ОРИГИНАЛЬНАЯ СТАТЬЯ
ПЕРЕВЕДЕНО СПЕЦИАЛЬНО ДЛЯ xss.pro
$600 на SSD для Jolah Milovski ---> 0x5B1f2Ac9cF5616D9d7F1819d1519912e85eb5C09 для поднятия ноды ETHEREUM и тестов
Сегодня мы вернёмся к конвейеру компилятора и расширим некоторые понятия, о которых мы говорили, такие как байткод V8, компиляция кода и оптимизация кода. В целом, в этом посте мы глубоко погрузимся в понимание того, что происходит под капотом в Ignition, Sparkplug и TurboFan, поскольку они имеют решающее значение для нашего понимания того, как определенные "особенности" могут привести к эксплуатируемым ошибкам.
Будут рассмотрены следующие темы:
Модель безопасности Chrome
Архитектура многопроцессной песочницы
Изоляция и контекст в V8
Интерпретатор Ignition
Понимание байткода V8
Понимание машины на основе регистров
Sparkplug
Сопоставление 1:1
TurboFan
Компиляция точно в срок (JIT)
Спекулятивная оптимизация и защита типов
Решетка обратной связи
"Море узлов" Промежуточное представление (IR)
Общие оптимизации
Типизатор
Анализ диапазона
Устранение проверки границ (BCE)
Устранение избыточности
Другие оптимизации
Оптимизация управления
Анализ псевдонимов и нумерация глобальных значений
Устранение мертвого кода (DCE)
Общие уязвимости JIT-компилятора
Модель безопасности Chrome
Прежде чем мы погрузимся в понимание сложности конвейера компилятора, того, как он выполняет оптимизацию и где могут появляться ошибки, нам сначала нужно сделать шаг назад и посмотреть на общую картину. Хотя конвейер компилятора играет большую роль в выполнении JavaScript, он является лишь одним из кусочков головоломки в целой архитектуре браузеров.
Как мы уже видели, V8 может работать как отдельное приложение, но когда речь идет о браузере в целом, V8 фактически встроен в Chrome и затем используется через привязки другим движком. В связи с этим существуют нюансы и определенные последствия, о которых мы должны знать, как обрабатывается код JavaScript в приложении, поскольку эта информация имеет решающее значение для понимания проблем безопасности в браузере.
Чтобы увидеть эту "общую картину" и собрать воедино все части головоломки, нам нужно начать с понимания модели безопасности Chrome. Эта серия статей в блоге - путешествие по внутренностям и эксплуатации браузера, в конце концов. Итак, чтобы лучше понять, почему некоторые ошибки более тривиальны, чем другие, и почему эксплуатация только одной ошибки может не привести к прямому удаленному выполнению кода, нам нужно понять архитектуру Chromium.
Как мы знаем, JavaScript-движки являются неотъемлемой частью выполнения JavaScript-кода на системах. Хотя они играют большую роль в обеспечении быстродействия и эффективности браузеров, они также могут открывать браузер для сбоев, зависаний приложений и даже угроз безопасности. Но JavaScript-движки - не единственная часть браузера, которая может иметь проблемы или уязвимости. Многие другие компоненты, такие как API или используемые движки рендеринга HTML и CSS, также могут иметь проблемы со стабильностью и уязвимости, которые потенциально могут быть использованы - намеренно или нет. Сейчас практически невозможно создать JavaScript или движок рендеринга, который никогда не даст сбой. И также практически невозможно создать такие движки, которые были бы надежно защищены от ошибок и уязвимостей - особенно потому, что большинство этих компонентов программируются на статически типизированном языке C++, который должен справляться с динамической природой веб-приложений.Как же Chrome справляется с такой "невыполнимой" задачей, пытаясь поддерживать эффективную работу браузера и одновременно обеспечивая безопасность браузера, системы и пользователей? Двумя способами - с помощью многопроцессной архитектуры и "песочницы".
Многопроцессная архитектура песочницы
Многопроцессная архитектура Chromium - это именно такая архитектура, которая использует несколько процессов для защиты браузера от проблем нестабильности и ошибок, которые могут возникнуть в JavaScript-движке, движке рендеринга или других компонентах. Chromium также ограничивает доступ между каждым из этих процессов, позволяя только определенным процессам общаться друг с другом. Этот тип архитектуры можно рассматривать как включение защиты памяти и контроля доступа в приложение. В целом, браузеры имеют один основной процесс, который запускает пользовательский интерфейс и управляет всеми остальными процессами - он известен как "процесс браузера" или сокращенно "браузер". Очень уникально, я знаю. Процессы, которые обрабатывают веб-контент, известны как "процессы рендеринга" или "рендереры". Эти процессы рендеринга используют нечто под названием Blink - это движок рендеринга с открытым исходным кодом, используемый в Chrome. В Blink реализовано множество других библиотек, которые помогают ему работать, например, Skia, которая является открытой библиотекой 2D графики, и, конечно же, V8 для JavaScript. И вот здесь все становится немного сложнее. В Chrome каждое новое окно или вкладка открывается в новом процессе, который обычно является новым процессом рендеринга. Этот новый процесс рендеринга имеет глобальный объект RenderProcess, который управляет связью с родительским процессом браузера и поддерживает глобальное состояние веб-страницы или приложения в этом окне или вкладке. В свою очередь, главный процесс браузера будет поддерживать соответствующий объект RenderProcessHost для каждого рендерера, который управляет состоянием браузера и коммуникацией для рендерера. Для связи между каждым из этих процессов Chromium использует либо унаследованную систему IPC, либо Mojo.

Помимо того, что каждый из этих рендереров находится в собственном процессе, Chrome также использует возможность ограничить доступ процессов к системным ресурсам с помощью "песочницы". Создавая "песочницу" для каждого процесса, Chrome может гарантировать, что доступ к сетевым ресурсам рендерера будет осуществляться только через диспетчер сетевых служб, запущенный в основном процессе. Кроме того, он может ограничить доступ процессов к файловой системе, а также к дисплею пользователя, файлам cookie и вводимым данным.
В целом, это ограничивает возможности злоумышленника, если он получит удаленное выполнение кода в процессе рендеринга. По сути, они не смогут внести постоянные изменения в компьютер или получить доступ к такой информации, как пользовательский ввод и cookies в других окнах и вкладках без использования или цепочки других ошибок для выхода из этой песочницы.
Я не буду вдаваться в подробности, поскольку это отвлечет от текущей темы статьи в блоге. Но я настоятельно рекомендую вам подробно ознакомиться с документацией "Chromium Windows Sandbox Architecture", чтобы не только понять принципы проектирования, но и лучше понять схему взаимодействия брокера и целевого процесса.
Как же это выглядит на практике? Мы можем увидеть практический пример этого, запустив Chrome, открыв две вкладки и запустив Process Monitor. Сначала мы увидим, что в Chrome есть один родительский или "браузерный" процесс и несколько дочерних процессов, как показано ниже.

Теперь, если мы заглянем в основной родительский процесс и сравним его с дочерним процессом, мы заметим, что другие процессы выполняются с другими параметрами командной строки. В этом примере мы видим, что дочерний процесс (справа) относится к типу средства визуализации и соответствует родительскому процессу браузера (слева). Круто, правда?

Хорошо, после всего этого я знаю, что вы можете спросить меня, какое отношение все это имеет к V8 и JavaScript? Ну, если вы были внимательны, то заметили ключевой момент, когда я говорил о движке рендеринга Chromes, Blink. И это тот факт, что он реализует V8. Если вы нашли время прочитать документацию по Blink, то вы бы узнали немного о Blink. В документации говорится, что Blink запускается в каждом процессе рендеринга и имеет один основной поток, который обрабатывает JavaScript, DOM, CSS, вычисления стилей и макетов. Кроме того, Blink может создавать несколько "рабочих" потоков для запуска дополнительных скриптов, расширений и т.д. В целом, каждый поток Blink запускает свой собственный экземпляр V8. Почему? Как вы знаете, в отдельном окне браузера или вкладке может выполняться множество JavaScript-кода, причем не только для страницы, но и в различных iframe для таких вещей, как реклама, кнопки и т.д. В конце концов, каждый из этих скриптов и iframe имеют отдельные контексты JavaScript, и должен быть способ предотвратить манипуляции одного скрипта с объектами другого. Чтобы помочь "изолировать" контекст одного скрипта от другого, в V8 реализовано нечто известное как Isolate and Context, о чем мы сейчас и поговорим.
Изоляция и контекст в V8
В V8 Isolate - это просто концепция экземпляра или "виртуальной машины", которая представляет одну среду выполнения JavaScript, включая менеджер кучи, сборщик мусора и т.д. В Blink изоляты и потоки имеют соотношение 1:1, где один изолят связан с главным потоком, а один изолят связан с одним рабочим потоком. Итак, Context соответствует глобальному корневому объекту, который хранит состояние виртуальной машины и используется для компиляции и выполнения сценариев в одном экземпляре V8. Грубо говоря, один объект окна соответствует одному контексту, а поскольку каждый кадр имеет объект окна, в процессе рендеринга потенциально существует несколько контекстов. По отношению к изоляту, изолят и контексты имеют отношения 1:N на протяжении всего времени существования изолята - когда конкретный изолят или экземпляр будет интерпретировать и компилировать несколько контекстов. Это означает, что каждый раз, когда необходимо выполнить JavaScript, мы должны убедиться, что находимся в правильном контексте с помощью GetCurrentContext(), иначе произойдет утечка объектов JavaScript или их перезапись, что потенциально может вызвать проблемы безопасности. В Chrome объект времени выполнения v8::Isolate реализован в v8/include/v8-isolate.h, а объект v8::Context - в v8/include/v8-context.h. Используя то, что мы знаем, на высоком уровне мы можем представить себе согласованность времени выполнения и контекста в Chrome следующим образом:

Если вы хотите узнать больше о том, как работают эти Isolates и Context, то советую прочитать "Design of V8 Bindings" и "Getting Started with Embedding V8".
Интерпретатор Ignition
Теперь, когда мы имеем общее представление об архитектуре Chromium и понимаем, что весь код JavaScript не выполняется в одном и том же экземпляре движка V8, мы можем, наконец, вернуться к конвейеру компилятора и продолжить наше глубокое погружение.
Мы начнем с интерпретатора V8, Ignition.
В качестве напоминания о первой части, давайте вернемся к нашему высокоуровневому обзору конвейера компиляции V8, чтобы знать, где мы находимся в этом конвейере.

В первой части мы уже рассмотрели токены и абстрактные синтаксические деревья (AST), а также кратко объяснили, как AST разбирается и затем переводится в байткод в интерпретаторе. Теперь я хочу рассказать о байткоде V8, поскольку байткод, создаваемый интерпретатором, является важнейшим строительным блоком, из которого состоит любая функциональность JavaScript. Кроме того, когда Ignition компилирует байткод, он также собирает данные профилирования и обратной связи каждый раз, когда выполняется функция JavaScript. Эти данные обратной связи затем используются TurboFan для генерации JIT-оптимизированного машинного кода. Но прежде чем мы начнем понимать, как структурирован байткод, нам нужно сначала понять, как Ignition реализует свою "регистровую машину". Причина в том, что каждый байткод определяет свои входы и выходы как операнды регистра, поэтому нам нужно знать, где эти входы и выходы будут находиться в стеке. Это также поможет нам в дальнейшей визуализации и понимании стековых фреймов, которые создаются в V8.
Понимание машины на основе регистров
Как мы знаем, интерпретатор Ignition - это интерпретатор на основе регистров с регистром-аккумулятором. Эти "регистры" на самом деле не являются традиционными машинными регистрами, как можно было бы подумать. Вместо этого они представляют собой определенные слоты в регистровом файле, который выделяется как часть стековой рамки функции - по сути, это "виртуальные" регистры. Как мы увидим позже, байткоды могут указывать эти входные и выходные регистры, над которыми будут работать их аргументы.
Ignition состоит из набора обработчиков байткода, которые написаны на ассемблере высокого уровня, не зависящем от машины. Эти обработчики реализуются классом CodeStubAssembler и компилируются с помощью бэкенда TurboFan при компиляции браузера. В целом, каждый из этих обработчиков "обрабатывает" определенный байткод, а затем пересылает соответствующий обработчик следующему байткоду. Пример обработчика байткода LdaZero или "Load Zero to Accumulator" из v8/src/interpreter/interpreter-generator.cc можно увидеть ниже.
Когда V8 создает новый изолят, он загружает обработчики из файла моментального снимка, который был создан во время сборки. Изолят также содержит глобальную таблицу диспетчеризации интерпретатора, в которой хранится указатель объекта кода на каждый обработчик байткода, индексированный по значению байткода. Как правило, эта диспетчерская таблица представляет собой просто перечисление. Для того чтобы байткод мог быть запущен Ignition, функция JavaScript сначала переводится в байткод из своего AST генератором байткода. Этот генератор проходит по AST и выдает соответствующий байткод для каждого узла AST, вызывая функцию GenerateBytecode. Этот байткод затем ассоциируется с функцией (которая является объектом JSFunction) в поле свойств, известном как объект SharedFunctionInfo. После этого кодовая_точка_входа JavaScript-функции устанавливается на встроенную заглушку InterpreterEntryTrampoline. Заглушка InterpreterEntryTrampoline вводится при вызове функции JavaScript и отвечает за установку соответствующего стекового кадра интерпретатора, а также за отправку обработчику байткода интерпретатора для первого байткода функции. Затем начинается выполнение или "интерпретация" функции Ignition, которая обрабатывается в исходном файле v8/src/builtins/x64/builtins-x64.cc. В частности, на строках 1255 - 1387 в файле builtins-x64.cc функции Builtins::Generate_InterpreterPushArgsThenCallImpl и Builtins::Generate_InterpreterPushArgsThenConstructImpl отвечают за дальнейшее построение стекового кадра интерпретатора, проталкивая аргументы и состояние функции в стек. Я не буду слишком подробно останавливаться на генераторе байткода, но если вы хотите расширить свои знания, то советую прочитать раздел "Ignition Design Documentation: Генерация байткода", чтобы лучше понять, как он работает под капотом. В этом разделе я хочу сосредоточиться на распределении регистров и создании стековой рамки для функции.
Как же создается эта стековая рамка?
Ну, во время генерации байткода BytecodeGenerator также выделяет регистры в регистровом файле функции для локальных переменных, указателей объектов контекста и временных значений, необходимых для оценки выражения. Заглушка InterpreterEntryTrampoline обрабатывает начальное построение стекового кадра, а затем выделяет место в стековом кадре для регистрового файла. Эта заглушка также запишет undefined во все регистры в этом регистровом файле, чтобы сборщик мусора (GC) не увидел недопустимых (т.е. немаркированных) указателей при проходе по стеку.
Байткод будет работать с этими регистрами, указывая их в своих операндах, а Ignition затем загрузит или сохранит данные из определенного слота стека, связанного с регистром. Поскольку индексы регистров отображаются непосредственно на слоты стекового фрейма функции, Ignition может напрямую обращаться к другим слотам стека, таким как контекст и аргументы, которые были переданы вместе с функцией. Пример того, как выглядит стековый фрейм функции (предоставленный командой Chromium), можно увидеть ниже. Обратите внимание на "стековую рамку интерпретатора". Это стековый фрейм, который строится батутом InterpreterEntryTrampoline.

Как видите, у нас аргументы функций выделены красным цветом, а локальные переменные и временные переменные для вычисления выражений — зеленым. Светло-зеленая часть содержит объект текущего контекста Isolates, счетчик указателя вызывающей стороны и указатель на объект JSFunction. Этот указатель на JSFunction также известен как замыкание, которое ссылается на контекст функций, объект SharedFunctionInfo, а также на другие средства доступа, такие как FeedbackVector. Пример того, как эта JSFunction выглядит в памяти, можно увидеть ниже.

Вы также можете заметить, что в кадре стека нет регистра-аккумулятора. И причина этого в том, что регистр накопителя будет постоянно изменяться во время вызовов функций, в этом случае он хранится в интерпретаторе как регистр состояния. На этот регистр состояния указывает указатель кадра (FP), который также содержит указатель стека и счетчик кадров.

Возвращаясь к первому примеру стековой рамки, вы также заметите, что там есть указатель Bytecode Array, который представляет собой последовательность байткодов интерпретатора для данной конкретной функции в пределах стековой рамки. Изначально каждый байткод представляет собой перечисление, где индекс байткода хранит соответствующий обработчик - как объяснялось ранее.
Пример такого BytecodeArray можно увидеть в v8/src/objects/code.h, а фрагмент этого кода приведен ниже.
Как вы видите, функция GetFirstBytecodeAddress() отвечает за получение первого адреса байткода в массиве. Как же она находит этот адрес?
Давайте посмотрим на байткод, сгенерированный для var num = 42.
Не беспокойтесь о том, что означает каждый из этих байткодов, мы объясним это чуть позже. Посмотрите на 1-ю строку в массиве байткодов, она хранит LdaConstant. Слева от нее мы видим 13 00. Шестнадцатеричное число 0x13 - это перечислитель байткода, который представляет собой место, где будет находиться обработчик для этого байткода.
Как только это получено, будет вызвана функция SetBytecodeHandler() с байткодом, операндами и перечислением обработчиков. Эта функция находится в файле v8/src/interpreter/interpreter.cc; пример этой функции показан ниже.
Как вы можете видеть, dispatch_table_[index] вычислит индекс байткода из таблицы диспетчеризации, которая хранится в физическом регистре, и в конечном итоге это инициирует или завершит функцию Dispatch() для выполнения байткода. Массив байткода также содержит нечто, называемое "указатель пула констант", в котором хранятся объекты кучи, на которые ссылаются как на константы в сгенерированном байткоде, такие как строки и целые числа. Пул констант представляет собой фиксированный массив указателей на объекты кучи. Пример указателя BytecodeArray и его константного пула объектов кучи показан ниже.

Прежде чем мы продолжим, хочу упомянуть еще одну вещь: в заглушке InterpreterEntryTrampoline есть некоторые фиксированные машинные регистры, которые используются Ignition. Эти регистры находятся в файле v8/src/codegen/x64/register-x64.h.
Пример этих регистров можно увидеть ниже, а к тем, которые представляют интерес, добавлены комментарии.
Теперь, когда мы это поняли, пришло время разобраться в том, как выглядит байткод V8 и как операнд байткода взаимодействует с регистровым файлом.
Понимание байткода V8
Как говорилось в первой части, в V8 существует несколько сотен байткодов, и все они определены в заголовочном файле v8/src/interpreter/bytecodes.h. Как мы увидим через минуту, каждый из этих байткодов определяет свои входные и выходные операнды как регистры в регистровом файле. Кроме того, многие опкоды начинаются с Lda или Sta в названии, где a означает аккумулятор.
Например, приведем определение байткода для LdaSmi:
Как вы видите, LdaSmi "загружает" (отсюда Ld) значение в регистр аккумулятора. В данном случае он загружает операнд kImm, который представляет собой подписанный байт, что совпадает с Smi или Small Integer в имени байткода. В общем, этот байткод загрузит в регистр аккумулятора маленькое целое число.
Обратите внимание, что список операндов и их типы определены в заголовочном файле v8/src/interpreter/bytecode-operands.h.
Итак, вооружившись этой базовой информацией, давайте посмотрим на байткод одной из функций JavaScript. Для начала запустим d8 с флагом --print-bytecode, чтобы мы могли увидеть байткод. Как только это будет сделано, просто введите произвольный код JavaScript и нажмите Enter несколько раз. Причина этого в том, что V8 - "ленивый" движок, поэтому он не будет компилировать то, что ему не нужно. Но поскольку мы впервые используем строки и числа, он будет компилировать такие библиотеки, как Stringify, что приведет к огромному количеству вывода.
После этого давайте создадим простую функцию JavaScript под названием incX, которая будет увеличивать свойство x объекта на единицу и возвращать его нам. Функция должна выглядеть следующим образом.
Это сгенерирует некоторый байткод, но не будем об этом беспокоиться. Теперь, когда у нас это есть, давайте вызовем эту функцию с объектом, у которого свойству x присвоено значение, и посмотрим сгенерированный байткод.
Мы проигнорируем большую часть вывода и сосредоточимся только на разделе байт-кода. Но прежде чем мы это сделаем, обратите внимание, что этот байт-код находится в объекте SharedFunctionInfo, что совпадает с нашим объяснением ранее! Для начала мы видим, что LdaSmi вызывается для загрузки небольшого целого числа в регистр-аккумулятор, значение которого будет равно 1. Затем мы вызываем Star0, который будет хранить (отсюда st) значение в аккумуляторе (в соответствии с a) в регистре r0. Итак, в этом случае мы перемещаем 1 в r0.
Короче говоря, это байт-код, который загружает obj.x. Другой операнд [0] известен как вектор обратной связи, который содержит информацию о времени выполнения и данные о форме объекта, которые используются для оптимизации TurboFan. Затем мы добавляем значение регистра r0 в аккумулятор, в результате чего получается значение 14. Наконец, мы вызываем Return, который возвращает значение аккумулятора, и выходим из функции. Чтобы помочь вам визуализировать это во фрейме стека, я предоставил GIF того, что происходит в упрощенном стеке с каждой инструкцией байт-кода.

Как видите, хотя байткоды немного загадочны, как только мы поймем, что делает каждый из них, их будет довольно легко понять и следовать за ними. Если вы хотите узнать больше о байткоде V8, я советую прочитать "JavaScript Bytecode - v8 Ignition Instructions", где рассматривается значительная часть различных операций.
Sparkplug
Теперь, когда у нас есть достаточное понимание того, как Ignition генерирует и выполняет ваш JavaScript-код в виде байткода, самое время начать изучать компиляционную часть конвейера компилятора V8. Мы начнем со Sparkplug, поскольку его довольно легко понять, так как он вносит лишь небольшие изменения в уже сгенерированный байткод и стек в целях оптимизации.
Как мы знаем из первой части, Sparkplug - это очень быстрый неоптимизирующий компилятор V8, который находится между Ignition и TurboFan. По сути, Sparkplug - это не совсем компилятор, а скорее транспилятор, который преобразует байткод Ignitions в машинный код, чтобы запустить его нативно. Кроме того, это неоптимизирующий компилятор, поэтому он не делает очень специфических оптимизаций, так как это делает TurboFan. Итак, что же делает Sparkplug таким быстрым? Ну, Sparkplug быстр, потому что он обманывает. Функции, которые он компилирует, уже были скомпилированы в байткод, и, как мы знаем, Ignition уже проделал тяжелую работу по разрешению переменных, потоку управления и т.д. В этом случае Sparkplug компилирует из байткода, а не из исходников JavaScript.
Во-вторых, Sparkplug не создает никакого промежуточного представления (IR), как это делают большинство компиляторов (о чем мы узнаем позже). В данном случае Sparkplug компилирует непосредственно в машинный код за один линейный проход над байткодом. В общем случае это известно как отображение 1:1. Забавно то, что Sparkplug - это просто оператор switch внутри цикла for, который отправляет фиксированный байткод, а затем генерирует машинный код. Мы можем увидеть эту реализацию в исходном файле v8/src/baseline/baseline-compiler.cc.
Пример функции генерации машинного кода Sparkplug можно увидеть ниже.
Как же Sparkplug генерирует этот машинный код? Ну, конечно же, он делает это, снова обманывая. Sparkplug генерирует очень мало собственного кода, вместо этого Sparkplug просто вызывает встроенные модули байткода, которые обычно вводятся InterpreterEntryTrampoline и затем обрабатываются в v8/src/builtins/x64/builtins-x64.cc. Если вы вспомните наш объект JSFunction во время разговора о Ignition, вы вспомните, что закрытие связывалось с "оптимизированным кодом". По сути, Sparkplug будет хранить там встроенный модуль байткода, и когда функция будет выполнена, вместо диспетчеризации к байткоду мы вызовем встроенный модуль напрямую. В этот момент вы можете подумать, что Sparkplug - это, по сути, прославленный интерпретатор, и вы не ошибетесь. Sparkplug практически просто сериализует выполнение интерпретатора, вызывая те же самые встроенные модули. Но это позволяет функции JavaScript быть быстрее, потому что таким образом мы можем избежать накладных расходов интерпретатора, таких как декодирование опкодов и поиск диспетчеризации байткода, что позволяет нам сократить использование процессора, перейдя от эмуляционного движка к нативному исполнению.
Чтобы узнать немного больше о том, как работают эти встроенные модули, я рекомендую прочитать "Короткие вызовы встроенных модулей".
Сопоставление 1:1
Сопоставление 1:1 в Sparkplug связано не только с тем, как он компилирует байткод Ignition в машинный код; оно также связано с фреймами стека. Как мы знаем, каждая часть конвейера компилятора должна хранить состояние функции. И как мы уже видели в V8, состояния функций JavaScript хранятся в стековых фреймах Ignition путем хранения текущей вызываемой функции, контекста, с которым она вызывается, количества переданных аргументов, указателя на массив байткода и так далее и тому подобное. Теперь, как мы знаем, Ignition - это интерпретатор на основе регистров, имеющий виртуальные регистры, которые используются для аргументов функций и в качестве входов и выходов для операндов байткода. Чтобы Sparkplug был быстрым и не занимался собственным распределением регистров, он использует регистровые фреймы Ignition, что, в свою очередь, позволяет Sparkplug зеркально отражать поведение интерпретатора и его стек. Это позволяет Sparkplug не нуждаться в каком-либо сопоставлении между двумя фреймами, что делает эти стековые фреймы почти 1:1 совместимыми. Обратите внимание, что я говорю "почти 1:1 совместимы", есть одно небольшое различие между стековыми фреймами Ignition и Sparkplug. Это отличие заключается в том, что Sparkplug не нужно сохранять слот смещения байткода в регистровом файле, поскольку код Sparkplug испускается непосредственно из байткода. Вместо этого он заменяет его кэшированным вектором обратной связи.
Пример сравнения этих двух стековых фреймов можно увидеть на изображении ниже, предоставленном документацией Ignition.

Так почему же Sparkplug должен создавать и поддерживать схему каркаса стека, аналогичную Ignitions? По одной причине, и по основной причине того, как работают Sparkplug и Turbofan, делая нечто, называемое заменой на стеке (OSR). OSR - это возможность заменить текущий выполняющийся код на другую версию. В данном случае, когда Ignition видит, что функция JavaScript используется часто, он отправляет ее в Sparkplug для ускорения. Как только Sparkplug сериализует байткоды в свои встроенные модули, он заменит стек интерпретаторов для этой конкретной функции. Когда стек будет пройден и выполнен, код перейдет непосредственно в Sparkplug вместо того, чтобы выполняться на эмулированном стеке Ignitions. А поскольку кадры "зеркально отражены", это технически позволяет V8 переключаться между кодом интерпретатора и Sparkplug почти с нулевыми накладными расходами на перевод кадров. Прежде чем мы продолжим, я хочу обратить внимание на аспект безопасности Sparkplug. В целом, маловероятно, что в самом сгенерированном коде есть проблемы с безопасностью. Больший риск безопасности при использовании Sparkplug связан с тем, как интерпретируется расположение кадров стека Ignitions, что может привести к путанице типов или выполнению кода на стеке. Примером может служить выпуск 1179595, который был потенциальным RCE из-за некорректной проверки количества регистров. Есть также проблема в том, как Sparkplug выполняет переключение битов RX/WX - но я не буду вдаваться в подробности, поскольку это действительно не важно, и такие ошибки не играют важной роли в этой общей серии. Итак, мы поняли, как работает Ignition и Sparkplug. Теперь пришло время погрузиться глубже в конвейер компилятора и понять оптимизирующий компилятор TurboFan.
TurboFan
TurboFan - это компилятор V8 Just-In-Time (JIT), который сочетает в себе интересную концепцию непосредственного представления, известную как "море узлов", с многоуровневым конвейером трансляции и оптимизации, который помогает TurboFan генерировать машинный код лучшего качества из байткода. Те, кто был внимателен, читая код и документацию по ходу работы, знают, что TurboFan - это гораздо больше, чем просто компилятор. TurboFan фактически отвечает за обработчики байткода интерпретатора, встроенные модули, вставки кода и систему встроенного кэша с помощью своего макроассемблера! Поэтому, когда я говорю, что TurboFan - самая важная часть конвейера компилятора, я не шучу.
Итак, как же работают эти оптимизирующие компиляторы, такие как TurboFan?
Оптимизирующие компиляторы работают с помощью так называемого "профилировщика", о котором мы вкратце упоминали в первой части. По сути, этот профилировщик работает заранее, отслеживая код, который следует оптимизировать (мы называем этот код или функцию JavaScript "горячей"). Он делает это, собирая метаданные и "образцы" из функций JavaScript и стека, просматривая информацию, собранную встроенными кэшами и вектором обратной связи. Затем компилятор строит структуру данных промежуточного представления (IR), которая используется для создания оптимизированного кода. Весь этот процесс просмотра кода и последующей компиляции машинного кода называется Just-in-Time или JIT-компиляцией.
Компиляция точно в срок (JIT)
Как мы знаем, выполнение байткода в интерпретаторе VM происходит медленнее, чем выполнение ассемблера на родной машине. Причина этого в том, что JavaScript динамичен и существует много накладных расходов на поиск свойств, проверку объектов, значений и т.д., а также мы работаем на эмулированном стеке.
Конечно, Maps и Incline Caching (IC) помогают решить некоторые из этих накладных расходов, ускоряя динамический поиск свойств, объектов и значений - но они все равно не могут обеспечить пиковую производительность. Причина этого в том, что каждый IC действует сам по себе и не имеет никаких знаний или представлений о своих соседях. Возьмем, к примеру, Maps: если мы добавляем свойство к известной форме, нам все равно приходится следовать таблице переходов и искать или добавлять дополнительные формы. Если нам приходится делать это много раз для конкретной функции или объекта, даже при известной форме, мы тратим много вычислительных циклов, делая это снова и снова. Поэтому, когда есть функция JavaScript, которая выполняется много раз, возможно, стоит потратить время на то, чтобы передать функцию в компилятор и скомпилировать ее в машинный код, что позволит выполнять ее гораздо быстрее.
Для примера возьмем такой код:
Функция hot_function просто принимает объект и возвращает значение свойства x. Далее мы выполняем эту функцию примерно 10k раз и для каждого объекта мы просто передаем новое целое число для свойства x. В этом случае, поскольку функция используется много раз, а общая форма объекта не меняется, V8 может решить, что лучше просто передать ее вверх по конвейеру (известному как "tier-up") для компиляции, чтобы она выполнялась быстрее.
Мы можем увидеть это в действиях в d8, отследив оптимизацию с помощью флага --trace-opt. Итак, давайте сделаем именно это, а также добавим команду --allow-natives-syntax, чтобы мы могли изучить, как выглядит код функции до и после оптимизации.
Начнем с запуска d8 и установки нашей функции. После этого воспользуйтесь командой %DisassembleFunction против hot_function, чтобы узнать ее тип. Вы должны получить что-то похожее.
Как вы можете видеть, изначально этот объект кода будет выполнен Ignition, поскольку это BUILTIN, и будет обработан InterpreterEntryTrampoline, как мы знаем. Теперь, если мы выполним эту функцию 10k раз, мы увидим, что она будет оптимизирована TurboFan.
Как вы видите, TurboFan включается и начинает компилировать функцию для оптимизации. Обратите внимание на несколько ключевых моментов в трассировке оптимизации. Как вы можете видеть в первой строке трассировки оптимизации, мы помечаем SFI или SharedFunctionInfo функции JSFunction для оптимизации. Если вы вспомните наше глубокое погружение в Ignition, вы вспомните, что SFI содержит байткод для нашей функции. TurboFan будет использовать этот байткод для генерации IR, а затем оптимизирует его до машинного кода. Теперь, если вы посмотрите дальше, вы увидите упоминание OSR или замены на стеке. В основном TurboFan делает то же самое, что и Sparkplug, когда оптимизирует байткод. Он заменит стековый кадр на настоящий JIT или системный стековый кадр, который будет указывать на оптимизированный код во время выполнения. Это позволяет функции перейти непосредственно к оптимизированному коду при следующем вызове, а не выполняться в эмулированном стеке Ignitions. Если мы снова выполним %DisassembleFunction против нашей горячей_функции, мы увидим, что она теперь оптимизирована, и точка входа в код в SharedFunctionInfo будет указывать на оптимизированный машинный код.
Те, у кого зоркий глаз, могли заметить кое-что интересное, когда мы проследили оптимизацию нашей функции. Если вы были внимательны, то заметили, что TurboFan включился не сразу, а через несколько секунд - или после нескольких тысяч итераций цикла. Почему так? Это происходит потому, что TurboFan ждет, пока код "разогреется". Если вы помните нашу дискуссию о Ignition и Sparkplug, мы вкратце упомянули вектор обратной связи. Этот вектор хранит данные времени выполнения объекта вместе с информацией из встроенных кэшей и собирает так называемую обратную связь по типу. Это очень важно для TurboFan, поскольку, как мы знаем, JavaScript динамичен, и у нас нет возможности хранить статическую информацию о типе. Во-вторых, мы не знаем тип значения до времени выполнения. JIT-компилятор фактически вынужден делать обоснованные предположения об использовании и поведении кода, который он компилирует, такие как тип вашей функции, тип передаваемых переменных и т.д. По сути, компилятор делает много предположений об использовании и поведении кода, который он компилирует. По сути, компилятор делает много предположений или "догадок". Именно поэтому оптимизирующие компиляторы смотрят на информацию, собранную кэшами наклона, и используют вектор обратной связи для принятия обоснованных решений о том, что нужно сделать с кодом, чтобы он стал быстрым. Это известно как спекулятивная оптимизация.
Спекулятивная оптимизация и защита типов
Как же спекулятивная оптимизация помогает нам превратить наш код JavaScript в высоко оптимизированный машинный код? Чтобы объяснить это, давайте начнем с примера.
Допустим, у нас есть простая оценка для функции add, например return 1 + i. Здесь мы возвращаем значение, прибавляя 1 к i. Не зная, какой тип i, мы должны следовать стандартной реализации ECMAScript для семантики EvaluateStringOrNumericBinaryExpression.

Как видите, как только мы оцениваем левую и правую ссылки и вызываем GetValue как для левого, так и для правого значений нашего операнда, нам нужно следовать стандарту ECMAScript для ApplyStringOrNumericBinaryOperator, чтобы мы могли вернуть наше значение.

Если вы еще не поняли, что без знания типа переменной i, будь то целое число или строка, мы никак не сможем реализовать всю эту оценку всего за несколько машинных инструкций и при этом сделать ее быстрой. Именно здесь вступает в дело спекулятивная оптимизация, при которой TurboFan будет полагаться на вектор обратной связи, чтобы сделать свои предположения о возможных типах i. Например, если после нескольких сотен запусков мы посмотрим на вектор обратной связи для байткода Add и узнаем, что i - это число, то нам не придется обрабатывать оценки ToString или даже ToPrimitive. В этом случае оптимизатор может взять инструкцию IR и утверждать, что i и возвращаемое значение - это просто числа, и загрузить их как таковые. Это минимизирует количество машинных инструкций, которые нам нужно сгенерировать.
Как же выглядят эти векторы обратной связи в случае нашей функции?
Если вы вспомните упоминание объекта JSFunction или закрытия, вы вспомните, что закрытие связало нас со слотом вектора обратной связи, а также с SharedFunctionInfo. В векторе обратной связи есть интересный слот под названием BinaryOp, который записывает информацию о входах и выходах бинарных операций, таких как +, -, * и т.д.
Мы можем проверить, что находится внутри нашего вектора обратной связи и увидеть этот конкретный слот, выполнив %DebugPrint против нашей функции add.
Здесь есть несколько интересных элементов. Invocation count показывает нам количество запусков функции add, а если мы посмотрим на наш вектор обратной связи, то увидим, что у нас есть только один слот, который является BinaryOp, о котором мы говорили. Заглянув в этот слот, мы увидим, что он содержит текущий тип обратной связи SignedSmall, который, по сути, относится к SMI. Помните, что эта информация обратной связи интерпретируется не V8, а TurboFan, а, как мы знаем, SMI - это знаковое 32-битное значение, как мы объясняли в части, посвященной тегам указателей в первой части этой серии. В целом, эти спекуляции с помощью векторов обратной связи отлично помогают ускорить наш код, удаляя ненужные машинные инструкции для различных типов. К сожалению, довольно небезопасно применять инструкции, ориентированные исключительно на один тип, к динамическим объектам. Итак, что произойдет, если на полпути в оптимизированной функции мы передадим строку вместо числа? По сути, если это произойдет, то мы получим уязвимость путаницы типов. Для защиты от потенциально неверных предположений TurboFan добавляет перед выполнением определенных инструкций так называемую защиту типа. Эта защита типа проверяет, что форма объекта, который мы передаем, имеет правильный тип. Это делается до того, как объект попадает в наши оптимизированные операции. Если объект не соответствует ожидаемой форме, то выполнение оптимизированного кода не может быть продолжено. В этом случае мы "выйдем" из ассемблерного кода и вернемся к неоптимизированному байткоду в интерпретаторе и продолжим выполнение там. Это известно как "деоптимизация". Пример защиты типа и перехода к деоптимизации в оптимизированном ассемблерном коде можно увидеть ниже.
Теперь деоптимизация за счет защит типов не ограничивается проверкой несовпадения типов объектов. Они также работают с арифметическими операциями и проверкой границ.
Например, если наш оптимизированный код был оптимизирован для арифметических операций над 32-разрядными целыми числами, и произошло переполнение, мы можем деоптимизировать и позволить Ignition обработать вычисления - тем самым защитив себя от потенциальных проблем безопасности на машине. Такие проблемы, которые могут привести к деоптимизации, известны как "побочные эффекты" (которые мы рассмотрим более подробно позже). Как и в случае с процессом оптимизации, мы также можем увидеть деоптимизацию в действии в d8, используя флаг --trace-deopt. После этого давайте снова добавим нашу функцию add и запустим следующий цикл.
Это просто позволит оптимизировать функцию для чисел, а затем, после 7000 итераций, мы начнем передавать строку, которая должна вызвать спасение. Ваш вывод должен быть похож на:
Как вы можете видеть, функции оптимизируются, а затем мы вызываем отказ. Это деоптимизирует код обратно в байткод из-за недостаточного типа во время нашего вызова. Затем происходит нечто интересное. Функция снова оптимизируется. Почему? Ну, функция все еще "горячая", и впереди еще несколько тысяч итераций. Теперь, когда TurboFan собрал и число, и строку в обратной связи, он вернется и оптимизирует код во второй раз. Но на этот раз он добавит код, который позволит оценивать строки. В этом случае будет добавлен второй защитник типов - таким образом, второй цикл кода теперь оптимизирован и для числа, и для строки! Хороший пример и объяснение этого можно увидеть в видео "Inside V8: The choreography of Ignition and TurboFan".
Мы также можем увидеть эту обновленную обратную связь в слоте BinaryOp, выполнив команду %DebugPrint для нашей функции add. Вы должны увидеть нечто подобное, как показано ниже.
Как вы можете видеть, BinaryOp теперь хранит тип обратной связи Any, вместо SignedSmall и String. Почему? Это связано с тем, что называется решеткой обратной связи.
Решетка обратной связи
Решетка обратной связи хранит возможные состояния обратной связи для операции. Она начинается с None, что означает, что функция ничего не видела, и спускается вниз к состоянию Any, что означает, что она видела комбинацию входов и выходов. Состояние Any указывает на то, что функцию следует считать полиморфной, в то время как любое другое состояние, напротив, указывает на то, что функция является мономорфной - поскольку она производит только определенное значение. Если вы хотите узнать больше о разнице между мономорфным и полиморфным кодом, я настоятельно рекомендую вам прочитать фантастическую статью "Что такое мономорфизм?".
Ниже я привел наглядный пример того, как примерно выглядит решетка обратной связи.

Как и решетка массивов из первой части, эта решетка работает точно так же. Отзывы могут двигаться только вниз по решетке. Как только мы перейдем от числа к любому, мы никогда не сможем вернуться назад. Если по какой-то волшебной причине мы все же вернемся назад, то рискуем попасть в так называемый цикл деоптимизации, когда оптимизирующий компилятор потребляет недопустимую обратную связь и постоянно выходит из оптимизированного кода. Более подробную информацию о проверке типов можно найти в файле v8/src/compiler/use-info.h. Также, если вы хотите узнать больше о системе обратной связи и встроенном кэше V8, советую посмотреть фильм "V8 и как он вас слушает - Майкл Стэнтон".
Промежуточное представление (IR) "Море узлов"
Теперь, когда мы знаем, как собирается обратная связь по типам для TurboFan, чтобы сделать свои спекулятивные предположения, давайте посмотрим, как TurboFan строит свой специализированный IR на основе этой обратной связи. Причина, по которой создается IR, заключается в том, что эта структура данных абстрагируется от сложности кода, что, в свою очередь, облегчает оптимизацию компилятора. Так, IR TurboFans "Sea of Nodes" основан на статическом однократном присваивании или SSA, которое является свойством IR, требующим, чтобы каждая переменная была присвоена ровно один раз и определена до ее использования. Это полезно для таких оптимизаций, как устранение избыточности.
Пример SSA для нашей функции add из предыдущего примера можно увидеть ниже.
Эта форма SSA затем преобразуется в формат графа, который похож на граф потока управления (CFG), где используются узлы и ребра для представления кода и его зависимостей между вычислениями. Такой вид графа позволяет TurboFan использовать его как для анализа потока данных, так и для генерации машинного кода. Итак, давайте посмотрим, как выглядит это море узлов. Для этого мы будем использовать наш пример hot_function. Начнем с создания нового файла JavaScript и добавим в него следующее.
После этого запустим этот скрипт через d8 с флагом --trace-turbo, который позволяет нам отследить и сохранить IR, сгенерированный TurboFans JIT. Ваш результат должен быть похож на мины. В конце выполнения скрипт должен сгенерировать JSON-файл, имеющий соглашение об именовании turbo-*.json.
После этого перейдите к Turbolizer в веб-браузере, нажмите CTRL + L и загрузите ваш JSON-файл. Этот инструмент поможет нам визуализировать граф "море узлов", сгенерированный TurboFan.
График, который вы увидите, должен быть практически идентичен:

B Turbolizer, слева вы увидите свой исходный код, а справа (не показано на изображении) - оптимизированный машинный код, сгенерированный TurboFan. В центре находится граф "море узлов".
В настоящее время многие узлы скрыты и показаны только управляющие узлы, что является поведением по умолчанию. Если вы нажмете на поле "Показать все узлы" справа от символа "обновить", вы увидите все узлы. Повозившись в Turbolizer и просмотрев график, вы заметите, что есть пять различных цветов узлов, и они представляют следующее:
Желтый: Эти узлы представляют управляющие узлы, то есть все, что может изменить "поток" сценария - например, оператор if/else.
Светло-синий: Эти узлы представляют значение, которое может иметь или возвращать определенный узел, например, константы кучи или встроенные значения.
Красный: Представляет семантику перегруженных операторов JavaScript, таких как любые действия, выполняемые на уровне JavaScript, т.е. JSCall, JSAdd и т.д. Они напоминают операции байткода.
Синий: Выражают операции на уровне виртуальной машины, такие как выделение, проверка границ, загрузка данных из стека и т.д. Это полезно для отслеживания обратной связи, потребляемой Turbofan.
Зеленый: Они соответствуют отдельным инструкциям машинного уровня.
Как мы видим, каждый узел в этом море узлов может представлять арифметические операции, загрузки, сохранения, вызовы, константы и т.д. Затем есть три ребра (представленные стрелками между каждым узлом), о которых мы должны знать, которые выражают зависимости. Эти ребра следующие:
Control: Как и в CFG, эти ребра позволяют выполнять ветвления и циклы.
Value: Как и в графиках потоков данных, эти ребра показывают зависимость значений и выход.
Effect: Операции детального порядка, такие как чтение или запись состояний.
С этими знаниями давайте немного расширим граф и посмотрим на некоторые другие узлы, чтобы понять, как работает поток. Обратите внимание, что я скрыл несколько отдельных узлов, которые на самом деле не важны.

Как мы видим, узлы желтого цвета - это узлы управления, которые управляют потоком функции. Вначале у нас есть узел Loop, который сообщает нам, что мы идем в цикл. От него управляющие ребра указывают на узлы Branch и LoopExit. Branch - это именно то, что он означает, он "разветвляет" цикл на утверждение True/False. Если мы проследим за узлом Branch вверх, то увидим, что в нем есть узел SpeculativeNumberLessThan, который имеет ребро значения, указывающее на NumberConstant со значением 10000. Это соответствует нашей функции, поскольку мы выполняли цикл 10k раз. Поскольку этот узел имеет зеленый цвет, он является машинной инструкцией и обозначает нашу защиту типа для цикла. Из узла SpeculativeNumberLessThan видно, что есть ребро эффекта, указывающее на LoopExitEffect, что означает, что если число больше 10k, мы выходим из цикла, так как только что нарушили предположение. Пока значение меньше 10k и SpeculativeNumberLessThan истинно, мы загрузим наш объект и вызовем JSDefineNamedOwnProperty, который получит смещение объекта к свойству x. Затем мы вызовем JSCall, чтобы добавить 1 к значению нашего свойства и вернуть значение. Из этого узла у нас также есть ребро эффекта, идущее к SpeculativeSafeIntegerAdd. Этот узел имеет ребро значения, указывающее на узел NumberConstant, который имеет значение 1, что и является математическим сложением, которое мы выполняем при возврате значения. Еще раз обратите внимание, что у нас есть узел SpeculativeSafeIntegerAdd, который проверяет, что арифметика сложения, которую мы выполняем, действительно добавляет SMI, а не что-то другое, иначе сработает защита типов и произойдет деоптимизация. Для тех, кому интересно, что такое узел Phi, это узел SSA, который объединяет две (или более) возможности для значения, которые были вычислены разными ветвями. В данном случае он объединяет обе потенциальные целочисленные спекуляции вместе.
Как видите, понимание этих графов не слишком сложное, как только вы поймете основы.
Теперь, если вы посмотрите на левую верхнюю часть окна "Море узлов", вы увидите, что мы находимся в опции V8.TFBytecodeGraphBuilder. Эта опция показывает нам сгенерированный IR из байткода без каких-либо примененных к нему оптимизаций. Из выпадающего меню мы можем выбрать другие различные проходы оптимизации, через которые проходит этот код, чтобы просмотреть связанный IR.
Общие оптимизации
Итак, теперь, когда мы рассмотрели TurboFans Sea of Nodes, у нас должно быть хотя бы приблизительное понимание того, как ориентироваться и понимать сгенерированный IR. Отсюда мы можем перейти к пониманию некоторых общих оптимизаций TurboFans. Эти оптимизации, по сути, действуют на исходный граф, который был получен из байткода. Поскольку результирующий граф теперь имеет статическую информацию о типах благодаря защитникам типов, оптимизация выполняется более классическим способом, опережающим время, чтобы улучшить скорость выполнения или объем памяти кода. Затем, когда граф оптимизирован, полученный граф опускается в машинный код (известный как "опускание") и записывается в исполняемую область памяти для выполнения V8 при вызове скомпилированной функции. Следует отметить, что опускание может происходить в несколько этапов с последующими оптимизациями между ними, что делает этот конвейер компилятора довольно гибким.
С учетом сказанного, давайте рассмотрим некоторые из этих распространенных оптимизаций.
Typer
Одна из самых ранних фаз оптимизации называется TyperPhase, которая выполняется функцией OptimizeGraph. Эта фаза прослеживает код и определяет результирующие типы операций с объектами кучи, например, Int32 + Int32 = Int32. При запуске Typer посетит каждый узел графа и попытается "сократить" их, пытаясь упростить логику операций. Затем он вызовет связанный с узлом вызов Typer, чтобы связать с ним тип. Например, в нашем случае константные целые числа в цикле и возвратная арифметика будут посещены Typer::Visitor: ypeNumberConstant, который вернет тип Range - как видно из примера кода из v8/src/compiler/types.cc.
ypeNumberConstant, который вернет тип Range - как видно из примера кода из v8/src/compiler/types.cc.
Теперь что насчет наших спекулятивных узлов?
Они обрабатываются OperationTyper. В нашем случае арифметическая спекуляция для возврата значения будет вызывать OperationTyper::SpeculativeSafeIntegerAdd, который установит тип в диапазон "безопасных целых чисел", например, Int64. Этот тип будет проверяться, и если во время выполнения он не является Int64, мы деоптимизируем. По сути, это позволяет арифметическим операциям иметь положительное и отрицательное возвращаемое значение и предотвращает потенциальные проблемы переполнения/недополнения.
Зная это, давайте посмотрим на этап оптимизации V8.TFTyper, чтобы увидеть граф и узлы, связанные с типами.

Анализ диапазона
Во время оптимизации Typer компилятор прослеживает код, определяет диапазон операций и вычисляет границы результирующих значений. Это известно как анализ диапазона.
Если вы заметили на графике выше, мы встретили тип Range, особенно для узла SpeculativeSafeIntegerAdd, который имел диапазон переменной Int64. Это было сделано потому, что оптимизатор анализа диапазона вычисляет минимальное и максимальное значения, которые добавляются или возвращаются. В нашем случае мы возвращали значение i из свойства нашего объекта x плюс 1. Обратная связь типа действительно знала только то, что возвращаемое значение является целым числом и все, она никогда не могла сказать, в каком диапазоне будет это значение. Поэтому, чтобы подстраховаться, она решила дать ему самое большое значение, какое только возможно, чтобы избежать проблем.
Итак, давайте еще раз посмотрим на анализ диапазона, рассмотрев следующий код:
Как мы видим, в зависимости от того, какой тип параметра obj передан, если obj - это строка, равная слову leet, то a будет равно 1337, в противном случае оно будет равно 13. Эта часть кода пройдет через SSA и будет объединена в узел Phi, который будет содержать диапазон того, каким может быть a. Диапазон констант будет установлен на их жестко закодированное значение, но эти константы также будут влиять на наши умозрительные диапазоны из-за арифметических вычислений.
Если мы посмотрим на график, полученный из этого кода после анализа диапазона, то увидим следующее.

Как видите, благодаря SSA у нас есть узел Phi. Во время анализа диапазона типер обращается к функции узла TypePhi и создает объединение операндов 13 и 1337, что позволяет нам получить возможный диапазон для a. Для спекулятивных узлов OperationTyper вызывает функцию AddRanger, которая вычисляет минимальную и максимальную границы для типа Range. В данном случае видно, что тип вычисляет диапазон возвращаемых значений для обеих возможных итераций a после арифметических операций. Благодаря этому, в случае, если анализ диапазона не удался и мы получаем значение, не ожидаемое компилятором, мы деоптимизируем. Довольно просто для понимания!
Устранение проверки границ (BCE)
Еще одной распространенной оптимизацией, которая применялась с тайпером на этапе упрощенного опускания, была операция CheckBounds, которая применяется к спекулятивным узлам CheckBound. Эта оптимизация обычно применяется к операциям доступа к массиву, если было доказано, что индекс массива находится в пределах границ массива после анализа диапазона. Причина, по которой я говорю "была", заключается в том, что команда разработчиков Chromium решила отключить эту оптимизацию, чтобы усилить проверку границ TurboFan против ошибок, связанных с тайперами. Есть несколько "багов", которые позволят вам обойти эту защиту, но я не буду об этом рассказывать. Если вы хотите узнать больше об этих ошибках, то советую прочитать статью "Обход усиления защиты Chrome от ошибок тайперов".
В любом случае, давайте продемонстрируем, как этот тип оптимизации мог бы сработать, взяв для примера следующий код:
Как вы можете видеть, это очень похоже на код, который мы использовали в нашем анализе диапазона. Мы снова принимаем параметр в нашу функцию hot_function, и если объект соответствует строке "leet", мы устанавливаем a в 2 и возвращаем значение 1337, в противном случае мы устанавливаем a в 1 и возвращаем значение 13. Обратите особое внимание на то, что a никогда не равно 0, поэтому мы никогда не сможем или, по крайней мере, не должны иметь возможность вернуть 0. Это создает для нас интересный случай, когда мы смотрим на график. Итак, давайте обратимся к части IR, посвященной анализу побега, и посмотрим, как выглядит наш график.

Как вы видите, у нас есть еще один узел Phi, который объединяет наши потенциальные значения a, а затем у нас есть узел CheckBounds, который используется для проверки границ массива. Если мы находимся в диапазоне 1 или 2, мы вызываем LoadElement, чтобы загрузить наш элемент из массива, в противном случае мы выйдем из системы, так как проверка границ не ожидает индекса 0.
Для тех, кто уже заметил это, может возникнуть вопрос, почему наш LoadElement имеет тип Signed31, а не Signed32. Просто, Signed31 представляет тот факт, что первый бит используется для обозначения знака. Это означает, что в случае 32-битного знакового целого числа мы фактически работаем с 31 битом значения вместо 32. Также, как мы видим, LoadElement имеет на входе FixedArray HeapConstant с длиной 3. Этот массив будет нашим массивом значений. После того как анализ побега проведен, мы переходим к упрощенной фазе опускания. Эта фаза понижения просто (каламбурно) изменяет все представления значений на правильное машинное представление, как диктуют сами операторы машины. Код для этой фазы находится в файле v8/src/compiler/simplified-lowering.cc. Именно в этой фазе происходит устранение проверки границ.
Как же компилятор решает сделать узел CheckBounds избыточным?
Ну, для каждого узла CheckBounds будет вызвана функция VisitCheckBounds. Эта функция отвечает за проверку и удостоверение в том, что минимальный диапазон индекса равен или больше нуля и что максимальный диапазон не превышает длины массива. Если проверка истинна, то вызывается DeferReplacement, которая помечает узел для удаления.
Пример функции VisitCheckBounds до фиксации ужесточения 7bb6dc0e06fa158df508bc8997f0fce4e33512a5 можно увидеть ниже.
Как вы видите, наш диапазон CheckBound попадает в оператор if, где Range(1,2).Min() >= 0 и Range(1,2).Max() < 3. В этом случае наш узел №46 из приведенного выше графика станет ненужным и будет удален. Теперь, если вы посмотрите на обновленный код после фиксации, вы увидите небольшое изменение. Вызов DeferReplacement был удален, и вместо этого мы заменяем узел узлом CheckedUint32Bounds. Если проверка не удалась, TurboFan вызывает kAbortOnOutOfBounds, который прерывает проверку границ и завершает работу вместо деоптимизации.
Новый код можно увидеть ниже:
Если мы посмотрим на упрощенную нижнюю часть графика, мы действительно увидим, что узел CheckBounds теперь был заменен узлом CheckedUint32Bounds в соответствии с кодом, а значения всех остальных узлов были «понижены» до представления машинного кода.

Устранение избыточности
Другой популярный класс оптимизаций, похожий на BCE, называется устранением избыточности. Код для него находится в файле v8/src/compiler/redundancy-elimination.cc и отвечает за удаление избыточных проверок типов. Класс RedundancyElimination - это, по сути, редуктор графа, который пытается либо удалить, либо объединить избыточные проверки в цепочке эффектов. Цепочка эффектов - это в основном порядок операций между ребрами эффектов для функций load и store. Например, если мы пытаемся загрузить свойство из объекта и попытаться добавить к нему, например, obj[x] = obj[x] + 1, то наша цепочка эффектов будет JSLoadNamed => SpeculativeSafeIntegerAdd => JSStoreNamed. TurboFan должен убедиться, что эти внешние эффекты узлов не переупорядочиваются, иначе мы можем получить неправильную защиту. Редуктор, как подробно описано в v8/src/compiler/graph-reducer.h, пытается упростить данный узел на основе его оператора и входов. Существует несколько типов редукторов, таких как складывание констант, когда если мы складываем две константы друг с другом, мы складываем их в одну, т.е. 3 + 5 теперь будет просто одним узлом константы 8, и уменьшение силы, когда если значение добавляется к узлу без эффектов, мы сохраняем один узел, т.е. x + 0 будет просто узлом x.
Мы можем проследить эти типы сокращений с помощью флага --trace_turbo_reduction. Если мы снова запустим нашу функцию hot_function с этим флагом, то получим такой результат.
Этот флаг выводит много интересных результатов, и, как вы можете видеть, выполняется множество различных редукторов и исключений. Мы кратко рассмотрим некоторые из них позже в этом посте, но я хочу, чтобы вы внимательно посмотрели на некоторые из этих сокращений.
Например, этот:
Да, вы правильно прочитали - CheckMaps был обновлен и позже заменен из-за использования RedundancyElimination. Это произошло потому, что устранение избыточности обнаружило, что вызов CheckMaps был избыточной проверкой, и удалило все, кроме первой, в том же пути потока управления. В этот момент я знаю, что некоторые из вас могут подумать: "Разве это не уязвимость безопасности"? Ответ на этот вопрос - "потенциально" и "зависит от ситуации".
Прежде чем я объясню это более подробно, давайте рассмотрим следующий пример кода:
Как видите, этот код довольно прост. Он принимает один объект и возвращает сумму значений из свойств a и b. Если мы посмотрим на граф оптимизации Typer, то увидим следующее.

Как вы можете видеть, когда мы входим в нашу функцию, мы сначала вызываем CheckMaps, чтобы проверить, что карта объекта, который мы передаем, соответствует наличию свойств a и b. Если проверка пройдена, мы вызываем LoadField для загрузки смещения 12 из константы Parameter, которое является свойством a из объекта obj, который мы передали. Сразу после этого мы выполняем еще один вызов CheckMaps, чтобы снова проверить карту, а затем загружаем свойство b. После этого мы вызываем функцию JSAdd, чтобы сложить числа, строки или и то, и другое вместе. Проблема здесь заключается в избыточном вызове CheckMaps, поскольку, как мы знаем, карта этого объекта, которую мы передаем, не может измениться между двумя операциями CheckMap. В этом случае она будет удалена.
Мы можем видеть это устранение избыточности в упрощенной нижней фазе графа.

Как вы можете видеть, второй узел CheckMaps теперь удален, и после первой проверки мы просто загружаем оба свойства одно за другим - по сути, ускоряя наш код. Также, благодаря упрощению, вызов JSAdd был опущен до варианта машинного кода для проверки целочисленных и строковых выражений в соответствии со стандартом ECMAScript. Итак, возвращаясь к нашему вопросу о том, является ли это уязвимостью безопасности или нет. Как уже было сказано, "это зависит". Причина в том, что определенные операции могут вызвать побочные эффекты для наблюдаемого выполнения нашего контекста - вот почему у нас есть цепочки побочных эффектов. Если TurboFan по какой-то причине забыл учесть побочный эффект и не записал его в цепочку побочных эффектов, то возможно, что карта объекта может измениться во время выполнения, например, другой вызов пользовательской функции изменит объект или добавит свойство. Каждая операция промежуточного представления в V8 имеет различные флаги, связанные с ней. Пример некоторых флагов для операторов JavaScript можно увидеть в v8/src/compiler/js-operator.cc Некоторые из этих флагов имеют определенные предположения. Например, V(ToString, Operator::kNoProperties, 1, 1) предполагает, что строка не должна иметь свойств. Другой флаг, например V(LoadMessage, Operator::kNoThrow | Operator::kNoWrite, 0, 1), предполагает, что операция LoadMessage не будет иметь наблюдаемых побочных эффектов через флаг kNoWrite. Этот флаг kNoWrite фактически не записывает в цепочку эффектов. Как видите, если мы можем заставить компилятор удалить проверку избыточности для операции, которая, похоже, считает, что у нее нет побочных эффектов, то у вас есть потенциально эксплуатируемая ошибка, если вы можете изменить объект или свойство во время выполнения скомпилированного кода. Эта тема об устранении избыточности и побочных эффектов может быть расширена, чтобы обсудить, как ошибки, возникающие в результате этих проверок устранения избыточности, могут привести к уязвимостям, которые можно использовать. Но прежде чем мы это сделаем, давайте вкратце рассмотрим некоторые другие распространенные оптимизации.
Другие оптимизации
Как видно из вывода флага --trace_turbo_reduction, существует гораздо больше оптимизаций, которые происходят в TurboFan, чем те, о которых мы говорили. Я постарался рассказать о наиболее важных из них, связанных с ошибкой, которую мы будем эксплуатировать в части 3, но я все же хочу быстро рассказать о некоторых других оптимизациях, чтобы вы хотя бы в общих чертах понимали, что это такое.
Ниже перечислены некоторые другие общие оптимизации, которые вы увидите в TurboFan:
Оптимизация управления: Как определено в v8/src/compiler/control-flow-optimizer.cc, эта оптимизация обычно работает над оптимизацией потока графа и превращает определенные цепочки ветвей в переключатели.
Анализ псевдонимов и глобальная нумерация значений: Анализ псевдонимов выявляет зависимости между узлами Store и Load. Так, если две операции загрузки зависят от одной, они не могут быть выполнены до завершения первой операции, т.е. x = 2; y = x + 2; z = x + 2. GVN, или глобальная нумерация значений, следует за номером и удаляет избыточные операции хранения и загрузки, т.е. z = x + 2 может быть удалено, а z может быть установлено в y, поскольку эта операция является избыточной.
Устранение мертвого кода (DCE): Устранение мертвого кода - это именно то, что звучит. Он просто перебирает все узлы и удаляет код, который не будет выполнен. Например, если x и y для утверждения True/False всегда истинны, то ложный путь будет считаться "мертвым" и удален.
Если вы хотите узнать больше о различных оптимизациях и узнать больше о море узлов, я советую прочитать "TurboFan JIT Design" и "Введение в TurboFan".
Общие уязвимости JIT-компилятора
Имея представление о полном конвейере V8 и оптимизациях компилятора, мы можем теперь начать изучать и понимать, какие классы уязвимостей присутствуют в браузерах. Как мы знаем, движок JavaScript и все его компоненты, такие как компилятор, реализованы на C++. В этом случае конвейер в первую очередь уязвим к обычным нарушениям памяти и безопасности типов, таким как переполнения и недополнения целых чисел, ошибки off-by-one, запрещенные чтения и записи, переполнения буфера, переполнения кучи, и, конечно же, ошибки use-after-free и другие. В дополнение к обычным ошибкам C++, мы также можем иметь логические ошибки и ошибки генерации машинного кода, которые могут возникнуть на этапе оптимизации из-за природы спекулятивных предположений. Такие логические ошибки могут возникать из-за неправильного предположения о потенциальных побочных эффектах, которые операция может оказать на объект или свойство, или из-за неправильных проходов оптимизации, которые удаляют критические защиты типов.
ПЕРЕВЕДЕНО СПЕЦИАЛЬНО ДЛЯ xss.pro
$600 на SSD для Jolah Milovski ---> 0x5B1f2Ac9cF5616D9d7F1819d1519912e85eb5C09 для поднятия ноды ETHEREUM и тестов
Сегодня мы вернёмся к конвейеру компилятора и расширим некоторые понятия, о которых мы говорили, такие как байткод V8, компиляция кода и оптимизация кода. В целом, в этом посте мы глубоко погрузимся в понимание того, что происходит под капотом в Ignition, Sparkplug и TurboFan, поскольку они имеют решающее значение для нашего понимания того, как определенные "особенности" могут привести к эксплуатируемым ошибкам.
Будут рассмотрены следующие темы:
Модель безопасности Chrome
Архитектура многопроцессной песочницы
Изоляция и контекст в V8
Интерпретатор Ignition
Понимание байткода V8
Понимание машины на основе регистров
Sparkplug
Сопоставление 1:1
TurboFan
Компиляция точно в срок (JIT)
Спекулятивная оптимизация и защита типов
Решетка обратной связи
"Море узлов" Промежуточное представление (IR)
Общие оптимизации
Типизатор
Анализ диапазона
Устранение проверки границ (BCE)
Устранение избыточности
Другие оптимизации
Оптимизация управления
Анализ псевдонимов и нумерация глобальных значений
Устранение мертвого кода (DCE)
Общие уязвимости JIT-компилятора
Модель безопасности Chrome
Прежде чем мы погрузимся в понимание сложности конвейера компилятора, того, как он выполняет оптимизацию и где могут появляться ошибки, нам сначала нужно сделать шаг назад и посмотреть на общую картину. Хотя конвейер компилятора играет большую роль в выполнении JavaScript, он является лишь одним из кусочков головоломки в целой архитектуре браузеров.
Как мы уже видели, V8 может работать как отдельное приложение, но когда речь идет о браузере в целом, V8 фактически встроен в Chrome и затем используется через привязки другим движком. В связи с этим существуют нюансы и определенные последствия, о которых мы должны знать, как обрабатывается код JavaScript в приложении, поскольку эта информация имеет решающее значение для понимания проблем безопасности в браузере.
Чтобы увидеть эту "общую картину" и собрать воедино все части головоломки, нам нужно начать с понимания модели безопасности Chrome. Эта серия статей в блоге - путешествие по внутренностям и эксплуатации браузера, в конце концов. Итак, чтобы лучше понять, почему некоторые ошибки более тривиальны, чем другие, и почему эксплуатация только одной ошибки может не привести к прямому удаленному выполнению кода, нам нужно понять архитектуру Chromium.
Как мы знаем, JavaScript-движки являются неотъемлемой частью выполнения JavaScript-кода на системах. Хотя они играют большую роль в обеспечении быстродействия и эффективности браузеров, они также могут открывать браузер для сбоев, зависаний приложений и даже угроз безопасности. Но JavaScript-движки - не единственная часть браузера, которая может иметь проблемы или уязвимости. Многие другие компоненты, такие как API или используемые движки рендеринга HTML и CSS, также могут иметь проблемы со стабильностью и уязвимости, которые потенциально могут быть использованы - намеренно или нет. Сейчас практически невозможно создать JavaScript или движок рендеринга, который никогда не даст сбой. И также практически невозможно создать такие движки, которые были бы надежно защищены от ошибок и уязвимостей - особенно потому, что большинство этих компонентов программируются на статически типизированном языке C++, который должен справляться с динамической природой веб-приложений.Как же Chrome справляется с такой "невыполнимой" задачей, пытаясь поддерживать эффективную работу браузера и одновременно обеспечивая безопасность браузера, системы и пользователей? Двумя способами - с помощью многопроцессной архитектуры и "песочницы".
Многопроцессная архитектура песочницы
Многопроцессная архитектура Chromium - это именно такая архитектура, которая использует несколько процессов для защиты браузера от проблем нестабильности и ошибок, которые могут возникнуть в JavaScript-движке, движке рендеринга или других компонентах. Chromium также ограничивает доступ между каждым из этих процессов, позволяя только определенным процессам общаться друг с другом. Этот тип архитектуры можно рассматривать как включение защиты памяти и контроля доступа в приложение. В целом, браузеры имеют один основной процесс, который запускает пользовательский интерфейс и управляет всеми остальными процессами - он известен как "процесс браузера" или сокращенно "браузер". Очень уникально, я знаю. Процессы, которые обрабатывают веб-контент, известны как "процессы рендеринга" или "рендереры". Эти процессы рендеринга используют нечто под названием Blink - это движок рендеринга с открытым исходным кодом, используемый в Chrome. В Blink реализовано множество других библиотек, которые помогают ему работать, например, Skia, которая является открытой библиотекой 2D графики, и, конечно же, V8 для JavaScript. И вот здесь все становится немного сложнее. В Chrome каждое новое окно или вкладка открывается в новом процессе, который обычно является новым процессом рендеринга. Этот новый процесс рендеринга имеет глобальный объект RenderProcess, который управляет связью с родительским процессом браузера и поддерживает глобальное состояние веб-страницы или приложения в этом окне или вкладке. В свою очередь, главный процесс браузера будет поддерживать соответствующий объект RenderProcessHost для каждого рендерера, который управляет состоянием браузера и коммуникацией для рендерера. Для связи между каждым из этих процессов Chromium использует либо унаследованную систему IPC, либо Mojo.
Помимо того, что каждый из этих рендереров находится в собственном процессе, Chrome также использует возможность ограничить доступ процессов к системным ресурсам с помощью "песочницы". Создавая "песочницу" для каждого процесса, Chrome может гарантировать, что доступ к сетевым ресурсам рендерера будет осуществляться только через диспетчер сетевых служб, запущенный в основном процессе. Кроме того, он может ограничить доступ процессов к файловой системе, а также к дисплею пользователя, файлам cookie и вводимым данным.
В целом, это ограничивает возможности злоумышленника, если он получит удаленное выполнение кода в процессе рендеринга. По сути, они не смогут внести постоянные изменения в компьютер или получить доступ к такой информации, как пользовательский ввод и cookies в других окнах и вкладках без использования или цепочки других ошибок для выхода из этой песочницы.
Я не буду вдаваться в подробности, поскольку это отвлечет от текущей темы статьи в блоге. Но я настоятельно рекомендую вам подробно ознакомиться с документацией "Chromium Windows Sandbox Architecture", чтобы не только понять принципы проектирования, но и лучше понять схему взаимодействия брокера и целевого процесса.
Как же это выглядит на практике? Мы можем увидеть практический пример этого, запустив Chrome, открыв две вкладки и запустив Process Monitor. Сначала мы увидим, что в Chrome есть один родительский или "браузерный" процесс и несколько дочерних процессов, как показано ниже.
Теперь, если мы заглянем в основной родительский процесс и сравним его с дочерним процессом, мы заметим, что другие процессы выполняются с другими параметрами командной строки. В этом примере мы видим, что дочерний процесс (справа) относится к типу средства визуализации и соответствует родительскому процессу браузера (слева). Круто, правда?
Хорошо, после всего этого я знаю, что вы можете спросить меня, какое отношение все это имеет к V8 и JavaScript? Ну, если вы были внимательны, то заметили ключевой момент, когда я говорил о движке рендеринга Chromes, Blink. И это тот факт, что он реализует V8. Если вы нашли время прочитать документацию по Blink, то вы бы узнали немного о Blink. В документации говорится, что Blink запускается в каждом процессе рендеринга и имеет один основной поток, который обрабатывает JavaScript, DOM, CSS, вычисления стилей и макетов. Кроме того, Blink может создавать несколько "рабочих" потоков для запуска дополнительных скриптов, расширений и т.д. В целом, каждый поток Blink запускает свой собственный экземпляр V8. Почему? Как вы знаете, в отдельном окне браузера или вкладке может выполняться множество JavaScript-кода, причем не только для страницы, но и в различных iframe для таких вещей, как реклама, кнопки и т.д. В конце концов, каждый из этих скриптов и iframe имеют отдельные контексты JavaScript, и должен быть способ предотвратить манипуляции одного скрипта с объектами другого. Чтобы помочь "изолировать" контекст одного скрипта от другого, в V8 реализовано нечто известное как Isolate and Context, о чем мы сейчас и поговорим.
Изоляция и контекст в V8
В V8 Isolate - это просто концепция экземпляра или "виртуальной машины", которая представляет одну среду выполнения JavaScript, включая менеджер кучи, сборщик мусора и т.д. В Blink изоляты и потоки имеют соотношение 1:1, где один изолят связан с главным потоком, а один изолят связан с одним рабочим потоком. Итак, Context соответствует глобальному корневому объекту, который хранит состояние виртуальной машины и используется для компиляции и выполнения сценариев в одном экземпляре V8. Грубо говоря, один объект окна соответствует одному контексту, а поскольку каждый кадр имеет объект окна, в процессе рендеринга потенциально существует несколько контекстов. По отношению к изоляту, изолят и контексты имеют отношения 1:N на протяжении всего времени существования изолята - когда конкретный изолят или экземпляр будет интерпретировать и компилировать несколько контекстов. Это означает, что каждый раз, когда необходимо выполнить JavaScript, мы должны убедиться, что находимся в правильном контексте с помощью GetCurrentContext(), иначе произойдет утечка объектов JavaScript или их перезапись, что потенциально может вызвать проблемы безопасности. В Chrome объект времени выполнения v8::Isolate реализован в v8/include/v8-isolate.h, а объект v8::Context - в v8/include/v8-context.h. Используя то, что мы знаем, на высоком уровне мы можем представить себе согласованность времени выполнения и контекста в Chrome следующим образом:
Если вы хотите узнать больше о том, как работают эти Isolates и Context, то советую прочитать "Design of V8 Bindings" и "Getting Started with Embedding V8".
Интерпретатор Ignition
Теперь, когда мы имеем общее представление об архитектуре Chromium и понимаем, что весь код JavaScript не выполняется в одном и том же экземпляре движка V8, мы можем, наконец, вернуться к конвейеру компилятора и продолжить наше глубокое погружение.
Мы начнем с интерпретатора V8, Ignition.
В качестве напоминания о первой части, давайте вернемся к нашему высокоуровневому обзору конвейера компиляции V8, чтобы знать, где мы находимся в этом конвейере.
В первой части мы уже рассмотрели токены и абстрактные синтаксические деревья (AST), а также кратко объяснили, как AST разбирается и затем переводится в байткод в интерпретаторе. Теперь я хочу рассказать о байткоде V8, поскольку байткод, создаваемый интерпретатором, является важнейшим строительным блоком, из которого состоит любая функциональность JavaScript. Кроме того, когда Ignition компилирует байткод, он также собирает данные профилирования и обратной связи каждый раз, когда выполняется функция JavaScript. Эти данные обратной связи затем используются TurboFan для генерации JIT-оптимизированного машинного кода. Но прежде чем мы начнем понимать, как структурирован байткод, нам нужно сначала понять, как Ignition реализует свою "регистровую машину". Причина в том, что каждый байткод определяет свои входы и выходы как операнды регистра, поэтому нам нужно знать, где эти входы и выходы будут находиться в стеке. Это также поможет нам в дальнейшей визуализации и понимании стековых фреймов, которые создаются в V8.
Понимание машины на основе регистров
Как мы знаем, интерпретатор Ignition - это интерпретатор на основе регистров с регистром-аккумулятором. Эти "регистры" на самом деле не являются традиционными машинными регистрами, как можно было бы подумать. Вместо этого они представляют собой определенные слоты в регистровом файле, который выделяется как часть стековой рамки функции - по сути, это "виртуальные" регистры. Как мы увидим позже, байткоды могут указывать эти входные и выходные регистры, над которыми будут работать их аргументы.
Ignition состоит из набора обработчиков байткода, которые написаны на ассемблере высокого уровня, не зависящем от машины. Эти обработчики реализуются классом CodeStubAssembler и компилируются с помощью бэкенда TurboFan при компиляции браузера. В целом, каждый из этих обработчиков "обрабатывает" определенный байткод, а затем пересылает соответствующий обработчик следующему байткоду. Пример обработчика байткода LdaZero или "Load Zero to Accumulator" из v8/src/interpreter/interpreter-generator.cc можно увидеть ниже.
Код:
// LdaZero
// Load literal '0' into the accumulator.
IGNITION_HANDLER(LdaZero, InterpreterAssembler)
{
TNode<Number> zero_value = NumberConstant(0.0);
SetAccumulator(zero_value);
Dispatch();
}Когда V8 создает новый изолят, он загружает обработчики из файла моментального снимка, который был создан во время сборки. Изолят также содержит глобальную таблицу диспетчеризации интерпретатора, в которой хранится указатель объекта кода на каждый обработчик байткода, индексированный по значению байткода. Как правило, эта диспетчерская таблица представляет собой просто перечисление. Для того чтобы байткод мог быть запущен Ignition, функция JavaScript сначала переводится в байткод из своего AST генератором байткода. Этот генератор проходит по AST и выдает соответствующий байткод для каждого узла AST, вызывая функцию GenerateBytecode. Этот байткод затем ассоциируется с функцией (которая является объектом JSFunction) в поле свойств, известном как объект SharedFunctionInfo. После этого кодовая_точка_входа JavaScript-функции устанавливается на встроенную заглушку InterpreterEntryTrampoline. Заглушка InterpreterEntryTrampoline вводится при вызове функции JavaScript и отвечает за установку соответствующего стекового кадра интерпретатора, а также за отправку обработчику байткода интерпретатора для первого байткода функции. Затем начинается выполнение или "интерпретация" функции Ignition, которая обрабатывается в исходном файле v8/src/builtins/x64/builtins-x64.cc. В частности, на строках 1255 - 1387 в файле builtins-x64.cc функции Builtins::Generate_InterpreterPushArgsThenCallImpl и Builtins::Generate_InterpreterPushArgsThenConstructImpl отвечают за дальнейшее построение стекового кадра интерпретатора, проталкивая аргументы и состояние функции в стек. Я не буду слишком подробно останавливаться на генераторе байткода, но если вы хотите расширить свои знания, то советую прочитать раздел "Ignition Design Documentation: Генерация байткода", чтобы лучше понять, как он работает под капотом. В этом разделе я хочу сосредоточиться на распределении регистров и создании стековой рамки для функции.
Как же создается эта стековая рамка?
Ну, во время генерации байткода BytecodeGenerator также выделяет регистры в регистровом файле функции для локальных переменных, указателей объектов контекста и временных значений, необходимых для оценки выражения. Заглушка InterpreterEntryTrampoline обрабатывает начальное построение стекового кадра, а затем выделяет место в стековом кадре для регистрового файла. Эта заглушка также запишет undefined во все регистры в этом регистровом файле, чтобы сборщик мусора (GC) не увидел недопустимых (т.е. немаркированных) указателей при проходе по стеку.
Байткод будет работать с этими регистрами, указывая их в своих операндах, а Ignition затем загрузит или сохранит данные из определенного слота стека, связанного с регистром. Поскольку индексы регистров отображаются непосредственно на слоты стекового фрейма функции, Ignition может напрямую обращаться к другим слотам стека, таким как контекст и аргументы, которые были переданы вместе с функцией. Пример того, как выглядит стековый фрейм функции (предоставленный командой Chromium), можно увидеть ниже. Обратите внимание на "стековую рамку интерпретатора". Это стековый фрейм, который строится батутом InterpreterEntryTrampoline.
Как видите, у нас аргументы функций выделены красным цветом, а локальные переменные и временные переменные для вычисления выражений — зеленым. Светло-зеленая часть содержит объект текущего контекста Isolates, счетчик указателя вызывающей стороны и указатель на объект JSFunction. Этот указатель на JSFunction также известен как замыкание, которое ссылается на контекст функций, объект SharedFunctionInfo, а также на другие средства доступа, такие как FeedbackVector. Пример того, как эта JSFunction выглядит в памяти, можно увидеть ниже.
Вы также можете заметить, что в кадре стека нет регистра-аккумулятора. И причина этого в том, что регистр накопителя будет постоянно изменяться во время вызовов функций, в этом случае он хранится в интерпретаторе как регистр состояния. На этот регистр состояния указывает указатель кадра (FP), который также содержит указатель стека и счетчик кадров.
Возвращаясь к первому примеру стековой рамки, вы также заметите, что там есть указатель Bytecode Array, который представляет собой последовательность байткодов интерпретатора для данной конкретной функции в пределах стековой рамки. Изначально каждый байткод представляет собой перечисление, где индекс байткода хранит соответствующий обработчик - как объяснялось ранее.
Пример такого BytecodeArray можно увидеть в v8/src/objects/code.h, а фрагмент этого кода приведен ниже.
Код:
// BytecodeArray представляет последовательность байткодов интерпретатора.
class BytecodeArray
: public TorqueGeneratedBytecodeArray<BytecodeArray, FixedArrayBase> {
public:
static constexpr int SizeFor(int length) {
return OBJECT_POINTER_ALIGN(kHeaderSize + length);
}
inline byte get(int index) const;
inline void set(int index, byte value);
inline Address GetFirstBytecodeAddress();
inline int32_t frame_size() const;
inline void set_frame_size(int32_t frame_size);Как вы видите, функция GetFirstBytecodeAddress() отвечает за получение первого адреса байткода в массиве. Как же она находит этот адрес?
Давайте посмотрим на байткод, сгенерированный для var num = 42.
Код:
d8>
d8> var num = 42;
[generated bytecode for function: (0x03650025a599 <SharedFunctionInfo>)]
Bytecode length: 18
Parameter count 1
Register count 3
Frame size 24
Bytecode age: 0
000003650025A61E @ 0 : 13 00 LdaConstant [0]
000003650025A620 @ 2 : c4 Star1
000003650025A621 @ 3 : 19 fe f8 Mov <closure>, r2
000003650025A624 @ 6 : 66 5f 01 f9 02 CallRuntime [DeclareGlobals], r1-r2
000003650025A629 @ 11 : 0d 2a LdaSmi [42]
000003650025A62B @ 13 : 23 01 00 StaGlobal [1], [0]
000003650025A62E @ 16 : 0e LdaUndefined
000003650025A62F @ 17 : aa ReturnНе беспокойтесь о том, что означает каждый из этих байткодов, мы объясним это чуть позже. Посмотрите на 1-ю строку в массиве байткодов, она хранит LdaConstant. Слева от нее мы видим 13 00. Шестнадцатеричное число 0x13 - это перечислитель байткода, который представляет собой место, где будет находиться обработчик для этого байткода.
Как только это получено, будет вызвана функция SetBytecodeHandler() с байткодом, операндами и перечислением обработчиков. Эта функция находится в файле v8/src/interpreter/interpreter.cc; пример этой функции показан ниже.
Код:
void Interpreter::SetBytecodeHandler(Bytecode bytecode,
OperandScale operand_scale,
CodeT handler) {
DCHECK(handler.is_off_heap_trampoline());
DCHECK(handler.kind() == CodeKind::BYTECODE_HANDLER);
size_t index = GetDispatchTableIndex(bytecode, operand_scale);
dispatch_table_[index] = handler.InstructionStart();
}size_t Interpreter::GetDispatchTableIndex(Bytecode bytecode,
OperandScale operand_scale) {
static const size_t kEntriesPerOperandScale = 1u << kBitsPerByte;
size_t index = static_cast<size_t>(bytecode);
return index + BytecodeOperands::OperandScaleAsIndex(operand_scale) *
kEntriesPerOperandScale;
}Как вы можете видеть, dispatch_table_[index] вычислит индекс байткода из таблицы диспетчеризации, которая хранится в физическом регистре, и в конечном итоге это инициирует или завершит функцию Dispatch() для выполнения байткода. Массив байткода также содержит нечто, называемое "указатель пула констант", в котором хранятся объекты кучи, на которые ссылаются как на константы в сгенерированном байткоде, такие как строки и целые числа. Пул констант представляет собой фиксированный массив указателей на объекты кучи. Пример указателя BytecodeArray и его константного пула объектов кучи показан ниже.
Прежде чем мы продолжим, хочу упомянуть еще одну вещь: в заглушке InterpreterEntryTrampoline есть некоторые фиксированные машинные регистры, которые используются Ignition. Эти регистры находятся в файле v8/src/codegen/x64/register-x64.h.
Пример этих регистров можно увидеть ниже, а к тем, которые представляют интерес, добавлены комментарии.
Код:
// Define {RegisterName} methods for the register types.
DEFINE_REGISTER_NAMES(Register, GENERAL_REGISTERS)
DEFINE_REGISTER_NAMES(XMMRegister, DOUBLE_REGISTERS)
DEFINE_REGISTER_NAMES(YMMRegister, YMM_REGISTERS)
// Give alias names to registers for calling conventions.
constexpr Register kReturnRegister0 = rax;
constexpr Register kReturnRegister1 = rdx;
constexpr Register kReturnRegister2 = r8;
constexpr Register kJSFunctionRegister = rdi;
// Points to the current context object
constexpr Register kContextRegister = rsi;
constexpr Register kAllocateSizeRegister = rdx;
// Stores the implicit accumulator interpreter register
constexpr Register kInterpreterAccumulatorRegister = rax;
// The current offset of execution in the BytecodeArray
constexpr Register kInterpreterBytecodeOffsetRegister = r9;
// Points the the start of the BytecodeArray object which is being interpreted
constexpr Register kInterpreterBytecodeArrayRegister = r12;
// Points to the interpreter’s dispatch table, used to dispatch to the next bytecode handler
constexpr Register kInterpreterDispatchTableRegister = r15;Теперь, когда мы это поняли, пришло время разобраться в том, как выглядит байткод V8 и как операнд байткода взаимодействует с регистровым файлом.
Понимание байткода V8
Как говорилось в первой части, в V8 существует несколько сотен байткодов, и все они определены в заголовочном файле v8/src/interpreter/bytecodes.h. Как мы увидим через минуту, каждый из этих байткодов определяет свои входные и выходные операнды как регистры в регистровом файле. Кроме того, многие опкоды начинаются с Lda или Sta в названии, где a означает аккумулятор.
Например, приведем определение байткода для LdaSmi:
Код:
V(LdaSmi, ImplicitRegisterUse::kWriteAccumulator, OperandType::kImm)Как вы видите, LdaSmi "загружает" (отсюда Ld) значение в регистр аккумулятора. В данном случае он загружает операнд kImm, который представляет собой подписанный байт, что совпадает с Smi или Small Integer в имени байткода. В общем, этот байткод загрузит в регистр аккумулятора маленькое целое число.
Обратите внимание, что список операндов и их типы определены в заголовочном файле v8/src/interpreter/bytecode-operands.h.
Итак, вооружившись этой базовой информацией, давайте посмотрим на байткод одной из функций JavaScript. Для начала запустим d8 с флагом --print-bytecode, чтобы мы могли увидеть байткод. Как только это будет сделано, просто введите произвольный код JavaScript и нажмите Enter несколько раз. Причина этого в том, что V8 - "ленивый" движок, поэтому он не будет компилировать то, что ему не нужно. Но поскольку мы впервые используем строки и числа, он будет компилировать такие библиотеки, как Stringify, что приведет к огромному количеству вывода.
После этого давайте создадим простую функцию JavaScript под названием incX, которая будет увеличивать свойство x объекта на единицу и возвращать его нам. Функция должна выглядеть следующим образом.
Код:
function incX(obj) { return 1 + obj.x; }Это сгенерирует некоторый байткод, но не будем об этом беспокоиться. Теперь, когда у нас это есть, давайте вызовем эту функцию с объектом, у которого свойству x присвоено значение, и посмотрим сгенерированный байткод.
Код:
d8> incX({x:13});
...
[generated bytecode for function: incX (0x026c0025ab65 <SharedFunctionInfo incX>)]
Bytecode length: 11
Parameter count 2
Register count 1
Frame size 8
Bytecode age: 0
0000026C0025ACC6 @ 0 : 0d 01 LdaSmi [1]
0000026C0025ACC8 @ 2 : c5 Star0
0000026C0025ACC9 @ 3 : 2d 03 00 01 GetNamedProperty a0, [0], [1]
0000026C0025ACCD @ 7 : 39 fa 00 Add r0, [0]
0000026C0025ACD0 @ 10 : aa Return
Constant pool (size = 1)
0000026C0025AC99: [FixedArray] in OldSpace
- map: 0x026c00002231 <Map(FIXED_ARRAY_TYPE)>
- length: 1
0: 0x026c000041ed <String[1]: #x>
Handler Table (size = 0)
Source Position Table (size = 0)
14Мы проигнорируем большую часть вывода и сосредоточимся только на разделе байт-кода. Но прежде чем мы это сделаем, обратите внимание, что этот байт-код находится в объекте SharedFunctionInfo, что совпадает с нашим объяснением ранее! Для начала мы видим, что LdaSmi вызывается для загрузки небольшого целого числа в регистр-аккумулятор, значение которого будет равно 1. Затем мы вызываем Star0, который будет хранить (отсюда st) значение в аккумуляторе (в соответствии с a) в регистре r0. Итак, в этом случае мы перемещаем 1 в r0.
Код:
- length: 1
0: 0x026c000041ed <String[1]: #x>Короче говоря, это байт-код, который загружает obj.x. Другой операнд [0] известен как вектор обратной связи, который содержит информацию о времени выполнения и данные о форме объекта, которые используются для оптимизации TurboFan. Затем мы добавляем значение регистра r0 в аккумулятор, в результате чего получается значение 14. Наконец, мы вызываем Return, который возвращает значение аккумулятора, и выходим из функции. Чтобы помочь вам визуализировать это во фрейме стека, я предоставил GIF того, что происходит в упрощенном стеке с каждой инструкцией байт-кода.
Как видите, хотя байткоды немного загадочны, как только мы поймем, что делает каждый из них, их будет довольно легко понять и следовать за ними. Если вы хотите узнать больше о байткоде V8, я советую прочитать "JavaScript Bytecode - v8 Ignition Instructions", где рассматривается значительная часть различных операций.
Sparkplug
Теперь, когда у нас есть достаточное понимание того, как Ignition генерирует и выполняет ваш JavaScript-код в виде байткода, самое время начать изучать компиляционную часть конвейера компилятора V8. Мы начнем со Sparkplug, поскольку его довольно легко понять, так как он вносит лишь небольшие изменения в уже сгенерированный байткод и стек в целях оптимизации.
Как мы знаем из первой части, Sparkplug - это очень быстрый неоптимизирующий компилятор V8, который находится между Ignition и TurboFan. По сути, Sparkplug - это не совсем компилятор, а скорее транспилятор, который преобразует байткод Ignitions в машинный код, чтобы запустить его нативно. Кроме того, это неоптимизирующий компилятор, поэтому он не делает очень специфических оптимизаций, так как это делает TurboFan. Итак, что же делает Sparkplug таким быстрым? Ну, Sparkplug быстр, потому что он обманывает. Функции, которые он компилирует, уже были скомпилированы в байткод, и, как мы знаем, Ignition уже проделал тяжелую работу по разрешению переменных, потоку управления и т.д. В этом случае Sparkplug компилирует из байткода, а не из исходников JavaScript.
Во-вторых, Sparkplug не создает никакого промежуточного представления (IR), как это делают большинство компиляторов (о чем мы узнаем позже). В данном случае Sparkplug компилирует непосредственно в машинный код за один линейный проход над байткодом. В общем случае это известно как отображение 1:1. Забавно то, что Sparkplug - это просто оператор switch внутри цикла for, который отправляет фиксированный байткод, а затем генерирует машинный код. Мы можем увидеть эту реализацию в исходном файле v8/src/baseline/baseline-compiler.cc.
Пример функции генерации машинного кода Sparkplug можно увидеть ниже.
Код:
switch (iterator().current_bytecode()) {
#define BYTECODE_CASE(name, ...) \
case interpreter::Bytecode::k##name: \
Visit##name(); \
break;
BYTECODE_LIST(BYTECODE_CASE)
#undef BYTECODE_CASE
}Как же Sparkplug генерирует этот машинный код? Ну, конечно же, он делает это, снова обманывая. Sparkplug генерирует очень мало собственного кода, вместо этого Sparkplug просто вызывает встроенные модули байткода, которые обычно вводятся InterpreterEntryTrampoline и затем обрабатываются в v8/src/builtins/x64/builtins-x64.cc. Если вы вспомните наш объект JSFunction во время разговора о Ignition, вы вспомните, что закрытие связывалось с "оптимизированным кодом". По сути, Sparkplug будет хранить там встроенный модуль байткода, и когда функция будет выполнена, вместо диспетчеризации к байткоду мы вызовем встроенный модуль напрямую. В этот момент вы можете подумать, что Sparkplug - это, по сути, прославленный интерпретатор, и вы не ошибетесь. Sparkplug практически просто сериализует выполнение интерпретатора, вызывая те же самые встроенные модули. Но это позволяет функции JavaScript быть быстрее, потому что таким образом мы можем избежать накладных расходов интерпретатора, таких как декодирование опкодов и поиск диспетчеризации байткода, что позволяет нам сократить использование процессора, перейдя от эмуляционного движка к нативному исполнению.
Чтобы узнать немного больше о том, как работают эти встроенные модули, я рекомендую прочитать "Короткие вызовы встроенных модулей".
Сопоставление 1:1
Сопоставление 1:1 в Sparkplug связано не только с тем, как он компилирует байткод Ignition в машинный код; оно также связано с фреймами стека. Как мы знаем, каждая часть конвейера компилятора должна хранить состояние функции. И как мы уже видели в V8, состояния функций JavaScript хранятся в стековых фреймах Ignition путем хранения текущей вызываемой функции, контекста, с которым она вызывается, количества переданных аргументов, указателя на массив байткода и так далее и тому подобное. Теперь, как мы знаем, Ignition - это интерпретатор на основе регистров, имеющий виртуальные регистры, которые используются для аргументов функций и в качестве входов и выходов для операндов байткода. Чтобы Sparkplug был быстрым и не занимался собственным распределением регистров, он использует регистровые фреймы Ignition, что, в свою очередь, позволяет Sparkplug зеркально отражать поведение интерпретатора и его стек. Это позволяет Sparkplug не нуждаться в каком-либо сопоставлении между двумя фреймами, что делает эти стековые фреймы почти 1:1 совместимыми. Обратите внимание, что я говорю "почти 1:1 совместимы", есть одно небольшое различие между стековыми фреймами Ignition и Sparkplug. Это отличие заключается в том, что Sparkplug не нужно сохранять слот смещения байткода в регистровом файле, поскольку код Sparkplug испускается непосредственно из байткода. Вместо этого он заменяет его кэшированным вектором обратной связи.
Пример сравнения этих двух стековых фреймов можно увидеть на изображении ниже, предоставленном документацией Ignition.
Так почему же Sparkplug должен создавать и поддерживать схему каркаса стека, аналогичную Ignitions? По одной причине, и по основной причине того, как работают Sparkplug и Turbofan, делая нечто, называемое заменой на стеке (OSR). OSR - это возможность заменить текущий выполняющийся код на другую версию. В данном случае, когда Ignition видит, что функция JavaScript используется часто, он отправляет ее в Sparkplug для ускорения. Как только Sparkplug сериализует байткоды в свои встроенные модули, он заменит стек интерпретаторов для этой конкретной функции. Когда стек будет пройден и выполнен, код перейдет непосредственно в Sparkplug вместо того, чтобы выполняться на эмулированном стеке Ignitions. А поскольку кадры "зеркально отражены", это технически позволяет V8 переключаться между кодом интерпретатора и Sparkplug почти с нулевыми накладными расходами на перевод кадров. Прежде чем мы продолжим, я хочу обратить внимание на аспект безопасности Sparkplug. В целом, маловероятно, что в самом сгенерированном коде есть проблемы с безопасностью. Больший риск безопасности при использовании Sparkplug связан с тем, как интерпретируется расположение кадров стека Ignitions, что может привести к путанице типов или выполнению кода на стеке. Примером может служить выпуск 1179595, который был потенциальным RCE из-за некорректной проверки количества регистров. Есть также проблема в том, как Sparkplug выполняет переключение битов RX/WX - но я не буду вдаваться в подробности, поскольку это действительно не важно, и такие ошибки не играют важной роли в этой общей серии. Итак, мы поняли, как работает Ignition и Sparkplug. Теперь пришло время погрузиться глубже в конвейер компилятора и понять оптимизирующий компилятор TurboFan.
TurboFan
TurboFan - это компилятор V8 Just-In-Time (JIT), который сочетает в себе интересную концепцию непосредственного представления, известную как "море узлов", с многоуровневым конвейером трансляции и оптимизации, который помогает TurboFan генерировать машинный код лучшего качества из байткода. Те, кто был внимателен, читая код и документацию по ходу работы, знают, что TurboFan - это гораздо больше, чем просто компилятор. TurboFan фактически отвечает за обработчики байткода интерпретатора, встроенные модули, вставки кода и систему встроенного кэша с помощью своего макроассемблера! Поэтому, когда я говорю, что TurboFan - самая важная часть конвейера компилятора, я не шучу.
Итак, как же работают эти оптимизирующие компиляторы, такие как TurboFan?
Оптимизирующие компиляторы работают с помощью так называемого "профилировщика", о котором мы вкратце упоминали в первой части. По сути, этот профилировщик работает заранее, отслеживая код, который следует оптимизировать (мы называем этот код или функцию JavaScript "горячей"). Он делает это, собирая метаданные и "образцы" из функций JavaScript и стека, просматривая информацию, собранную встроенными кэшами и вектором обратной связи. Затем компилятор строит структуру данных промежуточного представления (IR), которая используется для создания оптимизированного кода. Весь этот процесс просмотра кода и последующей компиляции машинного кода называется Just-in-Time или JIT-компиляцией.
Компиляция точно в срок (JIT)
Как мы знаем, выполнение байткода в интерпретаторе VM происходит медленнее, чем выполнение ассемблера на родной машине. Причина этого в том, что JavaScript динамичен и существует много накладных расходов на поиск свойств, проверку объектов, значений и т.д., а также мы работаем на эмулированном стеке.
Конечно, Maps и Incline Caching (IC) помогают решить некоторые из этих накладных расходов, ускоряя динамический поиск свойств, объектов и значений - но они все равно не могут обеспечить пиковую производительность. Причина этого в том, что каждый IC действует сам по себе и не имеет никаких знаний или представлений о своих соседях. Возьмем, к примеру, Maps: если мы добавляем свойство к известной форме, нам все равно приходится следовать таблице переходов и искать или добавлять дополнительные формы. Если нам приходится делать это много раз для конкретной функции или объекта, даже при известной форме, мы тратим много вычислительных циклов, делая это снова и снова. Поэтому, когда есть функция JavaScript, которая выполняется много раз, возможно, стоит потратить время на то, чтобы передать функцию в компилятор и скомпилировать ее в машинный код, что позволит выполнять ее гораздо быстрее.
Для примера возьмем такой код:
Код:
function hot_function(obj) {
return obj.x;
}
for (let i=0; i < 10000; i++) {
hot_function({x:i});
}Функция hot_function просто принимает объект и возвращает значение свойства x. Далее мы выполняем эту функцию примерно 10k раз и для каждого объекта мы просто передаем новое целое число для свойства x. В этом случае, поскольку функция используется много раз, а общая форма объекта не меняется, V8 может решить, что лучше просто передать ее вверх по конвейеру (известному как "tier-up") для компиляции, чтобы она выполнялась быстрее.
Мы можем увидеть это в действиях в d8, отследив оптимизацию с помощью флага --trace-opt. Итак, давайте сделаем именно это, а также добавим команду --allow-natives-syntax, чтобы мы могли изучить, как выглядит код функции до и после оптимизации.
Начнем с запуска d8 и установки нашей функции. После этого воспользуйтесь командой %DisassembleFunction против hot_function, чтобы узнать ее тип. Вы должны получить что-то похожее.
Код:
d8> function hot_function(obj) {return obj.x;}
d8> %DisassembleFunction(hot_function)
0000027B0020B31D: [CodeDataContainer] в OldSpace
- map: 0x027b00002a71 <Map[32](CODE_DATA_CONTAINER_TYPE)>
- kind BUILTIN
- builtin: InterpreterEntryTrampoline
- is_off_heap_trampoline: 1
- code 0
- code_entry_point: 00007FFCFF5875C0
- kind_specific_flags: 0Как вы можете видеть, изначально этот объект кода будет выполнен Ignition, поскольку это BUILTIN, и будет обработан InterpreterEntryTrampoline, как мы знаем. Теперь, если мы выполним эту функцию 10k раз, мы увидим, что она будет оптимизирована TurboFan.
Код:
d8> for (let i=0; i < 10000; i++) {hot_function({x:i});}
[marking 0x027b0025aa4d <JSFunction (sfi = 0000027B0025A979)> for optimization to TURBOFAN, ConcurrencyMode::kConcurrent, reason: small function]
[compiling method 0x027b0025aa4d <JSFunction (sfi = 0000027B0025A979)> (target TURBOFAN) OSR, mode: ConcurrencyMode::kConcurrent]
[completed compiling 0x027b0025aa4d <JSFunction (sfi = 0000027B0025A979)> (target TURBOFAN) OSR - took 1.691, 81.595, 2.983 ms]
[completed optimizing 0x027b0025aa4d <JSFunction (sfi = 0000027B0025A979)> (target TURBOFAN) OSR]
9999Как вы видите, TurboFan включается и начинает компилировать функцию для оптимизации. Обратите внимание на несколько ключевых моментов в трассировке оптимизации. Как вы можете видеть в первой строке трассировки оптимизации, мы помечаем SFI или SharedFunctionInfo функции JSFunction для оптимизации. Если вы вспомните наше глубокое погружение в Ignition, вы вспомните, что SFI содержит байткод для нашей функции. TurboFan будет использовать этот байткод для генерации IR, а затем оптимизирует его до машинного кода. Теперь, если вы посмотрите дальше, вы увидите упоминание OSR или замены на стеке. В основном TurboFan делает то же самое, что и Sparkplug, когда оптимизирует байткод. Он заменит стековый кадр на настоящий JIT или системный стековый кадр, который будет указывать на оптимизированный код во время выполнения. Это позволяет функции перейти непосредственно к оптимизированному коду при следующем вызове, а не выполняться в эмулированном стеке Ignitions. Если мы снова выполним %DisassembleFunction против нашей горячей_функции, мы увидим, что она теперь оптимизирована, и точка входа в код в SharedFunctionInfo будет указывать на оптимизированный машинный код.
Код:
d8> %DisassembleFunction(hot_function)
0000027B0025B2B5: [CodeDataContainer] в OldSpace
- map: 0x027b00002a71 <Map[32](CODE_DATA_CONTAINER_TYPE)>
- type: TURBOFAN
- is_off_heap_trampoline: 0
- code: 0x7ffce0004241 <Код TURBOFAN>
- code_entry_point: 00007FFCE0004280
- kind_specific_flags: 4Те, у кого зоркий глаз, могли заметить кое-что интересное, когда мы проследили оптимизацию нашей функции. Если вы были внимательны, то заметили, что TurboFan включился не сразу, а через несколько секунд - или после нескольких тысяч итераций цикла. Почему так? Это происходит потому, что TurboFan ждет, пока код "разогреется". Если вы помните нашу дискуссию о Ignition и Sparkplug, мы вкратце упомянули вектор обратной связи. Этот вектор хранит данные времени выполнения объекта вместе с информацией из встроенных кэшей и собирает так называемую обратную связь по типу. Это очень важно для TurboFan, поскольку, как мы знаем, JavaScript динамичен, и у нас нет возможности хранить статическую информацию о типе. Во-вторых, мы не знаем тип значения до времени выполнения. JIT-компилятор фактически вынужден делать обоснованные предположения об использовании и поведении кода, который он компилирует, такие как тип вашей функции, тип передаваемых переменных и т.д. По сути, компилятор делает много предположений об использовании и поведении кода, который он компилирует. По сути, компилятор делает много предположений или "догадок". Именно поэтому оптимизирующие компиляторы смотрят на информацию, собранную кэшами наклона, и используют вектор обратной связи для принятия обоснованных решений о том, что нужно сделать с кодом, чтобы он стал быстрым. Это известно как спекулятивная оптимизация.
Спекулятивная оптимизация и защита типов
Как же спекулятивная оптимизация помогает нам превратить наш код JavaScript в высоко оптимизированный машинный код? Чтобы объяснить это, давайте начнем с примера.
Допустим, у нас есть простая оценка для функции add, например return 1 + i. Здесь мы возвращаем значение, прибавляя 1 к i. Не зная, какой тип i, мы должны следовать стандартной реализации ECMAScript для семантики EvaluateStringOrNumericBinaryExpression.
Как видите, как только мы оцениваем левую и правую ссылки и вызываем GetValue как для левого, так и для правого значений нашего операнда, нам нужно следовать стандарту ECMAScript для ApplyStringOrNumericBinaryOperator, чтобы мы могли вернуть наше значение.
Если вы еще не поняли, что без знания типа переменной i, будь то целое число или строка, мы никак не сможем реализовать всю эту оценку всего за несколько машинных инструкций и при этом сделать ее быстрой. Именно здесь вступает в дело спекулятивная оптимизация, при которой TurboFan будет полагаться на вектор обратной связи, чтобы сделать свои предположения о возможных типах i. Например, если после нескольких сотен запусков мы посмотрим на вектор обратной связи для байткода Add и узнаем, что i - это число, то нам не придется обрабатывать оценки ToString или даже ToPrimitive. В этом случае оптимизатор может взять инструкцию IR и утверждать, что i и возвращаемое значение - это просто числа, и загрузить их как таковые. Это минимизирует количество машинных инструкций, которые нам нужно сгенерировать.
Как же выглядят эти векторы обратной связи в случае нашей функции?
Если вы вспомните упоминание объекта JSFunction или закрытия, вы вспомните, что закрытие связало нас со слотом вектора обратной связи, а также с SharedFunctionInfo. В векторе обратной связи есть интересный слот под названием BinaryOp, который записывает информацию о входах и выходах бинарных операций, таких как +, -, * и т.д.
Мы можем проверить, что находится внутри нашего вектора обратной связи и увидеть этот конкретный слот, выполнив %DebugPrint против нашей функции add.
Код:
d8> function add(i) {return 1 + i;}
d8> for (let i=0; i<100; i++) {add(i);}
d8> %DebugPrint(add)
DebugPrint: 0000019A002596F1: [Function] in OldSpace
- map: 0x019a00243fa1 <Map[32](HOLEY_ELEMENTS)> [FastProperties]
- prototype: 0x019a00243ec9 <JSFunction (sfi = 0000019A0020AA45)>
- elements: 0x019a00002259 <FixedArray[0]> [HOLEY_ELEMENTS]
- function prototype:
- initial_map:
- shared_info: 0x019a0025962d <SharedFunctionInfo add>
- name: 0x019a00005809 <String[3]: #add>
- builtin: InterpreterEntryTrampoline
- formal_parameter_count: 1
- kind: NormalFunction
- context: 0x019a00243881 <NativeContext[273]>
- code: 0x019a0020b31d <CodeDataContainer BUILTIN InterpreterEntryTrampoline>
- interpreted
- bytecode: 0x019a0025a89d <BytecodeArray[9]>
- source code: (i) {return 1 + i;}
- properties: 0x019a00002259 <FixedArray[0]>
...
- feedback vector: 0000019A0025B759: [FeedbackVector] in OldSpace
- map: 0x019a0000273d <Map(FEEDBACK_VECTOR_TYPE)>
- length: 1
- shared function info: 0x019a0025962d <SharedFunctionInfo add>
- no optimized code
- tiering state: TieringState::kNone
- maybe has maglev code: 0
- maybe has turbofan code: 0
- invocation count: 97
- profiler ticks: 0
- closure feedback cell array: 0000019A00003511: [ClosureFeedbackCellArray] in ReadOnlySpace
- map: 0x019a00002981 <Map(CLOSURE_FEEDBACK_CELL_ARRAY_TYPE)>
- length: 0
- slot #0 BinaryOp BinaryOp:SignedSmall {
[0]: 1
}
...Здесь есть несколько интересных элементов. Invocation count показывает нам количество запусков функции add, а если мы посмотрим на наш вектор обратной связи, то увидим, что у нас есть только один слот, который является BinaryOp, о котором мы говорили. Заглянув в этот слот, мы увидим, что он содержит текущий тип обратной связи SignedSmall, который, по сути, относится к SMI. Помните, что эта информация обратной связи интерпретируется не V8, а TurboFan, а, как мы знаем, SMI - это знаковое 32-битное значение, как мы объясняли в части, посвященной тегам указателей в первой части этой серии. В целом, эти спекуляции с помощью векторов обратной связи отлично помогают ускорить наш код, удаляя ненужные машинные инструкции для различных типов. К сожалению, довольно небезопасно применять инструкции, ориентированные исключительно на один тип, к динамическим объектам. Итак, что произойдет, если на полпути в оптимизированной функции мы передадим строку вместо числа? По сути, если это произойдет, то мы получим уязвимость путаницы типов. Для защиты от потенциально неверных предположений TurboFan добавляет перед выполнением определенных инструкций так называемую защиту типа. Эта защита типа проверяет, что форма объекта, который мы передаем, имеет правильный тип. Это делается до того, как объект попадает в наши оптимизированные операции. Если объект не соответствует ожидаемой форме, то выполнение оптимизированного кода не может быть продолжено. В этом случае мы "выйдем" из ассемблерного кода и вернемся к неоптимизированному байткоду в интерпретаторе и продолжим выполнение там. Это известно как "деоптимизация". Пример защиты типа и перехода к деоптимизации в оптимизированном ассемблерном коде можно увидеть ниже.
Код:
REX.W movq rcx,[rbp-0x38] ; Move i to rcx
testb rcx,0x1 ; Check if rcx is an SMI
jnz 00007FFB0000422A <+0x1ea> ; If check fails, bailoutТеперь деоптимизация за счет защит типов не ограничивается проверкой несовпадения типов объектов. Они также работают с арифметическими операциями и проверкой границ.
Например, если наш оптимизированный код был оптимизирован для арифметических операций над 32-разрядными целыми числами, и произошло переполнение, мы можем деоптимизировать и позволить Ignition обработать вычисления - тем самым защитив себя от потенциальных проблем безопасности на машине. Такие проблемы, которые могут привести к деоптимизации, известны как "побочные эффекты" (которые мы рассмотрим более подробно позже). Как и в случае с процессом оптимизации, мы также можем увидеть деоптимизацию в действии в d8, используя флаг --trace-deopt. После этого давайте снова добавим нашу функцию add и запустим следующий цикл.
Код:
for (let i=0; i<10000; i++) {
if (i<7000) {
add(i);
} else {
add("string");
}
}Это просто позволит оптимизировать функцию для чисел, а затем, после 7000 итераций, мы начнем передавать строку, которая должна вызвать спасение. Ваш вывод должен быть похож на:
Код:
d8> function add(i) {return 1 + i;}
d8> for (let i=0; i<10000; i++) {if (i<7000) {add(i);} else {add("string");}}
[marking 0x03e20025ac55 <JSFunction (sfi = 000003E20025AB5D)> for optimization to TURBOFAN, ConcurrencyMode::kConcurrent, reason: small function]
[compiling method 0x03e20025ac55 <JSFunction (sfi = 000003E20025AB5D)> (target TURBOFAN) OSR, mode: ConcurrencyMode::kConcurrent]
[completed compiling 0x03e20025ac55 <JSFunction (sfi = 000003E20025AB5D)> (target TURBOFAN) OSR - took 1.987, 70.704, 2.731 ms]
[completed optimizing 0x03e20025ac55 <JSFunction (sfi = 000003E20025AB5D)> (target TURBOFAN) OSR]
[bailout (kind: deopt-eager, reason: Insufficient type feedback for call): begin. deoptimizing 0x03e20025ac55 <JSFunction (sfi = 000003E20025AB5D)>, 0x7ffb00004001 <Code TURBOFAN>, opt id 0, node id 63, bytecode offset 40, deopt exit 3, FP to SP delta 96, caller SP 0x00ea459fe250, pc 0x7ffb00004274]
[compiling method 0x03e20025ac55 <JSFunction (sfi = 000003E20025AB5D)> (target TURBOFAN) OSR, mode: ConcurrencyMode::kConcurrent]
[completed compiling 0x03e20025ac55 <JSFunction (sfi = 000003E20025AB5D)> (target TURBOFAN) OSR - took 0.325, 121.591, 1.425 ms]
[completed optimizing 0x03e20025ac55 <JSFunction (sfi = 000003E20025AB5D)> (target TURBOFAN) OSR]
"1string"Как вы можете видеть, функции оптимизируются, а затем мы вызываем отказ. Это деоптимизирует код обратно в байткод из-за недостаточного типа во время нашего вызова. Затем происходит нечто интересное. Функция снова оптимизируется. Почему? Ну, функция все еще "горячая", и впереди еще несколько тысяч итераций. Теперь, когда TurboFan собрал и число, и строку в обратной связи, он вернется и оптимизирует код во второй раз. Но на этот раз он добавит код, который позволит оценивать строки. В этом случае будет добавлен второй защитник типов - таким образом, второй цикл кода теперь оптимизирован и для числа, и для строки! Хороший пример и объяснение этого можно увидеть в видео "Inside V8: The choreography of Ignition and TurboFan".
Мы также можем увидеть эту обновленную обратную связь в слоте BinaryOp, выполнив команду %DebugPrint для нашей функции add. Вы должны увидеть нечто подобное, как показано ниже.
Код:
d8> %DebugPrint(add)
DebugPrint: 000003E20025970D: [Function] in OldSpace
- map: 0x03e200243fa1 <Map[32](HOLEY_ELEMENTS)> [FastProperties]
- prototype: 0x03e200243ec9 <JSFunction (sfi = 000003E20020AA45)>
- elements: 0x03e200002259 <FixedArray[0]> [HOLEY_ELEMENTS]
- function prototype:
- initial_map:
- shared_info: 0x03e20025962d <SharedFunctionInfo add>
- name: 0x03e200005809 <String[3]: #add>
- builtin: InterpreterEntryTrampoline
- formal_parameter_count: 1
- kind: NormalFunction
- context: 0x03e200243881 <NativeContext[273]>
- code: 0x03e20020b31d <CodeDataContainer BUILTIN InterpreterEntryTrampoline>
- interpreted
- bytecode: 0x03e20025aca5 <BytecodeArray[9]>
- source code: (i) {return 1 + i;}
- properties: 0x03e200002259 <FixedArray[0]>
...
- feedback vector: 000003E20025ACF1: [FeedbackVector] in OldSpace
- map: 0x03e20000273d <Map(FEEDBACK_VECTOR_TYPE)>
- length: 1
- shared function info: 0x03e20025962d <SharedFunctionInfo add>
- no optimized code
- tiering state: TieringState::kNone
- maybe has maglev code: 0
- maybe has turbofan code: 0
- invocation count: 5623
- profiler ticks: 0
- closure feedback cell array: 000003E200003511: [ClosureFeedbackCellArray] in ReadOnlySpace
- map: 0x03e200002981 <Map(CLOSURE_FEEDBACK_CELL_ARRAY_TYPE)>
- length: 0
- slot #0 BinaryOp BinaryOp:Any {
[0]: 127
}Как вы можете видеть, BinaryOp теперь хранит тип обратной связи Any, вместо SignedSmall и String. Почему? Это связано с тем, что называется решеткой обратной связи.
Решетка обратной связи
Решетка обратной связи хранит возможные состояния обратной связи для операции. Она начинается с None, что означает, что функция ничего не видела, и спускается вниз к состоянию Any, что означает, что она видела комбинацию входов и выходов. Состояние Any указывает на то, что функцию следует считать полиморфной, в то время как любое другое состояние, напротив, указывает на то, что функция является мономорфной - поскольку она производит только определенное значение. Если вы хотите узнать больше о разнице между мономорфным и полиморфным кодом, я настоятельно рекомендую вам прочитать фантастическую статью "Что такое мономорфизм?".
Ниже я привел наглядный пример того, как примерно выглядит решетка обратной связи.
Как и решетка массивов из первой части, эта решетка работает точно так же. Отзывы могут двигаться только вниз по решетке. Как только мы перейдем от числа к любому, мы никогда не сможем вернуться назад. Если по какой-то волшебной причине мы все же вернемся назад, то рискуем попасть в так называемый цикл деоптимизации, когда оптимизирующий компилятор потребляет недопустимую обратную связь и постоянно выходит из оптимизированного кода. Более подробную информацию о проверке типов можно найти в файле v8/src/compiler/use-info.h. Также, если вы хотите узнать больше о системе обратной связи и встроенном кэше V8, советую посмотреть фильм "V8 и как он вас слушает - Майкл Стэнтон".
Промежуточное представление (IR) "Море узлов"
Теперь, когда мы знаем, как собирается обратная связь по типам для TurboFan, чтобы сделать свои спекулятивные предположения, давайте посмотрим, как TurboFan строит свой специализированный IR на основе этой обратной связи. Причина, по которой создается IR, заключается в том, что эта структура данных абстрагируется от сложности кода, что, в свою очередь, облегчает оптимизацию компилятора. Так, IR TurboFans "Sea of Nodes" основан на статическом однократном присваивании или SSA, которое является свойством IR, требующим, чтобы каждая переменная была присвоена ровно один раз и определена до ее использования. Это полезно для таких оптимизаций, как устранение избыточности.
Пример SSA для нашей функции add из предыдущего примера можно увидеть ниже.
Код:
// function add(i) {return 1 + i;}
var i1 = argument
var r1 = 1 + i1
return r1Эта форма SSA затем преобразуется в формат графа, который похож на граф потока управления (CFG), где используются узлы и ребра для представления кода и его зависимостей между вычислениями. Такой вид графа позволяет TurboFan использовать его как для анализа потока данных, так и для генерации машинного кода. Итак, давайте посмотрим, как выглядит это море узлов. Для этого мы будем использовать наш пример hot_function. Начнем с создания нового файла JavaScript и добавим в него следующее.
Код:
function hot_function(obj) {
return obj.x;
}
for (let i=0; i < 10000; i++) {
hot_function({x:i});
}После этого запустим этот скрипт через d8 с флагом --trace-turbo, который позволяет нам отследить и сохранить IR, сгенерированный TurboFans JIT. Ваш результат должен быть похож на мины. В конце выполнения скрипт должен сгенерировать JSON-файл, имеющий соглашение об именовании turbo-*.json.
Код:
C:\dev\v8\v8\out\x64.debug>d8 --trace-turbo hot_function.js
Concurrent recompilation has been disabled for tracing.
---------------------------------------------------
Begin compiling method add using TurboFan
---------------------------------------------------
Finished compiling method add using TurboFanПосле этого перейдите к Turbolizer в веб-браузере, нажмите CTRL + L и загрузите ваш JSON-файл. Этот инструмент поможет нам визуализировать граф "море узлов", сгенерированный TurboFan.
График, который вы увидите, должен быть практически идентичен:
B Turbolizer, слева вы увидите свой исходный код, а справа (не показано на изображении) - оптимизированный машинный код, сгенерированный TurboFan. В центре находится граф "море узлов".
В настоящее время многие узлы скрыты и показаны только управляющие узлы, что является поведением по умолчанию. Если вы нажмете на поле "Показать все узлы" справа от символа "обновить", вы увидите все узлы. Повозившись в Turbolizer и просмотрев график, вы заметите, что есть пять различных цветов узлов, и они представляют следующее:
Желтый: Эти узлы представляют управляющие узлы, то есть все, что может изменить "поток" сценария - например, оператор if/else.
Светло-синий: Эти узлы представляют значение, которое может иметь или возвращать определенный узел, например, константы кучи или встроенные значения.
Красный: Представляет семантику перегруженных операторов JavaScript, таких как любые действия, выполняемые на уровне JavaScript, т.е. JSCall, JSAdd и т.д. Они напоминают операции байткода.
Синий: Выражают операции на уровне виртуальной машины, такие как выделение, проверка границ, загрузка данных из стека и т.д. Это полезно для отслеживания обратной связи, потребляемой Turbofan.
Зеленый: Они соответствуют отдельным инструкциям машинного уровня.
Как мы видим, каждый узел в этом море узлов может представлять арифметические операции, загрузки, сохранения, вызовы, константы и т.д. Затем есть три ребра (представленные стрелками между каждым узлом), о которых мы должны знать, которые выражают зависимости. Эти ребра следующие:
Control: Как и в CFG, эти ребра позволяют выполнять ветвления и циклы.
Value: Как и в графиках потоков данных, эти ребра показывают зависимость значений и выход.
Effect: Операции детального порядка, такие как чтение или запись состояний.
С этими знаниями давайте немного расширим граф и посмотрим на некоторые другие узлы, чтобы понять, как работает поток. Обратите внимание, что я скрыл несколько отдельных узлов, которые на самом деле не важны.
Как мы видим, узлы желтого цвета - это узлы управления, которые управляют потоком функции. Вначале у нас есть узел Loop, который сообщает нам, что мы идем в цикл. От него управляющие ребра указывают на узлы Branch и LoopExit. Branch - это именно то, что он означает, он "разветвляет" цикл на утверждение True/False. Если мы проследим за узлом Branch вверх, то увидим, что в нем есть узел SpeculativeNumberLessThan, который имеет ребро значения, указывающее на NumberConstant со значением 10000. Это соответствует нашей функции, поскольку мы выполняли цикл 10k раз. Поскольку этот узел имеет зеленый цвет, он является машинной инструкцией и обозначает нашу защиту типа для цикла. Из узла SpeculativeNumberLessThan видно, что есть ребро эффекта, указывающее на LoopExitEffect, что означает, что если число больше 10k, мы выходим из цикла, так как только что нарушили предположение. Пока значение меньше 10k и SpeculativeNumberLessThan истинно, мы загрузим наш объект и вызовем JSDefineNamedOwnProperty, который получит смещение объекта к свойству x. Затем мы вызовем JSCall, чтобы добавить 1 к значению нашего свойства и вернуть значение. Из этого узла у нас также есть ребро эффекта, идущее к SpeculativeSafeIntegerAdd. Этот узел имеет ребро значения, указывающее на узел NumberConstant, который имеет значение 1, что и является математическим сложением, которое мы выполняем при возврате значения. Еще раз обратите внимание, что у нас есть узел SpeculativeSafeIntegerAdd, который проверяет, что арифметика сложения, которую мы выполняем, действительно добавляет SMI, а не что-то другое, иначе сработает защита типов и произойдет деоптимизация. Для тех, кому интересно, что такое узел Phi, это узел SSA, который объединяет две (или более) возможности для значения, которые были вычислены разными ветвями. В данном случае он объединяет обе потенциальные целочисленные спекуляции вместе.
Как видите, понимание этих графов не слишком сложное, как только вы поймете основы.
Теперь, если вы посмотрите на левую верхнюю часть окна "Море узлов", вы увидите, что мы находимся в опции V8.TFBytecodeGraphBuilder. Эта опция показывает нам сгенерированный IR из байткода без каких-либо примененных к нему оптимизаций. Из выпадающего меню мы можем выбрать другие различные проходы оптимизации, через которые проходит этот код, чтобы просмотреть связанный IR.
Общие оптимизации
Итак, теперь, когда мы рассмотрели TurboFans Sea of Nodes, у нас должно быть хотя бы приблизительное понимание того, как ориентироваться и понимать сгенерированный IR. Отсюда мы можем перейти к пониманию некоторых общих оптимизаций TurboFans. Эти оптимизации, по сути, действуют на исходный граф, который был получен из байткода. Поскольку результирующий граф теперь имеет статическую информацию о типах благодаря защитникам типов, оптимизация выполняется более классическим способом, опережающим время, чтобы улучшить скорость выполнения или объем памяти кода. Затем, когда граф оптимизирован, полученный граф опускается в машинный код (известный как "опускание") и записывается в исполняемую область памяти для выполнения V8 при вызове скомпилированной функции. Следует отметить, что опускание может происходить в несколько этапов с последующими оптимизациями между ними, что делает этот конвейер компилятора довольно гибким.
С учетом сказанного, давайте рассмотрим некоторые из этих распространенных оптимизаций.
Typer
Одна из самых ранних фаз оптимизации называется TyperPhase, которая выполняется функцией OptimizeGraph. Эта фаза прослеживает код и определяет результирующие типы операций с объектами кучи, например, Int32 + Int32 = Int32. При запуске Typer посетит каждый узел графа и попытается "сократить" их, пытаясь упростить логику операций. Затем он вызовет связанный с узлом вызов Typer, чтобы связать с ним тип. Например, в нашем случае константные целые числа в цикле и возвратная арифметика будут посещены Typer::Visitor:
ypeNumberConstant, который вернет тип Range - как видно из примера кода из v8/src/compiler/types.cc.
Код:
Type::Constant(double value, Zone* zone) {
if (RangeType::IsInteger(value)) {
return Range(value, value, zone);
} else if (IsMinusZero(value)) {
return Type::MinusZero();
} else if (std::isnan(value)) {
return Type::NaN();
}Теперь что насчет наших спекулятивных узлов?
Они обрабатываются OperationTyper. В нашем случае арифметическая спекуляция для возврата значения будет вызывать OperationTyper::SpeculativeSafeIntegerAdd, который установит тип в диапазон "безопасных целых чисел", например, Int64. Этот тип будет проверяться, и если во время выполнения он не является Int64, мы деоптимизируем. По сути, это позволяет арифметическим операциям иметь положительное и отрицательное возвращаемое значение и предотвращает потенциальные проблемы переполнения/недополнения.
Зная это, давайте посмотрим на этап оптимизации V8.TFTyper, чтобы увидеть граф и узлы, связанные с типами.
Анализ диапазона
Во время оптимизации Typer компилятор прослеживает код, определяет диапазон операций и вычисляет границы результирующих значений. Это известно как анализ диапазона.
Если вы заметили на графике выше, мы встретили тип Range, особенно для узла SpeculativeSafeIntegerAdd, который имел диапазон переменной Int64. Это было сделано потому, что оптимизатор анализа диапазона вычисляет минимальное и максимальное значения, которые добавляются или возвращаются. В нашем случае мы возвращали значение i из свойства нашего объекта x плюс 1. Обратная связь типа действительно знала только то, что возвращаемое значение является целым числом и все, она никогда не могла сказать, в каком диапазоне будет это значение. Поэтому, чтобы подстраховаться, она решила дать ему самое большое значение, какое только возможно, чтобы избежать проблем.
Итак, давайте еще раз посмотрим на анализ диапазона, рассмотрев следующий код:
Код:
function hot_function(obj) {
let values = [0,13,1337]
let a = 1;
if (obj == "leet")
a = 2;
return values[a];
}Как мы видим, в зависимости от того, какой тип параметра obj передан, если obj - это строка, равная слову leet, то a будет равно 1337, в противном случае оно будет равно 13. Эта часть кода пройдет через SSA и будет объединена в узел Phi, который будет содержать диапазон того, каким может быть a. Диапазон констант будет установлен на их жестко закодированное значение, но эти константы также будут влиять на наши умозрительные диапазоны из-за арифметических вычислений.
Если мы посмотрим на график, полученный из этого кода после анализа диапазона, то увидим следующее.
Как видите, благодаря SSA у нас есть узел Phi. Во время анализа диапазона типер обращается к функции узла TypePhi и создает объединение операндов 13 и 1337, что позволяет нам получить возможный диапазон для a. Для спекулятивных узлов OperationTyper вызывает функцию AddRanger, которая вычисляет минимальную и максимальную границы для типа Range. В данном случае видно, что тип вычисляет диапазон возвращаемых значений для обеих возможных итераций a после арифметических операций. Благодаря этому, в случае, если анализ диапазона не удался и мы получаем значение, не ожидаемое компилятором, мы деоптимизируем. Довольно просто для понимания!
Устранение проверки границ (BCE)
Еще одной распространенной оптимизацией, которая применялась с тайпером на этапе упрощенного опускания, была операция CheckBounds, которая применяется к спекулятивным узлам CheckBound. Эта оптимизация обычно применяется к операциям доступа к массиву, если было доказано, что индекс массива находится в пределах границ массива после анализа диапазона. Причина, по которой я говорю "была", заключается в том, что команда разработчиков Chromium решила отключить эту оптимизацию, чтобы усилить проверку границ TurboFan против ошибок, связанных с тайперами. Есть несколько "багов", которые позволят вам обойти эту защиту, но я не буду об этом рассказывать. Если вы хотите узнать больше об этих ошибках, то советую прочитать статью "Обход усиления защиты Chrome от ошибок тайперов".
В любом случае, давайте продемонстрируем, как этот тип оптимизации мог бы сработать, взяв для примера следующий код:
Код:
function hot_function(obj) {
let values = [0,13,1337]
let a = 1;
if (obj == "leet")
a = 2;
return values[a];
}Как вы можете видеть, это очень похоже на код, который мы использовали в нашем анализе диапазона. Мы снова принимаем параметр в нашу функцию hot_function, и если объект соответствует строке "leet", мы устанавливаем a в 2 и возвращаем значение 1337, в противном случае мы устанавливаем a в 1 и возвращаем значение 13. Обратите особое внимание на то, что a никогда не равно 0, поэтому мы никогда не сможем или, по крайней мере, не должны иметь возможность вернуть 0. Это создает для нас интересный случай, когда мы смотрим на график. Итак, давайте обратимся к части IR, посвященной анализу побега, и посмотрим, как выглядит наш график.
Как вы видите, у нас есть еще один узел Phi, который объединяет наши потенциальные значения a, а затем у нас есть узел CheckBounds, который используется для проверки границ массива. Если мы находимся в диапазоне 1 или 2, мы вызываем LoadElement, чтобы загрузить наш элемент из массива, в противном случае мы выйдем из системы, так как проверка границ не ожидает индекса 0.
Для тех, кто уже заметил это, может возникнуть вопрос, почему наш LoadElement имеет тип Signed31, а не Signed32. Просто, Signed31 представляет тот факт, что первый бит используется для обозначения знака. Это означает, что в случае 32-битного знакового целого числа мы фактически работаем с 31 битом значения вместо 32. Также, как мы видим, LoadElement имеет на входе FixedArray HeapConstant с длиной 3. Этот массив будет нашим массивом значений. После того как анализ побега проведен, мы переходим к упрощенной фазе опускания. Эта фаза понижения просто (каламбурно) изменяет все представления значений на правильное машинное представление, как диктуют сами операторы машины. Код для этой фазы находится в файле v8/src/compiler/simplified-lowering.cc. Именно в этой фазе происходит устранение проверки границ.
Как же компилятор решает сделать узел CheckBounds избыточным?
Ну, для каждого узла CheckBounds будет вызвана функция VisitCheckBounds. Эта функция отвечает за проверку и удостоверение в том, что минимальный диапазон индекса равен или больше нуля и что максимальный диапазон не превышает длины массива. Если проверка истинна, то вызывается DeferReplacement, которая помечает узел для удаления.
Пример функции VisitCheckBounds до фиксации ужесточения 7bb6dc0e06fa158df508bc8997f0fce4e33512a5 можно увидеть ниже.
Код:
void VisitCheckBounds(Node* node, SimplifiedLowering* lowering) {
CheckParameters const& p = CheckParametersOf(node->op());
Type const index_type = TypeOf(node->InputAt(0));
Type const length_type = TypeOf(node->InputAt(1));
if (length_type.Is(Type::Unsigned31())) {
if (index_type.Is(Type::Integral32OrMinusZero())) {
// Map -0 to 0, and the values in the [-2^31,-1] range to the
// [2^31,2^32-1] range, which will be considered out-of-bounds
// as well, because the {length_type} is limited to Unsigned31.
VisitBinop(node, UseInfo::TruncatingWord32(),
MachineRepresentation::kWord32);
if (lower()) {
if (lowering->poisoning_level_ ==
PoisoningMitigationLevel::kDontPoison &&
(index_type.IsNone() || length_type.IsNone() ||
(index_type.Min() >= 0.0 &&
index_type.Max() < length_type.Min()))) {
// The bounds check is redundant if we already know that
// the index is within the bounds of [0.0, length[.
DeferReplacement(node, node->InputAt(0)); // <= Removes Nodes
} else {
NodeProperties::ChangeOp(
node, simplified()->CheckedUint32Bounds(p.feedback()));
}
}
...
}Как вы видите, наш диапазон CheckBound попадает в оператор if, где Range(1,2).Min() >= 0 и Range(1,2).Max() < 3. В этом случае наш узел №46 из приведенного выше графика станет ненужным и будет удален. Теперь, если вы посмотрите на обновленный код после фиксации, вы увидите небольшое изменение. Вызов DeferReplacement был удален, и вместо этого мы заменяем узел узлом CheckedUint32Bounds. Если проверка не удалась, TurboFan вызывает kAbortOnOutOfBounds, который прерывает проверку границ и завершает работу вместо деоптимизации.
Новый код можно увидеть ниже:
Код:
void VisitCheckBounds(Node* node, SimplifiedLowering* lowering) {
CheckBoundsParameters const& p = CheckBoundsParametersOf(node->op());
FeedbackSource const& feedback = p.check_parameters().feedback();
Type const index_type = TypeOf(node->InputAt(0));
Type const length_type = TypeOf(node->InputAt(1));
// Conversions, if requested and needed, will be handled by the
// representation changer, not by the lower-level Checked*Bounds operators.
CheckBoundsFlags new_flags =
p.flags().without(CheckBoundsFlag::kConvertStringAndMinusZero);
if (length_type.Is(Type::Unsigned31())) {
if (index_type.Is(Type::Integral32()) ||
(index_type.Is(Type::Integral32OrMinusZero()) &&
p.flags() & CheckBoundsFlag::kConvertStringAndMinusZero)) {
// Map the values in the [-2^31,-1] range to the [2^31,2^32-1] range,
// which will be considered out-of-bounds because the {length_type} is
// limited to Unsigned31. This also converts -0 to 0.
VisitBinop<T>(node, UseInfo::TruncatingWord32(),
MachineRepresentation::kWord32);
if (lower<T>()) {
if (index_type.IsNone() || length_type.IsNone() ||
(index_type.Min() >= 0.0 &&
index_type.Max() < length_type.Min())) {
// The bounds check is redundant if we already know that
// the index is within the bounds of [0.0, length[.
// TODO(neis): Move this into TypedOptimization?
new_flags |= CheckBoundsFlag::kAbortOnOutOfBounds; // <= Abort & Crash
}
ChangeOp(node,
simplified()->CheckedUint32Bounds(feedback, new_flags)); // <= Replace Node
}
...
}Если мы посмотрим на упрощенную нижнюю часть графика, мы действительно увидим, что узел CheckBounds теперь был заменен узлом CheckedUint32Bounds в соответствии с кодом, а значения всех остальных узлов были «понижены» до представления машинного кода.
Устранение избыточности
Другой популярный класс оптимизаций, похожий на BCE, называется устранением избыточности. Код для него находится в файле v8/src/compiler/redundancy-elimination.cc и отвечает за удаление избыточных проверок типов. Класс RedundancyElimination - это, по сути, редуктор графа, который пытается либо удалить, либо объединить избыточные проверки в цепочке эффектов. Цепочка эффектов - это в основном порядок операций между ребрами эффектов для функций load и store. Например, если мы пытаемся загрузить свойство из объекта и попытаться добавить к нему, например, obj[x] = obj[x] + 1, то наша цепочка эффектов будет JSLoadNamed => SpeculativeSafeIntegerAdd => JSStoreNamed. TurboFan должен убедиться, что эти внешние эффекты узлов не переупорядочиваются, иначе мы можем получить неправильную защиту. Редуктор, как подробно описано в v8/src/compiler/graph-reducer.h, пытается упростить данный узел на основе его оператора и входов. Существует несколько типов редукторов, таких как складывание констант, когда если мы складываем две константы друг с другом, мы складываем их в одну, т.е. 3 + 5 теперь будет просто одним узлом константы 8, и уменьшение силы, когда если значение добавляется к узлу без эффектов, мы сохраняем один узел, т.е. x + 0 будет просто узлом x.
Мы можем проследить эти типы сокращений с помощью флага --trace_turbo_reduction. Если мы снова запустим нашу функцию hot_function с этим флагом, то получим такой результат.
Код:
C:\dev\v8\v8\out\x64.debug>d8 --trace_turbo_reduction hot_function.js
- Replacement of #12: Parameter[-1, debug name: %closure](0) with #41: HeapConstant[0x00c800259781 <JSFunction hot_function (sfi = 000000C800259679)>] by reducer JSContextSpecialization
- Replacement of #34: JSLoadProperty[sloppy, FeedbackSource(#2)](14, 30, 5, 4, 35, 31, 26) with #47: LoadElement[tagged base, 8, Signed31, kRepTaggedSigned|kTypeInt32, FullWriteBarrier](44, 46, 46, 26) by reducer JSNativeContextSpecialization
- Replacement of #42: Checkpoint(33, 31, 26) with #31: Checkpoint(33, 21, 26) by reducer CheckpointElimination
- In-place update of #36: NumberConstant[0] by reducer Typer
... snip ...
- In-place update of #26: Merge(24, 27) by reducer BranchElimination
- In-place update of #43: CheckMaps[None, 0x00c80024dcb9 <Map[16](PACKED_SMI_ELEMENTS)>, FeedbackSource(INVALID)](61, 62, 26) by reducer RedundancyElimination
- Replacement of #43: CheckMaps[None, 0x00c80024dcb9 <Map[16](PACKED_SMI_ELEMENTS)>, FeedbackSource(INVALID)](61, 62, 26) with #62: CheckInternalizedString(2, 18, 8) by reducer LoadElimination
- In-place update of #44: LoadField[JSObjectElements, tagged base, 8, Internal, kRepTaggedPointer|kTypeAny, PointerWriteBarrier, mutable](61, 62, 26) by reducer RedundancyElimination
- Replacement of #44: LoadField[JSObjectElements, tagged base, 8, Internal, kRepTaggedPointer|kTypeAny, PointerWriteBarrier, mutable](61, 62, 26) with #50: HeapConstant[0x00c800259811 <FixedArray[3]>] by reducer LoadElimination
- In-place update of #45: LoadField[JSArrayLength, tagged base, 12, Range(0, 134217725), kRepTaggedSigned|kTypeInt32, NoWriteBarrier, mutable](61, 62, 26) by reducer RedundancyElimination
- Replacement of #45: LoadField[JSArrayLength, tagged base, 12, Range(0, 134217725), kRepTaggedSigned|kTypeInt32, NoWriteBarrier, mutable](61, 62, 26) with #59: NumberConstant[3] by reducer LoadElimination
... snip ...Этот флаг выводит много интересных результатов, и, как вы можете видеть, выполняется множество различных редукторов и исключений. Мы кратко рассмотрим некоторые из них позже в этом посте, но я хочу, чтобы вы внимательно посмотрели на некоторые из этих сокращений.
Например, этот:
Код:
In-place update of #43: CheckMaps[None, 0x00c80024dcb9 <Map[16](PACKED_SMI_ELEMENTS)>, FeedbackSource(INVALID)](61, 62, 26) by reducer RedundancyEliminationДа, вы правильно прочитали - CheckMaps был обновлен и позже заменен из-за использования RedundancyElimination. Это произошло потому, что устранение избыточности обнаружило, что вызов CheckMaps был избыточной проверкой, и удалило все, кроме первой, в том же пути потока управления. В этот момент я знаю, что некоторые из вас могут подумать: "Разве это не уязвимость безопасности"? Ответ на этот вопрос - "потенциально" и "зависит от ситуации".
Прежде чем я объясню это более подробно, давайте рассмотрим следующий пример кода:
Код:
function hot_function(obj) {
return obj.a + obj.b;
}Как видите, этот код довольно прост. Он принимает один объект и возвращает сумму значений из свойств a и b. Если мы посмотрим на граф оптимизации Typer, то увидим следующее.
Как вы можете видеть, когда мы входим в нашу функцию, мы сначала вызываем CheckMaps, чтобы проверить, что карта объекта, который мы передаем, соответствует наличию свойств a и b. Если проверка пройдена, мы вызываем LoadField для загрузки смещения 12 из константы Parameter, которое является свойством a из объекта obj, который мы передали. Сразу после этого мы выполняем еще один вызов CheckMaps, чтобы снова проверить карту, а затем загружаем свойство b. После этого мы вызываем функцию JSAdd, чтобы сложить числа, строки или и то, и другое вместе. Проблема здесь заключается в избыточном вызове CheckMaps, поскольку, как мы знаем, карта этого объекта, которую мы передаем, не может измениться между двумя операциями CheckMap. В этом случае она будет удалена.
Мы можем видеть это устранение избыточности в упрощенной нижней фазе графа.
Как вы можете видеть, второй узел CheckMaps теперь удален, и после первой проверки мы просто загружаем оба свойства одно за другим - по сути, ускоряя наш код. Также, благодаря упрощению, вызов JSAdd был опущен до варианта машинного кода для проверки целочисленных и строковых выражений в соответствии со стандартом ECMAScript. Итак, возвращаясь к нашему вопросу о том, является ли это уязвимостью безопасности или нет. Как уже было сказано, "это зависит". Причина в том, что определенные операции могут вызвать побочные эффекты для наблюдаемого выполнения нашего контекста - вот почему у нас есть цепочки побочных эффектов. Если TurboFan по какой-то причине забыл учесть побочный эффект и не записал его в цепочку побочных эффектов, то возможно, что карта объекта может измениться во время выполнения, например, другой вызов пользовательской функции изменит объект или добавит свойство. Каждая операция промежуточного представления в V8 имеет различные флаги, связанные с ней. Пример некоторых флагов для операторов JavaScript можно увидеть в v8/src/compiler/js-operator.cc Некоторые из этих флагов имеют определенные предположения. Например, V(ToString, Operator::kNoProperties, 1, 1) предполагает, что строка не должна иметь свойств. Другой флаг, например V(LoadMessage, Operator::kNoThrow | Operator::kNoWrite, 0, 1), предполагает, что операция LoadMessage не будет иметь наблюдаемых побочных эффектов через флаг kNoWrite. Этот флаг kNoWrite фактически не записывает в цепочку эффектов. Как видите, если мы можем заставить компилятор удалить проверку избыточности для операции, которая, похоже, считает, что у нее нет побочных эффектов, то у вас есть потенциально эксплуатируемая ошибка, если вы можете изменить объект или свойство во время выполнения скомпилированного кода. Эта тема об устранении избыточности и побочных эффектов может быть расширена, чтобы обсудить, как ошибки, возникающие в результате этих проверок устранения избыточности, могут привести к уязвимостям, которые можно использовать. Но прежде чем мы это сделаем, давайте вкратце рассмотрим некоторые другие распространенные оптимизации.
Другие оптимизации
Как видно из вывода флага --trace_turbo_reduction, существует гораздо больше оптимизаций, которые происходят в TurboFan, чем те, о которых мы говорили. Я постарался рассказать о наиболее важных из них, связанных с ошибкой, которую мы будем эксплуатировать в части 3, но я все же хочу быстро рассказать о некоторых других оптимизациях, чтобы вы хотя бы в общих чертах понимали, что это такое.
Ниже перечислены некоторые другие общие оптимизации, которые вы увидите в TurboFan:
Оптимизация управления: Как определено в v8/src/compiler/control-flow-optimizer.cc, эта оптимизация обычно работает над оптимизацией потока графа и превращает определенные цепочки ветвей в переключатели.
Анализ псевдонимов и глобальная нумерация значений: Анализ псевдонимов выявляет зависимости между узлами Store и Load. Так, если две операции загрузки зависят от одной, они не могут быть выполнены до завершения первой операции, т.е. x = 2; y = x + 2; z = x + 2. GVN, или глобальная нумерация значений, следует за номером и удаляет избыточные операции хранения и загрузки, т.е. z = x + 2 может быть удалено, а z может быть установлено в y, поскольку эта операция является избыточной.
Устранение мертвого кода (DCE): Устранение мертвого кода - это именно то, что звучит. Он просто перебирает все узлы и удаляет код, который не будет выполнен. Например, если x и y для утверждения True/False всегда истинны, то ложный путь будет считаться "мертвым" и удален.
Если вы хотите узнать больше о различных оптимизациях и узнать больше о море узлов, я советую прочитать "TurboFan JIT Design" и "Введение в TurboFan".
Общие уязвимости JIT-компилятора
Имея представление о полном конвейере V8 и оптимизациях компилятора, мы можем теперь начать изучать и понимать, какие классы уязвимостей присутствуют в браузерах. Как мы знаем, движок JavaScript и все его компоненты, такие как компилятор, реализованы на C++. В этом случае конвейер в первую очередь уязвим к обычным нарушениям памяти и безопасности типов, таким как переполнения и недополнения целых чисел, ошибки off-by-one, запрещенные чтения и записи, переполнения буфера, переполнения кучи, и, конечно же, ошибки use-after-free и другие. В дополнение к обычным ошибкам C++, мы также можем иметь логические ошибки и ошибки генерации машинного кода, которые могут возникнуть на этапе оптимизации из-за природы спекулятивных предположений. Такие логические ошибки могут возникать из-за неправильного предположения о потенциальных побочных эффектах, которые операция может оказать на объект или свойство, или из-за неправильных проходов оптимизации, которые удаляют критические защиты типов.
Вложения
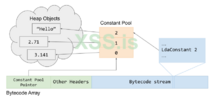
Последнее редактирование: