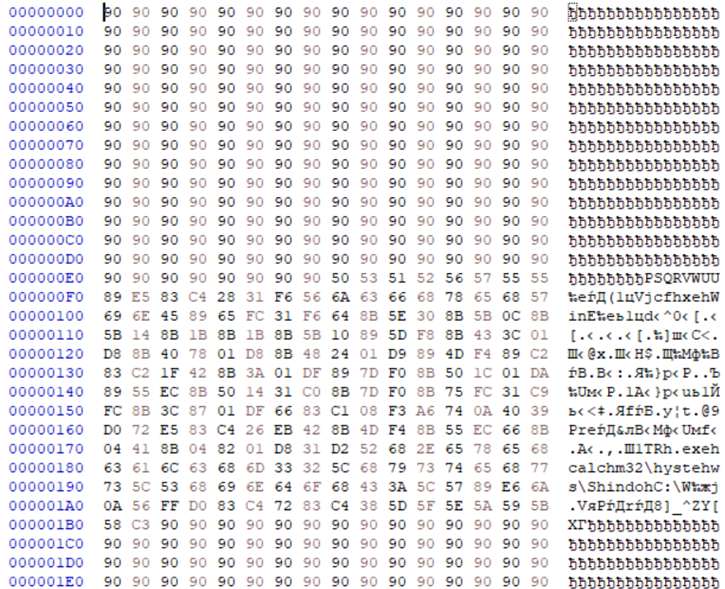
Теперь в EIP записалось значение 0x66676141 или fgaA. Здесь самое об обратном порядке записи в памяти и обратить полученный набор байт – Aagf. То есть, для того, чтобы вызвать переполнение буфера нам необходимо передать уязвимой программе более 644 байт. Запомним это число, оно нам еще пригодится в следующей статье, где мы будем эксплуатировать найденную сейчас уязвимость.
Статья подготовлена в рамках онлайн-курса «Внедрение и работа в DevSecOps».
Понятие DevSecOps (как, впрочем, и DevOps) до сих пор трактуют весьма широко, кто-то считает, что направление в разработке ПО, кто-то считает, что такой специалист «на все руки». Но, пожалуй, наиболее подходящим в контексте этой статьи будет следующее определение DevSecOps — это практика интеграции тестирования безопасности в каждый этап процесса разработки программного обеспечения. Отсюда можно сделать вывод, что и разработчики и тестировщики должны быть знакомы с базовыми уязвимостями, которые можно встретить в коде.
Однако, для того, чтобы лучше проникнуться тем, к чему могут привести уязвимости в программном обеспечении, я предлагаю не ограничиваться только поверхностным «общим» описанием того, как в принципе работает та или иная уязвимость, а пройти полный путь от выявления уязвимости до ее полноценной эксплуатации – запуска калькулятора в контексте уязвимой программы. В качестве примера такой уязвимости мы будем рассматривать переполнение буфера. В первой статье мы напишем уязвимую программу, правильно ее откомпилируем и поищем в ней уязвимости. Во второй статье мы проэксплуатируем найденную уязвимость, попутно разобрав все нюансы и подводные камни. В третьей статье мы поговорим о том, как можно выявлять уязвимости в исходном коде. При этом, так как та же уязвимость переполнения буфера «интернациональна», то есть и в Linux и в Windows, то первые две статьи мы посвятим разбору уязвимости в приложении под Windows 10, а в третьей статье будем рассматривать санитайзеры, работающие под Linux.
Что нам потребуется
В качестве среды разработки я не буду использовать громоздкие инструменты типа MS Visual Studio. Вместо этого в качестве компилятора кода на С у нас будет выступать крошечный компилятор Tiny C Compiler (https://bellard.org/tcc/). Для правки двоичных файлов нам потребуется редактор, я буду использовать HxD, хотя многие скорее всего предпочтут Hiew.И наконец, отладчик. Я буду использовать x64dbg (32-битную редакцию), хотя здесь можно было бы воспользоваться и старым добрым OllyDebug.
Все приведенные далее манипуляции я проводил на своей хостовой машине, то есть виртуализация не требуется, ничего вредоносного, равно как и нарушающего статьи УК мы делать не собираемся.
Дырявый код
В качестве уязвимой программы у нас выступит следующий код:
Код:
int main(int argc, char* argv[]) {
char buffer[600]; //Объявляем 600 байтовый буффер
strcpy(buffer, argv[1]); //Копируем в буффер 1 аргумент
printf("Input: %s\n", buffer);
return 0; }Откомпилируем этот код:
Код:
tcc expl_1.cНемного фаззинга пожалуйста
Для того, чтобы выявить уязвимости в программе мы прибегнем к методам фаззинга. Вообще фаззинг это методика тестирования, при которой на вход программы подаются невалидные, непредусмотренные или случайные данные. В нашем случае мы будем подавать данные большого объема, наблюдая за реакцией программы.Для начала посмотрим, как программа реагирует на корректный ввод:
Далее можно пойти двумя путями. Можно написать скрипт, который будет побайтово увеличивая массив передаваемых данных запускать программу, наблюдая на каком шаге она упадет. Но это долго. А можно сразу подать на вход большой объем данных и посмотреть, что будет.
Передадим порядка килобайта данных, и программа не выводит Input:, значит она аварийно завершила работу.
Для дальнейших действий нам потребуется отладчик.
Осторожно ассемблер!
Откроем наш выполнимый файл в x64dbg. Увидим много непонятных команд, о которых мы подробно будем говорить в следующей статье. Сейчас нам необходимо подать на вход отладчику наш большой набор байт. Для этого выбираем Файл -> Изменение аргументов командной строки и добавляем наш массив байт.
Далее нажимаем Выполнить, отладчик останавливается в состоянии Первая попытка исключения на 0x41414141. Также 0x41 должен быть в значении регистра EIP.
Если отладчик остановился на других значениях, следует выполнить Отладка -> Расширенный -> Выполнить (проглотить исключение).
Что же мы в итоге получили? Переданный нами массив данных затер значение регистра EIP. Данный регистр (Instruction Pointer) содержит адрес следующей машинной команды. То есть, вместо того, чтобы после копирования нашего буфера перейти к выполнению команды по следующему, корректному адресу, программа перейдет по адресу 0x41414141 (0x41 это код буквы А), который естественно корректным не является.
Теперь нам важно узнать, на каком именно объеме данных программа падает. Это нужно для того, чтобы впоследствии мы могли поместить в этот блок наш эксплоит. Здесь самый простой способ это подготовить специальную сигнатуру, которую скормить программе и посмотреть, какие именно байты затрут значение EIP.
У меня для этих целей сгенерирован следующий паттерн.
В нем 1024 байта и как видно символы представлены блоками по четыре байта, где первая буква всегда заглавная. Передадим этот массив в отладчике нашей уязвимой программе и запустим ее.
Теперь в EIP записалось значение 0x66676141 или fgaA. Здесь самое об обратном порядке записи в памяти и обратить полученный набор байт – Aagf. То есть, для того, чтобы вызвать переполнение буфера нам необходимо передать уязвимой программе более 644 байт. Запомним это число, оно нам еще пригодится в следующей статье, где мы будем эксплуатировать найденную сейчас уязвимость.