ОРИГИНАЛЬНАЯ СТАТЬЯ
ПЕРЕВЕДЕНО СПЕЦИАЛЬНО ДЛЯ xss.pro
$600 на SSD для Jolah Milovski ---> 0x5B1f2Ac9cF5616D9d7F1819d1519912e85eb5C09 для поднятия ноды ETHEREUM и тестов
Веб-браузеры, наши обширные ворота в Интернет. Сегодня браузеры играют жизненно важную роль в современных организациях, поскольку все больше и больше программных приложений доставляются пользователям через веб-браузер в виде веб-приложений. Почти все, что вы, возможно, делаете в Интернете, связано с использованием веб-браузера, и в результате браузеры являются одними из наиболее часто используемых потребительских программных продуктов на планете.
Являясь воротами в Интернет, браузеры также создают значительные риски для целостности персональных вычислительных устройств. Теперь мы слышим это почти ежедневно: « Ошибка Google Chrome активно используется как нулевой день » или « Google подтверждает четвертый эксплойт нулевого дня в Chrome в 2022 году ». На самом деле эксплойты браузера не новы, они происходят уже много лет, и первым известным задокументированным эксплойтом удаленного выполнения кода является CVE-1999-0280 . Первым потенциально публичным раскрытием эксплойта браузера, используемого в дикой природе, был эксплойт Aurora для Internet Explorer, который затронул Google еще в декабре 2010 года.
Мой интерес к веб-браузерам впервые вспыхнул еще в 2018 году, когда мой приятель Майкл Вебер познакомил меня с разработкой наступательных расширений для браузера , которая действительно открыла мне глаза на потенциальную поверхность атаки. После этого я начал глубже копаться во внутренностях Chrome и стал очень интересоваться эксплуатацией веб-браузера. Потому что давайте будем честными, какая Красная команда не хотела бы эксплойта «в один клик» или даже «без клика» в веб-браузере?
Когда дело доходит до браузеров в мире исследований в области безопасности, они считаются одними из самых впечатляющих целей для поиска уязвимостей. изучение внутреннего устройства браузера кажется недостижимой целью для многих исследователей.
Несмотря на это, я предпринял шаги, чтобы погрузиться, maxpl0it « Введение в жесткие целевые внутренние пройдя удивительный учебный курс органы». Который я настоятельно рекомендую вам взять! Этот курс предоставил мне много справочной информации о внутренней работе и внутреннем устройстве браузеров, таких как Chrome и Firefox. После этого я отправился на гонки, читая все, что мог, от блогов Chromium до постов разработчиков v8.
Поскольку мой метод обучения больше похож на стиль «изучай, учи, знай», я публикую серию сообщений в блоге «Использование браузера Chrome», чтобы дать вам представление о внутреннем устройстве браузера и более подробно изучить использование браузера Chrome в Windows. глубину, все время изучая это сам.
Теперь вы можете спросить меня, почему Chrome и почему Windows? Ну две причины:
Итак, без лишних слов — давайте углубимся в сложный мир эксплуатации браузера!
В сегодняшней записи блога мы рассмотрим основные предварительные концепции, которые нам необходимо полностью понять, прежде чем копнуть глубже. Будут обсуждаться следующие темы:
На самом деле сегодня используется множество различных JS-движков, например:
Как мы знаем, JavaScript — это легкий, интерпретируемый , объектно-ориентированный язык сценариев. В интерпретируемых языках код выполняется построчно, и результат выполнения кода возвращается немедленно, поэтому нам не нужно компилировать код в другую форму до того, как браузер запустит его. Обычно это не делает такие языки хорошими из-за соображений производительности. В этом случае речь идет о компиляции, такой как компиляция Just-In-Time; где код JavaScript анализируется в байт-код (который является абстракцией машинного кода), а затем дополнительно оптимизируется JIT, чтобы сделать код намного более эффективным и в некотором смысле «быстрым».
Теперь, хотя каждый из вышеупомянутых движков JavaScript может иметь разные компиляторы и оптимизаторы, все они в значительной степени спроектированы и реализованы одинаково на основе стандарта EcmaScript (который также взаимозаменяемо используется с JavaScript). Спецификация EcmaScript подробно описывает, как JavaScript должен быть реализован браузером, чтобы программа JavaScript работала одинаково во всех браузерах.
Итак, что на самом деле происходит после того, как мы выполняем код JavaScript? Ну, чтобы детализировать это, я предоставил диаграмму ниже, которая показывает высокоуровневый обзор общего «потока», также известного как конвейер компиляции движков JavaScript.
 Поначалу это может показаться запутанным, но не волнуйтесь — на самом деле это не так уж сложно понять. Итак, давайте шаг за шагом разберем «поток» и объясним, что делает каждый из этих компонентов.
Поначалу это может показаться запутанным, но не волнуйтесь — на самом деле это не так уж сложно понять. Итак, давайте шаг за шагом разберем «поток» и объясним, что делает каждый из этих компонентов.
 Теперь не беспокойтесь, если некоторые из этих концепций или функций, таких как компиляторы и оптимизации, в настоящее время не имеют смысла. Нет необходимости понимать весь конвейер компиляции для сегодняшнего поста, но у нас должно быть общее представление о том, как работает движок в целом. Мы более подробно рассмотрим конвейер V8 и его компоненты во втором посте этой серии.
Теперь не беспокойтесь, если некоторые из этих концепций или функций, таких как компиляторы и оптимизации, в настоящее время не имеют смысла. Нет необходимости понимать весь конвейер компиляции для сегодняшнего поста, но у нас должно быть общее представление о том, как работает движок в целом. Мы более подробно рассмотрим конвейер V8 и его компоненты во втором посте этой серии.
До тех пор, если вы хотите узнать больше о конвейере, я предлагаю посмотреть « JavaScript Engines: The Good Parts », чтобы лучше понять.
Единственное, что вы должны понять из этого конвейера компиляции в настоящее время, это то, что интерпретатор — это « стековая машина » или, по сути, виртуальная машина (VM), где выполняется байт-код. С точки зрения Ignition (интерпретатор V8) интерпретатор на самом деле является «регистровой машиной» с регистром-аккумулятором. Ignition по-прежнему использует стек, но предпочитает хранить данные в регистрах, чтобы ускорить процесс.
Я предлагаю вам прочитать « Понимание байт-кода V8 » и « Запуск интерпретатора зажигания », чтобы лучше понять эти концепции.
Этот раздел является одной из самых важных частей, которую вам необходимо понять, если вы хотите использовать ошибки в V8, а также в других движках JavaScript. Потому что, как оказалось, все основные движки реализуют объектную модель JavaScript схожим образом.
Как мы знаем, JavaScript — это язык с динамической типизацией. Это означает, что информация о типе связана со значениями времени выполнения, а не с переменными времени компиляции, как в C++. Это означает, что свойства любого объекта в JavaScript могут быть легко изменены во время выполнения. JavaScript Система типов определяет такие типы данных, как Undefined, Null, Boolean, String, Symbol, Number и Object (включая массивы и функции).
Простыми словами, что это значит? Ну, обычно это означает, что объект или примитив, такой как varв JavaScript может изменять свой тип данных во время выполнения, в отличие от C++. Например, давайте установим новую переменную с именем itemв JavaScript и установите его в 42.
var item = 42;
Используя typeof в оператор itemпеременная, мы видим, что она возвращает свой тип данных, который будет Number.
typeof item
'number'
Теперь, что произойдет, если мы попытаемся установить itemв строку, а затем проверить ее тип данных?
item = "Hello!";
typeof item
'string'
Посмотрите на это, itemпеременная теперь установлена на тип данных Stringи не Number. Именно это делает JavaScript «динамичным» по своей природе. В отличие от C++, если мы попытаемся создать intили целочисленную переменную, а позже попытался установить ее в строку, это не удалось - вот так:
int item = 3;
item = "Hello!"; // error: invalid conversion from 'const char*' to 'int'
// ^~~~~~~~
Хотя это круто в JavaScript, для нас это создает проблему. V8 и Ignition написаны на C++, поэтому интерпретатору и компилятору необходимо выяснить, как JavaScript собирается использовать некоторые данные. Это очень важно для эффективной компиляции кода, особенно потому, что в C++ существуют различия в размерах памяти для таких типов данных, как intили же char.
Помимо эффективности, это также имеет решающее значение для безопасности, поскольку, если интерпретатор и компилятор «интерпретируют» код JavaScript неправильно и мы получаем объект словаря вместо объекта массива, у нас появляется уязвимость Type Confusion.
Так как же V8 хранит всю эту информацию для каждого значения времени выполнения и как движок остается эффективным?
Ну, в V8 это достигается за счет использования выделенного объекта информационного типа, называемого Map (не путать с Map Objects ), который иначе известен как « Скрытый класс ». Иногда вы можете услышать, что Карта называется « Формой », особенно в JavaScript-движке Mozilla SpiderMonkey. V8 также использует то, что называется сжатием указателя или тегированием указателя в памяти (которое мы обсудим позже в этом посте), чтобы уменьшить потребление памяти и позволяет V8 представлять любое значение в памяти как указатель на объект.
Но прежде чем мы слишком углубимся в то, как все это работает, нам сначала нужно понять, что такое объекты JavaScript и как они представлены в V8.
Каждый объект в JavaScript имеет связанные с ним свойства, которые можно просто объяснить как переменную, которая помогает определить характеристики объекта. Например, недавно созданный carобъект может иметь такие свойства, как make, model, а также yearкоторые помогают определить, что carобъект есть. Вы можете получить доступ к свойствам объекта либо с помощью простого оператора записи через точку, такого как objectName.propertyNameили через скобки, такие как objectName['propertyName'].
Кроме того, каждое свойство объектов сопоставляется с атрибутами свойств , которые используются для определения и объяснения состояния свойств объектов. Пример того, как эти атрибуты свойств выглядят в объекте JavaScript, можно увидеть ниже.
http://xssforum7mmh3n56inuf2h73hvhnzobi7h2ytb3gvklrfqm7ut3xdnyd.onion/attachments/46566/
Теперь, когда мы немного понимаем, что такое объект, следующим шагом будет понимание того, как этот объект структурирован в памяти и где он хранится.
Всякий раз, когда создается объект, V8 создает новый объект JSObject и выделяет для него память в куче. Значение объекта является указателем на JSObjectкоторый содержит в своей структуре следующее:
 Глядя на структуру JSObject, мы видим, что свойства и элементы хранятся в двух отдельных FixedArray структурах данных, что делает добавление и доступ к свойствам или элементам более эффективным. Структура элементов преимущественно хранит неотрицательные целые числа или индексированные по массиву свойства (ключи), которые обычно называются элементами. Что касается структуры свойств, если ключ свойства объекта не является неотрицательным целым числом, например строкой, свойство будет храниться либо как свойство встроенного объекта (объяснено позже в посте), либо в структуре свойств, также иногда называется резервным хранилищем свойств объектов.
Глядя на структуру JSObject, мы видим, что свойства и элементы хранятся в двух отдельных FixedArray структурах данных, что делает добавление и доступ к свойствам или элементам более эффективным. Структура элементов преимущественно хранит неотрицательные целые числа или индексированные по массиву свойства (ключи), которые обычно называются элементами. Что касается структуры свойств, если ключ свойства объекта не является неотрицательным целым числом, например строкой, свойство будет храниться либо как свойство встроенного объекта (объяснено позже в посте), либо в структуре свойств, также иногда называется резервным хранилищем свойств объектов.
Мы должны отметить одну вещь: хотя именованные свойства хранятся так же, как элементы массива, они не совпадают, когда речь идет о доступе к свойствам. В отличие от элементов, мы не можем просто использовать ключ, чтобы найти позицию именованных свойств в массиве свойств; нам нужны некоторые дополнительные метаданные. Как упоминалось ранее, V8 использует специальный объект, называемый HiddenClass или же Map это связано с JSObject. Там хранится вся информация об объектах JavaScript, что, в свою очередь, позволяет V8 быть «динамическим».
Итак, прежде чем мы углубимся в понимание структуры JSObject и его свойств, нам сначала нужно посмотреть и понять, как же этот HiddenClass работает в V8.
HiddenClass (Map) и Shape Transitions
Как обсуждалось ранее, мы знаем, что JavaScript — это язык с динамической типизацией. В частности, из-за этого в JavaScript нет понятия классов. В C++, если вы создаете класс или объект, вы не можете добавлять или удалять из него методы и свойства на лету, в отличие от JavaScript. В C++ и других объектно-ориентированных языках вы можете хранить свойства объекта с фиксированным смещением в памяти, потому что макет объекта для экземпляра данного класса никогда не изменится, но в JavaScript он может динамически изменяться во время выполнения. Чтобы бороться с этим, JavaScript использует так называемое «наследование на основе прототипа», где каждый объект имеет ссылку на объект-прототип или «форму», чьи свойства он включает.
Так как же V8 хранит макет объекта?
Вот тут HiddenClass или же Map вступают в игру. Скрытые классы работают аналогично макету фиксированных объектов, где значения свойств (или указатели на эти свойства) могут быть сохранены в определенной структуре памяти, а затем доступны с фиксированным смещением между каждым из них. Эти смещения генерируются Torque и могут быть найдены в /torque-generated/src/objects/*.tq.inc. Это в значительной степени служит идентификатором «формы» объекта, что, в свою очередь, позволяет V8 лучше оптимизировать код JavaScript и сократить время доступа к свойствам.
Как ранее было замечено в JSObjectВ приведенном выше примере map — это еще одна структура данных внутри объекта. Эта структура содержит следующую информацию:

Теперь, когда мы понимаем, как выглядит макет map, давайте объясним эту «форму», о которой мы постоянно говорим. Как известно, каждый вновь созданный JSObject будет иметь собственный скрытый класс, который содержит смещение памяти для каждого из его свойств. Вот интересная часть; если в любой момент свойство этого объекта будет создано, удалено или изменено динамически, то будет создан новый скрытый класс.Этот новый скрытый класс хранит информацию о существующих свойствах с включением смещения памяти для нового свойства. Теперь обратите внимание, что новый скрытый класс создается только при добавлении нового свойства, добавление свойства с индексом массива не создает новые скрытые классы.
Итак, как это выглядит на практике? Хорошо, давайте рассмотрим следующий код:
В начале мы создаем новый объект с именем obj1, который создается и хранится в куче V8. Поскольку это только что созданный объект, нам необходимо создать HiddenClass (очевидно), хотя для этого объекта еще не определены никакие свойства. HiddenClass также создается и хранится в куче V8. В целях нашего примера мы назовем этот HiddenClass «C0».

Как только будет достигнута следующая строка кода и obj1.x = 1 выполняется, V8 создаст второй HiddenClass с именем «C1», основанный на C0. C1 будет первым HiddenClass, описывающим расположение свойства where. x можно найти в памяти. Но вместо сохранения указателя на значение для x на самом деле он будет хранить смещение для x который будет со смещением 0.

Хорошо, я знаю, что в этот момент некоторые из вас могут спросить: «Почему смещение к свойству, а не к его значению»?
Ну, в V8 это оптимизационный трюк. Карты являются относительно дорогими объектами с точки зрения использования памяти. Если мы храним пары свойств ключ-значение в формате словаря в каждом вновь созданном JSObject тогда это вызовет много вычислительных накладных расходов, поскольку синтаксический анализ словарей выполняется медленно. Во-вторых, что произойдет, если новый объект, такой как obj2 создается с теми же свойствами, что и obj1 такие как xа также y? Несмотря на то, что значения могут быть разными, два объекта на самом деле имеют одни и те же именованные свойства в одном и том же порядке или, как мы бы назвали это, в одной и той же «форме». В этом случае было бы расточительно хранить одно и то же имя свойства в двух разных местах.
И это позволяет V8 быть быстрым, он оптимизирован таким образом, чтобы map была максимально распространена между объектами одинаковой формы. Поскольку имена свойств повторяются для всех объектов в одной и той же форме и поскольку они находятся в одном и том же порядке, может быть несколько объектов, указывающих на один единственный HiddenClass в памяти со смещением на свойства вместо указателей на значения. Это также упрощает сборку мусора, так как map — это распределение памяти. Чтобы лучше объяснить эту концепцию, давайте на мгновение отвлечемся от нашего примера выше и рассмотрим важные части HiddenClass. Две наиболее важные части HiddenClass, которые позволяют Map иметь свою «форму», — это DescriptorArray и третье битовое поле. Если вы вернетесь к приведенной выше структуре Map, то заметите, что третье битовое поле хранит количество свойств, а массив дескрипторов содержит информацию об именованных свойствах, например, само имя, позиция, в которой хранится значение (смещение). и атрибуты свойств.
Например, предположим, что мы создаем новый объект, такой как var obj {x: 1}. Свойство x будет храниться в свойствах In-Object или в хранилище свойств объекта JavaScript. Поскольку создается новый объект, также будет создан новый HiddenClass. Внутри этого HiddenClass будут заполнены массив дескрипторов и третье битовое поле. Третье битовое поле устанавливает numberOfOwnDescriptors в 1, так как у нас есть только одно свойство, а затем массив дескрипторов будет заполнять части ключа, сведений и значений массива сведениями, относящимися к свойству x. Значение этого дескриптора будет равно 0. Почему 0? Что ж, свойства In-Object и хранилище свойств — это просто массив. Итак, установив значение дескриптора на 0, V8 знает, что значение ключей будет по смещению 0 этого массива для любого объекта той же формы.
Наглядный пример того, что мы только что объяснили, можно увидеть ниже.
Давайте посмотрим, как это выглядит в V8. Для начала запустим d8с --allow-natives-syntax и выполните следующий код JavaScript:
После завершения мы будем использовать %DebugPrint() для нашего объекта, чтобы отобразить его свойства, карту и другую информацию, такую как дескриптор экземпляра. После выполнения обратим внимание на:

Желтым цветом выделим наш объект obj1. Красным указатель на наш HiddenClass или Map. В этом HiddenClass у нас есть дескриптор экземпляра, который указывает на DescriptorArray. С использованием %DebugPrintPtr(), указателя на этот массив, мы можем увидеть более подробную информацию о том, как этот массив выглядит в памяти, которая выделена синим цветом .
Обратите внимание, у нас есть три свойства, что соответствует количеству дескрипторов в разделе дескрипторов экземпляров карты. Ниже мы видим, что массив дескрипторов содержит ключи наших свойств, а const data field содержит смещения связанных с ними значений в хранилище свойств. Теперь, если мы пойдем по стрелке назад от смещений к нашему объекту, мы заметим, что смещения действительно совпадают, и каждому свойству назначено правильное значение.
Кроме того, обратите внимание, что справа от этих свойств вы можете увидеть местоположение каждого из этих свойств; которые находятся в объекте , как я упоминал ранее. Это в значительной степени доказывает нам, что смещения относятся к свойствам в хранилище In-Object и Properties.
Хорошо, теперь, когда мы понимаем, почему мы используем смещения, давайте вернемся к нашему предыдущему примеру HiddenClass. Как мы уже говорили, добавив свойство x к obj1, теперь у нас будет только что созданный HiddenClass с именем «C1» со смещением на x. Поскольку мы создаем новый HiddenClass, V8 обновит C0 «переходом класса», в котором говорится, что если новый объект создается со свойством x, то скрытый класс должен переключиться прямо на C1.
Затем процесс повторяется, когда мы выполняем obj1.y = 2. Будет создан новый скрытый класс с именем C2, а в C1 добавлен переход класса, указывающий, что для любого объекта со свойством x, если свойство yдобавляется, то скрытый класс должен перейти на C2. В конце концов, все эти переходы классов создают нечто, известное как «дерево переходов».

Кроме того, следует отметить, что переходы классов зависят от порядка, в котором свойства добавляются к объекту. Таким образом, если бы z было добавлено после y, «форма» уже не была бы той же самой и следовала бы тому же пути перехода от C1 к C2. Вместо этого будет создан новый скрытый класс, и будет добавлен новый путь перехода из C1 для учета этого нового свойства, что еще больше расширит дерево переходов.

Теперь, когда мы это поняли, давайте посмотрим, как объекты выглядят в памяти, когда карта используется совместно двумя объектами одинаковой формы.
Для начала запустите d8 снова с --allow-natives-syntax параметр, а затем введите следующие две строки кода JavaScript:
После завершения мы снова будем использовать %DebugPrint() для каждого из наших объектов, чтобы отобразить их свойства, map и другую информацию. После выполнения обратите внимание на следующее:

Желтым цветом оба наших объекта, obj1 а также obj2. Обратите внимание, что каждый является JS_OBJECT_TYPE с другим адресом памяти в куче, потому что очевидно, что это отдельные объекты с потенциально разными свойствами. Как мы знаем, оба этих объекта имеют одинаковую форму, поскольку они оба содержат x и y в одном и том же порядке. В этом случае в Blue мы видим, что свойства находятся в одном и том же FixedArray со смещением для x и y равным 0 и 1 соответственно. Причина этого в том, что, как мы уже знаем, объекты одинаковой формы совместно используют HiddenClass (представленный красным цветом ), который будет иметь один и тот же массив дескрипторов.
Как видите, большинство свойств объекта и адресов карты будут одинаковыми, и все потому, что оба этих объекта используют одну карту.
Теперь сосредоточимся на back_pointer это выделено зеленым цветом. Если вы вернетесь к нашему примеру перехода карты C0 в C2, вы заметите, что мы упомянули нечто, называемое «деревом перехода». Это дерево переходов создается V8 в фоновом режиме каждый раз, когда создается новый HiddenClass, и позволяет V8 связывать новый и старый HiddenClass вместе. Этот back_pointer является частью этого дерева переходов, поскольку указывает на родительскую карту, откуда произошел переход. Это позволяет V8 пройти по цепочке обратных указателей, пока не найдет карту, содержащую свойства объектов, то есть их форму.
Давайте использовать d8чтобы глубже понять, как это работает. Мы будем использовать %DebugPrintPtr() еще раз, чтобы распечатать детали указателя адреса в V8. В этом случае мы возьмем back_pointer, чтобы просмотреть его детали. После этого ваш вывод должен быть похож на:

Зеленым цветом выделено как back_pointer определяет JS_OBJECT_TYPE в памяти, которая на деле оказывается map! Эта map — та самая map C1, о которой мы говорили ранее. Мы знаем, как map может вернуться к своему предыдущему состоянию. Что ж, если мы внимательно посмотрим на информацию в этой карте, мы заметим, что под указателем дескриптора экземпляра есть раздел «переходы», выделенный красным цветом. Этот раздел перехода содержит информацию, на которую указывает необработанный указатель перехода в структуре карты.
В V8 переходы map используется TransitionsAccessor. Это вспомогательный класс, который инкапсулирует доступ к различным способам, которыми map может хранить переходы к другим map в соответствующем поле в Map::kTransitionsOrPrototypeInfo, известный как необработанный указатель перехода, о котором мы упоминали ранее. Этот указатель указывает на TransitionArray, который снова является FixedArray который содержит переходы map для изменения свойств.
Оглядываясь назад на выделенный красным цветом раздел, мы видим, что в этом массиве переходов есть только один. В этом массиве мы видим, что переход № 1 детализирует переход, когда свойство y добавляется к объекту. Если добавляется y, это говорит map обновить себя из map, хранящейся в 0x007f00259735 которая соответствует нашей текущей map. В случае, если был другой переход, например, z был добавлен к x вместо y, тогда у нас было бы два элемента в этом массиве переходов, каждый из которых указывал бы на соответствующую map для этой формы объектов.
ПРИМЕЧАНИЕ . Если вы хотите поиграть с map и получить другое визуальное представление переходов map я рекомендую использовать инструмент V8 Indicium . Инструменты представляют собой унифицированный веб-интерфейс, который позволяет отслеживать, отлаживать и анализировать закономерности создания и изменения map в реальных приложениях.
Что произойдет с деревом переходов, если мы удалим свойство? Ну, в этом случае есть нюанс в том, что V8 создает новую map каждый раз, когда происходит удаление свойства. Как мы знаем, map являются относительно дорогими, когда речь идет об использовании памяти, поэтому в определенный момент стоимость наследования и поддержки дерева переходов будет расти и медленнее. В случае удаления последнего свойства объекта map просто отрегулирует указатель назад, чтобы вернуться к предыдущей map вместо создания новой. Но что произойдет, если мы удалим среднее свойство объекта? Что ж, в этом случае V8 перестанет поддерживать дерево переходов всякий раз, когда мы добавляем слишком много атрибутов или удаляем не последние элементы, и переключается в более медленный режим, известный как режим словаря.
Итак, что же это за режим словаря? Что ж, теперь, когда мы знаем, как V8 использует HiddenClasses для отслеживания формы объектов, мы можем вернуться назад и углубиться в понимание того, как эти свойства и элементы на самом деле хранятся и обрабатываются в V8.
Характеристики
Как объяснялось ранее, мы знаем, что объекты JavaScript имеют два основных типа свойств: именованные свойства и индексированные элементы. Мы начнем с рассмотрения именованных свойств. Если вы помните наше обсуждение карт и массива дескрипторов, мы упоминали, что именованные свойства хранятся либо в объекте, либо в массиве свойств. Что это за свойство в объекте, о котором мы говорим?
Что ж, в V8 этот режим является очень быстрым методом сохранения свойств непосредственно в объекте, поскольку они доступны без каких-либо косвенных действий. Хотя они очень быстрые, они также ограничены начальным размером объекта. Если добавляется больше свойств, чем есть места в объекте, то новые свойства сохраняются в хранилище свойств, что добавляет один уровень косвенности.
В общем, есть два «режима», которые движки JavaScript используют для хранения свойств, и они называются:

Здесь также необходимо отметить одну вещь. Переходы формы работают только для быстрых свойств, а не для медленных свойств, поскольку формы словаря используются только одним объектом, поэтому они не могут быть разделены между разными объектами и, следовательно, не имеют переходов.
Элементы
Хорошо, на данный момент мы в значительной степени рассмотрели именованные свойства. Теперь давайте взглянем на свойства или элементы, индексированные в массиве. Можно было бы подумать, что обработка индексированных свойств будет менее сложной… но вы ошибаетесь, полагая это. Обработка элементов не менее сложна, чем именованные свойства. Несмотря на то, что все индексированные свойства хранятся в хранилище элементов, V8 делает очень точное различие в том, какие элементы содержит каждый массив. примерно 21 тип элементов На самом деле в этом магазине можно отслеживать! Это изначально позволяет V8 оптимизировать любые операции над массивом специально для этого типа элемента.
Что я имею в виду? Что ж, возьмем, к примеру, эту строку кода:
В JavaScript, если запустим typeof массив содержит numbers потому что JavaScript не различает целое число, число с плавающей запятой или двойное число. Однако V8 делает гораздо более точные различия и классифицирует этот массив как PACKED_SMI_ELEMENTS, где SMI относится к малым целым числам.
Так что там с SMI? Ну, V8 отслеживает, какие элементы содержит каждый массив. Затем он использует эту информацию для оптимизации операций с массивами для этого типа элементов. В V8 есть три различных типа элементов, о которых нам нужно знать, а именно:

Например, давайте возьмем наш пример с массивом из предыдущего:
Как вы можете видеть, V8 отслеживает тип элементов этого массива как упакованный SMI (позже мы подробно расскажем, что такое упакованный). Теперь, если бы мы добавили число с плавающей запятой, то вид элементов массива «перешел бы» на вид элементов Double как таковой.
Причина этого перехода проста, оптимизация работы. Поскольку у нас есть целое число с плавающей запятой, V8 должен иметь возможность выполнять оптимизацию этих значений, чтобы переходить на один шаг вниз к DOUBLES потому что набор чисел, который может быть представлен в виде SMI это подмножество чисел, которые могут быть представлены как двойные. Поскольку переходы типов элементов идут в одну сторону, как только массив помечен более низким типом элементов, например PACKED_DOUBLES_ELEMENTS он больше не может вернуться «наверх» к PACKED_SMI_ELEMENTS, даже если мы заменим или удалим это целое число с плавающей запятой. Как правило, чем более специфичен тип элементов при создании массива, тем более точные оптимизации доступны. Чем дальше вы опускаетесь по типам элементов, тем медленнее могут быть манипуляции с этим объектом.
Далее нам также необходимо понять первое важное отличие, которое есть у V8, когда он отслеживает резервные хранилища элементов, когда индекс удален или пуст. И это:
Как видите, holey_array имеет «дыры», так как мы забыли добавить 3 в индекс и просто оставил его пустым или неопределенным. Причина, по которой V8 делает это различие, заключается в том, что операции с упакованными массивами могут быть оптимизированы более агрессивно, чем операции с дырявыми массивами. Если вы хотите узнать об этом больше, я предлагаю вам посмотреть выступление Матиаса Байненса « Внутреннее устройство V8 для разработчиков JavaScript », в котором это очень подробно описано.
V8 также реализует ранее упомянутые переходы типов элементов на обоих PACKEDа также HOLEY массивы, образующие «решетку». Простую визуализацию этих переходов можно увидеть ниже.

Опять же, мы должны помнить, что виды элементов имеют односторонние нисходящие переходы через эту решетку. Например, добавление числа с плавающей запятой в массив SMI помечает его как двойное, и аналогичным образом, как только в массиве создается дыра, она навсегда помечается как дырявая, даже если вы ее заполните позже.
V8 также имеет второе важное различие, касающееся элементов, которые нам необходимо понять. В резервных хранилищах элементов, как и в хранилище свойств, элементы также могут быть либо быстрыми, либо в режиме словаря (медленными). Быстрые элементы — это просто массив, в котором индекс свойства соответствует смещению элемента в хранилище элементов. Что касается медленных массивов, то это происходит при наличии больших разреженных массивов, в которых занято всего несколько элементов. В этом случае резервное хранилище массива использует представление словаря, подобное тому, которое мы видели в хранилище свойств, для экономии памяти за счет снижения производительности. Этот словарь будет хранить атрибуты ключа, значения и элемента в значениях триплетов словаря.
Просмотр объектов Chrome в памяти
На данный момент мы рассмотрели множество сложных тем как по JavaScript, так и по внутреннему устройству V8. Надеюсь, к этому моменту у вас уже есть достаточное понимание некоторых концепций, благодаря которым V8 работает «под капотом». Теперь, когда у нас есть эти знания, пора перейти к наблюдению за тем, как V8 и его объекты выглядят в памяти при наблюдении через WinDBG и какие типы оптимизации используются.
Причина, по которой мы используем WinDBG, заключается в том, что когда мы будем писать эксплойты, отлаживать наш POC и т. д., мы в основном будем использовать WinDBG в сочетании с d8. В этом случае нам полезно иметь возможность уловить и понять нюансы структуры памяти V8. Если вы не знакомы с WinDBG, то я предлагаю вам прочитать и ознакомиться с сообщением в « Начало работы с WinDbg (режим пользователя) блоге » от Microsoft и прочитать « Команды GDB для пользователей WinDbg », если вы использовали GDB раньше.
Я знаю, что мы уже заглядывали в структуры памяти объектов и карт, и возились с d8 — так что у нас должно быть общее представление о том, что на что указывает и где вещи находятся в памяти. Но не обманывайтесь, что это будет так просто. Как и все в V8, оптимизация играет большую роль в том, чтобы сделать его быстрым и эффективным, это также относится к тому, как он обрабатывает и хранит значения в памяти.
Что я имею в виду? Что ж, давайте быстро рассмотрим простую структуру объектов V8 с использованием d8 и WinDBG. Для начала давайте снова инициируем
d8 с --allow-natives-syntaxoption и создайте простой объект, например:
После этого давайте продолжим и воспользуемся %DebugPrint() для вывода информации об объектах.
После этого запустите WinDBG и подключите его к процессу d8. Как только отладчик подключится, мы выполним команду dq, за которой следует адрес памяти нашего объекта ( 0x0000020C0010A509) для отображения содержимого памяти. Ваш вывод должен быть очень похож на:

Глядя на вывод WinDBG, мы видим, что используем правильный адрес памяти для объекта. Но когда мы смотрим на содержимое памяти, первый адрес (который должен быть указателем на карту, если вы помните нашу структуру JSObject) кажется поврежденным. Что ж, можно было бы подумать, что он поврежден, более опытные реверс-инженеры или разработчики эксплойтов, возможно, даже подумали бы, что существует проблема смещения/выравнивания, и технически вы были бы близки, но не правы.
Опять же, друзья мои, оптимизация V8 работает. Вы можете понять, почему нам нужно обсудить эти оптимизации, потому что для неопытного глаза вы серьезно потеряетесь и запутаетесь в том, что происходит в памяти. На самом деле мы видим здесь две вещи: сжатие указателя и тегирование указателя.
Мы начнем с разбора Pointer или Value в V8.
Pointer Tagging
Итак, что такое тегирование указателей и почему мы его используем? Насколько нам известно, в V8 значения представлены как объекты и размещены в куче — независимо от того, являются ли они объектом, массивом, числом или строкой. Теперь многие программы JavaScript фактически выполняют вычисления над целыми значениями, поэтому, если бы нам постоянно приходилось создавать новый Number()объект в JavaScript каждый раз, когда мы увеличиваем или изменяем значение, это приводит к накладным расходам времени на создание объекта, отслеживание кучи и увеличивает используемое пространство памяти, что делает это очень неэффективным.
В этом случае, что будет делать V8, так это то, что вместо того, чтобы каждый раз создавать новый объект, он фактически будет хранить некоторые значения в строке. Хотя это работает, это создает для нас вторую проблему. И эта проблема заключается в том, как отличить указатель объекта от встроенного значения? Ну, вот где тегирование указателя вступает в игру.
Техника тегирования указателя основана на наблюдении, что в системах x32 и x64 выделенные данные должны быть выровнены по словам (4 байта). Поскольку данные выравниваются таким образом, младшие значащие биты (LSB) всегда будут равны нулю. Затем при тегировании будут использоваться два младших бита или младшие значащие биты, чтобы различать указатель объекта кучи и целое число или SMI.
В архитектуре x64 используется следующая схема тегов:
Как видно из примера, 0 используется для представления SMI, а 1 — для представления указателя. Следует отметить только одну вещь: вы просматриваете SMI в памяти, хотя они хранятся в строке, они фактически удваиваются, чтобы избежать тега указателя. Итак, если исходное значение равно 1, в памяти будет 2.
В указателе у нас также есть w во втором LSB, который обозначает бит, который используется для различения сильной или слабой ссылки указателя. Если вы не знакомы с тем, что такое сильный и слабый указатель, я объясню. Просто сильный указатель — это указатель, который указывает, что объект, на который он указывает, должен оставаться в памяти (он представляет объект), а слабый указатель — это указатель, который просто указывает на данные, которые могли быть удалены. Когда GC или сборщик мусора удаляет объект, он должен удалить сильный указатель, поскольку он содержит счетчик ссылок.
С этой схемой тегирования указателя арифметические или бинарные операции с целыми числами могут игнорировать тег, поскольку младшие 32 бита будут равны нулю. Однако, когда дело доходит до разыменования HeapObject, V8 должен сначала маскировать младший значащий бит, для чего используется специальный метод доступа, который позаботится об очистке LSB. Теперь, зная это, давайте вернемся к нашему примеру в WinDBG и очистим этот LSB, вычитая 1 из адреса. Затем это должно предоставить нам действительные адреса памяти. После этого ваш вывод должен выглядеть так.

Как видите, как только мы очистили LSB, теперь у нас есть действительные адреса указателей в памяти! В частности, у нас есть карта, свойства, элементы, а затем наши встроенные объекты. Опять же, обратите внимание, что SMI удваиваются, поэтому x, который содержит 1, на самом деле равен 2 в памяти, и то же самое верно для 2, поскольку теперь он равен 4.
Те, у кого зоркий глаз, могли заметить, что только половина указателя на самом деле указывает на объект в памяти. Почему это? Если бы ваш ответ был «еще одна оптимизация», то вы были бы правы. Это то, что называется сжатием указателя, о котором мы сейчас поговорим.
Сжатие указателя
Сжатие указателей в Chrome и V8 использует интересное свойство объектов в куче, а именно то, что объекты кучи обычно расположены близко друг к другу, поэтому наиболее значимые биты указателя, вероятно, будут одинаковыми. В этом случае V8 сохраняет только половину указателя (младшие значащие биты) в памяти и помещает старшие значащие биты (старшие 32 бита) кучи V8 (известной как isolate root) в root register (R13). Всякий раз, когда нам нужно получить доступ к указателю, регистр и значение в памяти просто складываются вместе, и мы получаем наш полный адрес. Схема сжатия реализована в /src/common/ptr-compr-inl.h в V8.
По сути, цель, которую пыталась выполнить команда V8, заключалась в том, чтобы каким-то образом уместить оба типа теговых значений в 32-битные 64-битные архитектуры, в частности, чтобы уменьшить накладные расходы в V8, чтобы попытаться вернуть как можно больше потерянных 4 байтов в пределах х64 архитектура.
ПЕРЕВЕДЕНО СПЕЦИАЛЬНО ДЛЯ xss.pro
$600 на SSD для Jolah Milovski ---> 0x5B1f2Ac9cF5616D9d7F1819d1519912e85eb5C09 для поднятия ноды ETHEREUM и тестов
Веб-браузеры, наши обширные ворота в Интернет. Сегодня браузеры играют жизненно важную роль в современных организациях, поскольку все больше и больше программных приложений доставляются пользователям через веб-браузер в виде веб-приложений. Почти все, что вы, возможно, делаете в Интернете, связано с использованием веб-браузера, и в результате браузеры являются одними из наиболее часто используемых потребительских программных продуктов на планете.
Являясь воротами в Интернет, браузеры также создают значительные риски для целостности персональных вычислительных устройств. Теперь мы слышим это почти ежедневно: « Ошибка Google Chrome активно используется как нулевой день » или « Google подтверждает четвертый эксплойт нулевого дня в Chrome в 2022 году ». На самом деле эксплойты браузера не новы, они происходят уже много лет, и первым известным задокументированным эксплойтом удаленного выполнения кода является CVE-1999-0280 . Первым потенциально публичным раскрытием эксплойта браузера, используемого в дикой природе, был эксплойт Aurora для Internet Explorer, который затронул Google еще в декабре 2010 года.
Мой интерес к веб-браузерам впервые вспыхнул еще в 2018 году, когда мой приятель Майкл Вебер познакомил меня с разработкой наступательных расширений для браузера , которая действительно открыла мне глаза на потенциальную поверхность атаки. После этого я начал глубже копаться во внутренностях Chrome и стал очень интересоваться эксплуатацией веб-браузера. Потому что давайте будем честными, какая Красная команда не хотела бы эксплойта «в один клик» или даже «без клика» в веб-браузере?
Когда дело доходит до браузеров в мире исследований в области безопасности, они считаются одними из самых впечатляющих целей для поиска уязвимостей. изучение внутреннего устройства браузера кажется недостижимой целью для многих исследователей.
Несмотря на это, я предпринял шаги, чтобы погрузиться, maxpl0it « Введение в жесткие целевые внутренние пройдя удивительный учебный курс органы». Который я настоятельно рекомендую вам взять! Этот курс предоставил мне много справочной информации о внутренней работе и внутреннем устройстве браузеров, таких как Chrome и Firefox. После этого я отправился на гонки, читая все, что мог, от блогов Chromium до постов разработчиков v8.
Поскольку мой метод обучения больше похож на стиль «изучай, учи, знай», я публикую серию сообщений в блоге «Использование браузера Chrome», чтобы дать вам представление о внутреннем устройстве браузера и более подробно изучить использование браузера Chrome в Windows. глубину, все время изучая это сам.
Теперь вы можете спросить меня, почему Chrome и почему Windows? Ну две причины:
- Доля рынка Chrome составляет около 73%, что делает его самым широко используемым браузером в мире.
- Доля рынка Windows составляет около 90%, что делает ее самой широко используемой операционной системой в мире.
В целом, к концу этой серии сообщений в блоге мы рассмотрим все, что нам нужно знать, чтобы начать исследовать и использовать потенциальные ошибки Chrome. В последнем посте этой серии мы попытаемся использовать CVE-2018-17463 , уязвимость JIT-компилятора в оптимизаторе Chrome v8 (TurboFan), обнаруженную Сэмюэлем Гроссом .ПРЕДУПРЕЖДЕНИЕ Из-за огромной сложности браузеров, движков JavaScript и JIT-компиляторов эти сообщения в блогах будут очень и очень тяжелыми для чтения.
В настоящее время это будет серия из трех (3) постов в блоге. Но, в зависимости от сложности и объема освещаемой информации, я могу разделить материал на несколько дополнительных постов.
Обратите внимание - я пишу эти сообщения в блоге, когда учусь на этом пути. Так что, пожалуйста, потерпите меня, так как мне может потребоваться некоторое время, чтобы опубликовать последующие посты к этой серии.
При этом, если вы заметили, что я допустил ошибку в своих постах или ввел читателя в заблуждение, то, пожалуйста, свяжитесь со мной! Также очень приветствуются любые рекомендации, конструктивная критика, критические отзывы и т.д.!
Итак, без лишних слов — давайте углубимся в сложный мир эксплуатации браузера!
В сегодняшней записи блога мы рассмотрим основные предварительные концепции, которые нам необходимо полностью понять, прежде чем копнуть глубже. Будут обсуждаться следующие темы:
- Поток движков JavaScript
- Конвейер компилятора JavaScript Engine
- Машины стека и регистрации
- JavaScript и внутреннее устройство V8
- Представление объекта
- Скрытые классы (карта)
- Переходы формы (карты)
- Характеристики
- Элементы и массивы
- Просмотр объектов Chrome в памяти
- Маркировка указателя
- Сжатие указателя
Понимание движков JavaScript
Мы начинаем наше путешествие по внутреннему устройству браузера, сначала понимая, что такое движки JavaScript и как они работают. Механизмы JavaScript являются неотъемлемой частью выполнения кода JavaScript в системах. Раньше они были просто интерпретаторами, но сегодня современные движки JavaScript представляют собой сложные программы, которые включают в себя множество компонентов, улучшающих производительность, таких как оптимизирующие компиляторы и JIT-компиляция.На самом деле сегодня используется множество различных JS-движков, например:
- V8 — высокопроизводительный движок JavaScript и WebAssembly с открытым исходным кодом от Google, используемый в Chrome.
- SpiderMonkey — JavaScript и WebAssembly Engine от Mozilla, используемый в Firefox.
- Charka — собственный движок JScript, разработанный Microsoft для использования в IE и Edge.
- JavaScriptCore — встроенный механизм JavaScript от Apple для использования WebKit в Safari.
Как мы знаем, JavaScript — это легкий, интерпретируемый , объектно-ориентированный язык сценариев. В интерпретируемых языках код выполняется построчно, и результат выполнения кода возвращается немедленно, поэтому нам не нужно компилировать код в другую форму до того, как браузер запустит его. Обычно это не делает такие языки хорошими из-за соображений производительности. В этом случае речь идет о компиляции, такой как компиляция Just-In-Time; где код JavaScript анализируется в байт-код (который является абстракцией машинного кода), а затем дополнительно оптимизируется JIT, чтобы сделать код намного более эффективным и в некотором смысле «быстрым».
Теперь, хотя каждый из вышеупомянутых движков JavaScript может иметь разные компиляторы и оптимизаторы, все они в значительной степени спроектированы и реализованы одинаково на основе стандарта EcmaScript (который также взаимозаменяемо используется с JavaScript). Спецификация EcmaScript подробно описывает, как JavaScript должен быть реализован браузером, чтобы программа JavaScript работала одинаково во всех браузерах.
Итак, что на самом деле происходит после того, как мы выполняем код JavaScript? Ну, чтобы детализировать это, я предоставил диаграмму ниже, которая показывает высокоуровневый обзор общего «потока», также известного как конвейер компиляции движков JavaScript.
- Парсер : как только мы выполняем код JavaScript, код передается в движок JavaScript, и мы переходим к нашему первому шагу, а именно к разбору кода. Парсер преобразует код в следующий:
- Токены : код сначала разбивается на «токены», такие как идентификатор, число, строка, оператор и т. д. Это известно как «лексический анализ» или «токенизация».
- Пример: var num = 42разбивается на var,num,=,42и каждый «токен» или элемент затем помечается своим типом, так что в этом случае это будет Keyword,Identifier,Operator,Number.
- Абстрактное синтаксическое дерево (AST) : после того, как код будет разобран на токены, синтаксический анализатор преобразует эти токены в AST. Эта часть называется «Синтаксический анализ», и она делает то, что говорит, проверяет, нет ли в коде синтаксических ошибок.
- Пример: Используя приведенный выше пример кода, AST для этого будет выглядеть так:
{
"type": "VariableDeclaration",
"start": 0,
"end": 13,
"declarations": [
{
"type": "VariableDeclarator",
"start": 4,
"end": 12,
"id": {
"type": "Identifier",
"start": 4,
"end": 7,
"name": "num"
},
"init": {
"type": "Literal",
"start": 10,
"end": 12,
"value": 42,
"raw": "42"
}
}
],
"kind": "var"
}
- Пример: Используя приведенный выше пример кода, AST для этого будет выглядеть так:
- Токены : код сначала разбивается на «токены», такие как идентификатор, число, строка, оператор и т. д. Это известно как «лексический анализ» или «токенизация».
- Интерпретатор : после создания AST он передается интерпретатору, который обрабатывает AST и генерирует байт-код. После того, как байт-код сгенерирован, он выполняется, а AST удаляется.
- Список байткодов для V8 можно найти здесь .
- Пример байт-кода для var num = 42;показано ниже:
LdaConstant [0]
Star1
Mov <closure>, r2
CallRuntime [DeclareGlobals], r1-r2
LdaSmi [42]
StaGlobal [1], [0]
LdaUndefined
Return
- Компилятор : компилятор работает заранее, используя что-то, называемое «Профилировщик», который отслеживает и следит за кодом, который должен быть оптимизирован. Если есть что-то, известное как «горячая функция», компилятор берет эту функцию и генерирует оптимизированный машинный код для выполнения. В противном случае, если он увидит, что «горячая функция», которая была оптимизирована, больше не используется, он «деоптимизирует» ее обратно в байт-код.
- Ignition : быстрый низкоуровневый интерпретатор V8 на основе регистров, генерирующий байт-код.
- SparkPlug : новый неоптимизирующий компилятор JavaScript V8, который компилирует из байт-кода, повторяя байт-код и выдавая машинный код для каждого байт-кода по мере его посещения.
- TurboFan : оптимизирующий компилятор V8, который переводит байт-код в машинный код с более многочисленными и более сложными оптимизациями кода. Он также включает компиляцию JIT (Just-In-Time).

До тех пор, если вы хотите узнать больше о конвейере, я предлагаю посмотреть « JavaScript Engines: The Good Parts », чтобы лучше понять.
Единственное, что вы должны понять из этого конвейера компиляции в настоящее время, это то, что интерпретатор — это « стековая машина » или, по сути, виртуальная машина (VM), где выполняется байт-код. С точки зрения Ignition (интерпретатор V8) интерпретатор на самом деле является «регистровой машиной» с регистром-аккумулятором. Ignition по-прежнему использует стек, но предпочитает хранить данные в регистрах, чтобы ускорить процесс.
Я предлагаю вам прочитать « Понимание байт-кода V8 » и « Запуск интерпретатора зажигания », чтобы лучше понять эти концепции.
JavaScript и внутреннее устройство V8
Теперь, когда у нас есть некоторые базовые знания о том, как устроен движок JavaScript и его конвейер компиляции, пришло время немного углубиться во внутренности самого JavaScript и посмотреть, как V8 хранит и представляет объекты JavaScript в памяти вместе с их значениями и свойствами. .Этот раздел является одной из самых важных частей, которую вам необходимо понять, если вы хотите использовать ошибки в V8, а также в других движках JavaScript. Потому что, как оказалось, все основные движки реализуют объектную модель JavaScript схожим образом.
Как мы знаем, JavaScript — это язык с динамической типизацией. Это означает, что информация о типе связана со значениями времени выполнения, а не с переменными времени компиляции, как в C++. Это означает, что свойства любого объекта в JavaScript могут быть легко изменены во время выполнения. JavaScript Система типов определяет такие типы данных, как Undefined, Null, Boolean, String, Symbol, Number и Object (включая массивы и функции).
Простыми словами, что это значит? Ну, обычно это означает, что объект или примитив, такой как varв JavaScript может изменять свой тип данных во время выполнения, в отличие от C++. Например, давайте установим новую переменную с именем itemв JavaScript и установите его в 42.
var item = 42;
Используя typeof в оператор itemпеременная, мы видим, что она возвращает свой тип данных, который будет Number.
typeof item
'number'
Теперь, что произойдет, если мы попытаемся установить itemв строку, а затем проверить ее тип данных?
item = "Hello!";
typeof item
'string'
Посмотрите на это, itemпеременная теперь установлена на тип данных Stringи не Number. Именно это делает JavaScript «динамичным» по своей природе. В отличие от C++, если мы попытаемся создать intили целочисленную переменную, а позже попытался установить ее в строку, это не удалось - вот так:
int item = 3;
item = "Hello!"; // error: invalid conversion from 'const char*' to 'int'
// ^~~~~~~~
Хотя это круто в JavaScript, для нас это создает проблему. V8 и Ignition написаны на C++, поэтому интерпретатору и компилятору необходимо выяснить, как JavaScript собирается использовать некоторые данные. Это очень важно для эффективной компиляции кода, особенно потому, что в C++ существуют различия в размерах памяти для таких типов данных, как intили же char.
Помимо эффективности, это также имеет решающее значение для безопасности, поскольку, если интерпретатор и компилятор «интерпретируют» код JavaScript неправильно и мы получаем объект словаря вместо объекта массива, у нас появляется уязвимость Type Confusion.
Так как же V8 хранит всю эту информацию для каждого значения времени выполнения и как движок остается эффективным?
Ну, в V8 это достигается за счет использования выделенного объекта информационного типа, называемого Map (не путать с Map Objects ), который иначе известен как « Скрытый класс ». Иногда вы можете услышать, что Карта называется « Формой », особенно в JavaScript-движке Mozilla SpiderMonkey. V8 также использует то, что называется сжатием указателя или тегированием указателя в памяти (которое мы обсудим позже в этом посте), чтобы уменьшить потребление памяти и позволяет V8 представлять любое значение в памяти как указатель на объект.
Но прежде чем мы слишком углубимся в то, как все это работает, нам сначала нужно понять, что такое объекты JavaScript и как они представлены в V8.
Представление объекта
В JavaScript объекты — это, по сути, набор свойств, которые хранятся в виде пар ключ-значение — по сути, это означает, что объекты ведут себя как словари. Объекты могут быть массивами, функциями, логическими значениями, регулярными выражениями и т. д.Каждый объект в JavaScript имеет связанные с ним свойства, которые можно просто объяснить как переменную, которая помогает определить характеристики объекта. Например, недавно созданный carобъект может иметь такие свойства, как make, model, а также yearкоторые помогают определить, что carобъект есть. Вы можете получить доступ к свойствам объекта либо с помощью простого оператора записи через точку, такого как objectName.propertyNameили через скобки, такие как objectName['propertyName'].
Кроме того, каждое свойство объектов сопоставляется с атрибутами свойств , которые используются для определения и объяснения состояния свойств объектов. Пример того, как эти атрибуты свойств выглядят в объекте JavaScript, можно увидеть ниже.
http://xssforum7mmh3n56inuf2h73hvhnzobi7h2ytb3gvklrfqm7ut3xdnyd.onion/attachments/46566/
Теперь, когда мы немного понимаем, что такое объект, следующим шагом будет понимание того, как этот объект структурирован в памяти и где он хранится.
Всякий раз, когда создается объект, V8 создает новый объект JSObject и выделяет для него память в куче. Значение объекта является указателем на JSObjectкоторый содержит в своей структуре следующее:
- Map : указатель на объект HiddenClass , в котором подробно описывается « форма » или структура объекта.
- Properties : указатель на объект, содержащий именованные свойства.
- Elements : указатель на объект, содержащий пронумерованные свойства.
- In-Object Property: указатели на именованные свойства, которые были определены при инициализации объекта.
Мы должны отметить одну вещь: хотя именованные свойства хранятся так же, как элементы массива, они не совпадают, когда речь идет о доступе к свойствам. В отличие от элементов, мы не можем просто использовать ключ, чтобы найти позицию именованных свойств в массиве свойств; нам нужны некоторые дополнительные метаданные. Как упоминалось ранее, V8 использует специальный объект, называемый HiddenClass или же Map это связано с JSObject. Там хранится вся информация об объектах JavaScript, что, в свою очередь, позволяет V8 быть «динамическим».
Итак, прежде чем мы углубимся в понимание структуры JSObject и его свойств, нам сначала нужно посмотреть и понять, как же этот HiddenClass работает в V8.
HiddenClass (Map) и Shape Transitions
Как обсуждалось ранее, мы знаем, что JavaScript — это язык с динамической типизацией. В частности, из-за этого в JavaScript нет понятия классов. В C++, если вы создаете класс или объект, вы не можете добавлять или удалять из него методы и свойства на лету, в отличие от JavaScript. В C++ и других объектно-ориентированных языках вы можете хранить свойства объекта с фиксированным смещением в памяти, потому что макет объекта для экземпляра данного класса никогда не изменится, но в JavaScript он может динамически изменяться во время выполнения. Чтобы бороться с этим, JavaScript использует так называемое «наследование на основе прототипа», где каждый объект имеет ссылку на объект-прототип или «форму», чьи свойства он включает.
Так как же V8 хранит макет объекта?
Вот тут HiddenClass или же Map вступают в игру. Скрытые классы работают аналогично макету фиксированных объектов, где значения свойств (или указатели на эти свойства) могут быть сохранены в определенной структуре памяти, а затем доступны с фиксированным смещением между каждым из них. Эти смещения генерируются Torque и могут быть найдены в /torque-generated/src/objects/*.tq.inc. Это в значительной степени служит идентификатором «формы» объекта, что, в свою очередь, позволяет V8 лучше оптимизировать код JavaScript и сократить время доступа к свойствам.
Как ранее было замечено в JSObjectВ приведенном выше примере map — это еще одна структура данных внутри объекта. Эта структура содержит следующую информацию:
- Динамический тип объекта, например String, JSArray, HeapNumber и т. д.
- Типы объектов в V8 перечислены в /src/objects/objects.h
- Размер объекта (внутриобъектные свойства и т. д.)
- Свойства объекта и где они хранятся
- Тип элементов массива
- Прототип или форма объекта (если есть)
Теперь, когда мы понимаем, как выглядит макет map, давайте объясним эту «форму», о которой мы постоянно говорим. Как известно, каждый вновь созданный JSObject будет иметь собственный скрытый класс, который содержит смещение памяти для каждого из его свойств. Вот интересная часть; если в любой момент свойство этого объекта будет создано, удалено или изменено динамически, то будет создан новый скрытый класс.Этот новый скрытый класс хранит информацию о существующих свойствах с включением смещения памяти для нового свойства. Теперь обратите внимание, что новый скрытый класс создается только при добавлении нового свойства, добавление свойства с индексом массива не создает новые скрытые классы.
Итак, как это выглядит на практике? Хорошо, давайте рассмотрим следующий код:
Код:
var obj1 = {};
obj1.x = 1;
obj1.y = 2;В начале мы создаем новый объект с именем obj1, который создается и хранится в куче V8. Поскольку это только что созданный объект, нам необходимо создать HiddenClass (очевидно), хотя для этого объекта еще не определены никакие свойства. HiddenClass также создается и хранится в куче V8. В целях нашего примера мы назовем этот HiddenClass «C0».
Как только будет достигнута следующая строка кода и obj1.x = 1 выполняется, V8 создаст второй HiddenClass с именем «C1», основанный на C0. C1 будет первым HiddenClass, описывающим расположение свойства where. x можно найти в памяти. Но вместо сохранения указателя на значение для x на самом деле он будет хранить смещение для x который будет со смещением 0.
Хорошо, я знаю, что в этот момент некоторые из вас могут спросить: «Почему смещение к свойству, а не к его значению»?
Ну, в V8 это оптимизационный трюк. Карты являются относительно дорогими объектами с точки зрения использования памяти. Если мы храним пары свойств ключ-значение в формате словаря в каждом вновь созданном JSObject тогда это вызовет много вычислительных накладных расходов, поскольку синтаксический анализ словарей выполняется медленно. Во-вторых, что произойдет, если новый объект, такой как obj2 создается с теми же свойствами, что и obj1 такие как xа также y? Несмотря на то, что значения могут быть разными, два объекта на самом деле имеют одни и те же именованные свойства в одном и том же порядке или, как мы бы назвали это, в одной и той же «форме». В этом случае было бы расточительно хранить одно и то же имя свойства в двух разных местах.
И это позволяет V8 быть быстрым, он оптимизирован таким образом, чтобы map была максимально распространена между объектами одинаковой формы. Поскольку имена свойств повторяются для всех объектов в одной и той же форме и поскольку они находятся в одном и том же порядке, может быть несколько объектов, указывающих на один единственный HiddenClass в памяти со смещением на свойства вместо указателей на значения. Это также упрощает сборку мусора, так как map — это распределение памяти. Чтобы лучше объяснить эту концепцию, давайте на мгновение отвлечемся от нашего примера выше и рассмотрим важные части HiddenClass. Две наиболее важные части HiddenClass, которые позволяют Map иметь свою «форму», — это DescriptorArray и третье битовое поле. Если вы вернетесь к приведенной выше структуре Map, то заметите, что третье битовое поле хранит количество свойств, а массив дескрипторов содержит информацию об именованных свойствах, например, само имя, позиция, в которой хранится значение (смещение). и атрибуты свойств.
Например, предположим, что мы создаем новый объект, такой как var obj {x: 1}. Свойство x будет храниться в свойствах In-Object или в хранилище свойств объекта JavaScript. Поскольку создается новый объект, также будет создан новый HiddenClass. Внутри этого HiddenClass будут заполнены массив дескрипторов и третье битовое поле. Третье битовое поле устанавливает numberOfOwnDescriptors в 1, так как у нас есть только одно свойство, а затем массив дескрипторов будет заполнять части ключа, сведений и значений массива сведениями, относящимися к свойству x. Значение этого дескриптора будет равно 0. Почему 0? Что ж, свойства In-Object и хранилище свойств — это просто массив. Итак, установив значение дескриптора на 0, V8 знает, что значение ключей будет по смещению 0 этого массива для любого объекта той же формы.
Наглядный пример того, что мы только что объяснили, можно увидеть ниже.
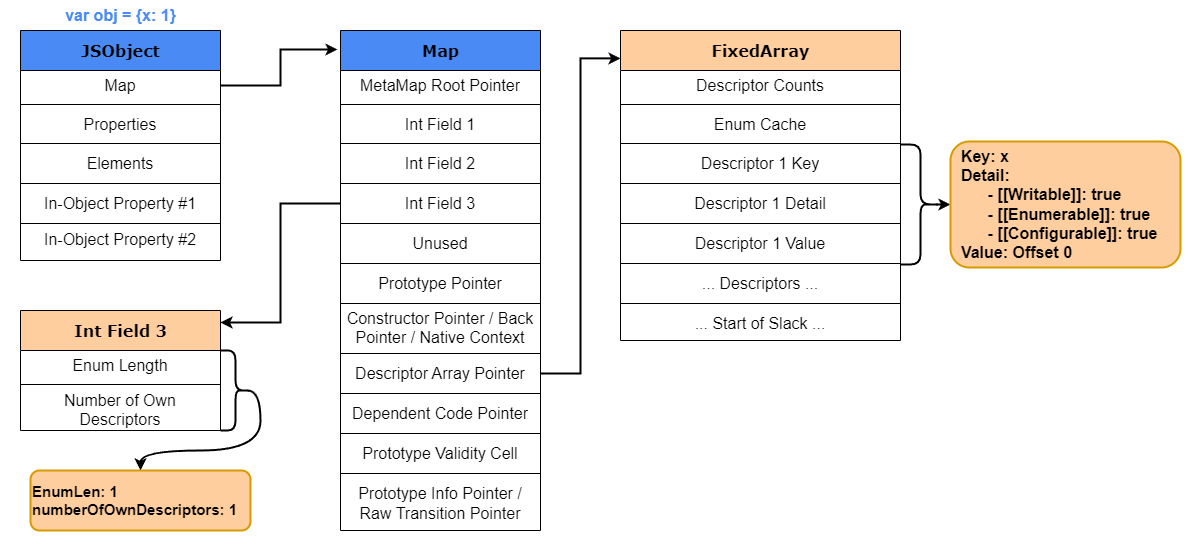
Давайте посмотрим, как это выглядит в V8. Для начала запустим d8с --allow-natives-syntax и выполните следующий код JavaScript:
Код:
d8> var obj1 = {a: 1, b: 2, c: 3}После завершения мы будем использовать %DebugPrint() для нашего объекта, чтобы отобразить его свойства, карту и другую информацию, такую как дескриптор экземпляра. После выполнения обратим внимание на:
Желтым цветом выделим наш объект obj1. Красным указатель на наш HiddenClass или Map. В этом HiddenClass у нас есть дескриптор экземпляра, который указывает на DescriptorArray. С использованием %DebugPrintPtr(), указателя на этот массив, мы можем увидеть более подробную информацию о том, как этот массив выглядит в памяти, которая выделена синим цветом .
Обратите внимание, у нас есть три свойства, что соответствует количеству дескрипторов в разделе дескрипторов экземпляров карты. Ниже мы видим, что массив дескрипторов содержит ключи наших свойств, а const data field содержит смещения связанных с ними значений в хранилище свойств. Теперь, если мы пойдем по стрелке назад от смещений к нашему объекту, мы заметим, что смещения действительно совпадают, и каждому свойству назначено правильное значение.
Кроме того, обратите внимание, что справа от этих свойств вы можете увидеть местоположение каждого из этих свойств; которые находятся в объекте , как я упоминал ранее. Это в значительной степени доказывает нам, что смещения относятся к свойствам в хранилище In-Object и Properties.
Хорошо, теперь, когда мы понимаем, почему мы используем смещения, давайте вернемся к нашему предыдущему примеру HiddenClass. Как мы уже говорили, добавив свойство x к obj1, теперь у нас будет только что созданный HiddenClass с именем «C1» со смещением на x. Поскольку мы создаем новый HiddenClass, V8 обновит C0 «переходом класса», в котором говорится, что если новый объект создается со свойством x, то скрытый класс должен переключиться прямо на C1.
Затем процесс повторяется, когда мы выполняем obj1.y = 2. Будет создан новый скрытый класс с именем C2, а в C1 добавлен переход класса, указывающий, что для любого объекта со свойством x, если свойство yдобавляется, то скрытый класс должен перейти на C2. В конце концов, все эти переходы классов создают нечто, известное как «дерево переходов».
Кроме того, следует отметить, что переходы классов зависят от порядка, в котором свойства добавляются к объекту. Таким образом, если бы z было добавлено после y, «форма» уже не была бы той же самой и следовала бы тому же пути перехода от C1 к C2. Вместо этого будет создан новый скрытый класс, и будет добавлен новый путь перехода из C1 для учета этого нового свойства, что еще больше расширит дерево переходов.
Теперь, когда мы это поняли, давайте посмотрим, как объекты выглядят в памяти, когда карта используется совместно двумя объектами одинаковой формы.
Для начала запустите d8 снова с --allow-natives-syntax параметр, а затем введите следующие две строки кода JavaScript:
Код:
d8> var obj1 = {x: 1, y: 2};
d8> var obj2 = {x: 2, y: 3};После завершения мы снова будем использовать %DebugPrint() для каждого из наших объектов, чтобы отобразить их свойства, map и другую информацию. После выполнения обратите внимание на следующее:
Желтым цветом оба наших объекта, obj1 а также obj2. Обратите внимание, что каждый является JS_OBJECT_TYPE с другим адресом памяти в куче, потому что очевидно, что это отдельные объекты с потенциально разными свойствами. Как мы знаем, оба этих объекта имеют одинаковую форму, поскольку они оба содержат x и y в одном и том же порядке. В этом случае в Blue мы видим, что свойства находятся в одном и том же FixedArray со смещением для x и y равным 0 и 1 соответственно. Причина этого в том, что, как мы уже знаем, объекты одинаковой формы совместно используют HiddenClass (представленный красным цветом ), который будет иметь один и тот же массив дескрипторов.
Как видите, большинство свойств объекта и адресов карты будут одинаковыми, и все потому, что оба этих объекта используют одну карту.
Теперь сосредоточимся на back_pointer это выделено зеленым цветом. Если вы вернетесь к нашему примеру перехода карты C0 в C2, вы заметите, что мы упомянули нечто, называемое «деревом перехода». Это дерево переходов создается V8 в фоновом режиме каждый раз, когда создается новый HiddenClass, и позволяет V8 связывать новый и старый HiddenClass вместе. Этот back_pointer является частью этого дерева переходов, поскольку указывает на родительскую карту, откуда произошел переход. Это позволяет V8 пройти по цепочке обратных указателей, пока не найдет карту, содержащую свойства объектов, то есть их форму.
Давайте использовать d8чтобы глубже понять, как это работает. Мы будем использовать %DebugPrintPtr() еще раз, чтобы распечатать детали указателя адреса в V8. В этом случае мы возьмем back_pointer, чтобы просмотреть его детали. После этого ваш вывод должен быть похож на:
Зеленым цветом выделено как back_pointer определяет JS_OBJECT_TYPE в памяти, которая на деле оказывается map! Эта map — та самая map C1, о которой мы говорили ранее. Мы знаем, как map может вернуться к своему предыдущему состоянию. Что ж, если мы внимательно посмотрим на информацию в этой карте, мы заметим, что под указателем дескриптора экземпляра есть раздел «переходы», выделенный красным цветом. Этот раздел перехода содержит информацию, на которую указывает необработанный указатель перехода в структуре карты.
В V8 переходы map используется TransitionsAccessor. Это вспомогательный класс, который инкапсулирует доступ к различным способам, которыми map может хранить переходы к другим map в соответствующем поле в Map::kTransitionsOrPrototypeInfo, известный как необработанный указатель перехода, о котором мы упоминали ранее. Этот указатель указывает на TransitionArray, который снова является FixedArray который содержит переходы map для изменения свойств.
Оглядываясь назад на выделенный красным цветом раздел, мы видим, что в этом массиве переходов есть только один. В этом массиве мы видим, что переход № 1 детализирует переход, когда свойство y добавляется к объекту. Если добавляется y, это говорит map обновить себя из map, хранящейся в 0x007f00259735 которая соответствует нашей текущей map. В случае, если был другой переход, например, z был добавлен к x вместо y, тогда у нас было бы два элемента в этом массиве переходов, каждый из которых указывал бы на соответствующую map для этой формы объектов.
ПРИМЕЧАНИЕ . Если вы хотите поиграть с map и получить другое визуальное представление переходов map я рекомендую использовать инструмент V8 Indicium . Инструменты представляют собой унифицированный веб-интерфейс, который позволяет отслеживать, отлаживать и анализировать закономерности создания и изменения map в реальных приложениях.
Что произойдет с деревом переходов, если мы удалим свойство? Ну, в этом случае есть нюанс в том, что V8 создает новую map каждый раз, когда происходит удаление свойства. Как мы знаем, map являются относительно дорогими, когда речь идет об использовании памяти, поэтому в определенный момент стоимость наследования и поддержки дерева переходов будет расти и медленнее. В случае удаления последнего свойства объекта map просто отрегулирует указатель назад, чтобы вернуться к предыдущей map вместо создания новой. Но что произойдет, если мы удалим среднее свойство объекта? Что ж, в этом случае V8 перестанет поддерживать дерево переходов всякий раз, когда мы добавляем слишком много атрибутов или удаляем не последние элементы, и переключается в более медленный режим, известный как режим словаря.
Итак, что же это за режим словаря? Что ж, теперь, когда мы знаем, как V8 использует HiddenClasses для отслеживания формы объектов, мы можем вернуться назад и углубиться в понимание того, как эти свойства и элементы на самом деле хранятся и обрабатываются в V8.
Характеристики
Как объяснялось ранее, мы знаем, что объекты JavaScript имеют два основных типа свойств: именованные свойства и индексированные элементы. Мы начнем с рассмотрения именованных свойств. Если вы помните наше обсуждение карт и массива дескрипторов, мы упоминали, что именованные свойства хранятся либо в объекте, либо в массиве свойств. Что это за свойство в объекте, о котором мы говорим?
Что ж, в V8 этот режим является очень быстрым методом сохранения свойств непосредственно в объекте, поскольку они доступны без каких-либо косвенных действий. Хотя они очень быстрые, они также ограничены начальным размером объекта. Если добавляется больше свойств, чем есть места в объекте, то новые свойства сохраняются в хранилище свойств, что добавляет один уровень косвенности.
В общем, есть два «режима», которые движки JavaScript используют для хранения свойств, и они называются:
- Быстрые свойства : обычно используется для определения свойств, хранящихся в хранилище линейных свойств. Эти свойства просто доступны по индексу в хранилище свойств, обращаясь к массиву массива дескрипторов в HiddenClass.
- Медленные свойства : также известный как «режим словаря», этот режим используется, когда добавляется или удаляется слишком много свойств, что приводит к большим накладным расходам памяти. В результате объект с медленными свойствами будет иметь автономный словарь в качестве хранилища свойств. Вся метаинформация о свойствах больше не хранится в массиве дескрипторов в HiddenClass, а хранится непосредственно в словаре свойств. Затем V8 будет использовать хеш-таблицу для доступа к этим свойствам.
Здесь также необходимо отметить одну вещь. Переходы формы работают только для быстрых свойств, а не для медленных свойств, поскольку формы словаря используются только одним объектом, поэтому они не могут быть разделены между разными объектами и, следовательно, не имеют переходов.
Элементы
Хорошо, на данный момент мы в значительной степени рассмотрели именованные свойства. Теперь давайте взглянем на свойства или элементы, индексированные в массиве. Можно было бы подумать, что обработка индексированных свойств будет менее сложной… но вы ошибаетесь, полагая это. Обработка элементов не менее сложна, чем именованные свойства. Несмотря на то, что все индексированные свойства хранятся в хранилище элементов, V8 делает очень точное различие в том, какие элементы содержит каждый массив. примерно 21 тип элементов На самом деле в этом магазине можно отслеживать! Это изначально позволяет V8 оптимизировать любые операции над массивом специально для этого типа элемента.
Что я имею в виду? Что ж, возьмем, к примеру, эту строку кода:
Код:
const array = [1,2,3];В JavaScript, если запустим typeof массив содержит numbers потому что JavaScript не различает целое число, число с плавающей запятой или двойное число. Однако V8 делает гораздо более точные различия и классифицирует этот массив как PACKED_SMI_ELEMENTS, где SMI относится к малым целым числам.
Так что там с SMI? Ну, V8 отслеживает, какие элементы содержит каждый массив. Затем он использует эту информацию для оптимизации операций с массивами для этого типа элементов. В V8 есть три различных типа элементов, о которых нам нужно знать, а именно:
- SMI_ELEMENTS- Используется для представления массива, содержащего небольшие целые числа, такие как 1,2,3 и т. д.
- DOUBLE_ELEMENTS- Используется для представления массива, содержащего числа с плавающей запятой, например 4,5, 5,5 и т. д.
- ELEMENTS- Используется для представления массива, содержащего элементы строкового литерала или значения, которые не могут быть представлены как SMI или Double, например "x".
Например, давайте возьмем наш пример с массивом из предыдущего:
Код:
const array = [1,2,3];
// Elements Kind: PACKED_SMI_ELEMENTSКак вы можете видеть, V8 отслеживает тип элементов этого массива как упакованный SMI (позже мы подробно расскажем, что такое упакованный). Теперь, если бы мы добавили число с плавающей запятой, то вид элементов массива «перешел бы» на вид элементов Double как таковой.
Код:
const array = [1,2,3];
// Elements Kind: PACKED_SMI_ELEMENTS
array.push(3.337)
// Elements Kind: PACKED_DOUBLE_ELEMENTSПричина этого перехода проста, оптимизация работы. Поскольку у нас есть целое число с плавающей запятой, V8 должен иметь возможность выполнять оптимизацию этих значений, чтобы переходить на один шаг вниз к DOUBLES потому что набор чисел, который может быть представлен в виде SMI это подмножество чисел, которые могут быть представлены как двойные. Поскольку переходы типов элементов идут в одну сторону, как только массив помечен более низким типом элементов, например PACKED_DOUBLES_ELEMENTS он больше не может вернуться «наверх» к PACKED_SMI_ELEMENTS, даже если мы заменим или удалим это целое число с плавающей запятой. Как правило, чем более специфичен тип элементов при создании массива, тем более точные оптимизации доступны. Чем дальше вы опускаетесь по типам элементов, тем медленнее могут быть манипуляции с этим объектом.
Далее нам также необходимо понять первое важное отличие, которое есть у V8, когда он отслеживает резервные хранилища элементов, когда индекс удален или пуст. И это:
- PACKED- Используется для представления массивов, которые являются плотными, что означает, что все доступные элементы в массиве были заполнены.
- HOLEY- Используется для представления массивов, в которых есть «дыры», например, когда индексированный элемент удален или не определен. Это также известно как создание «разреженного» массива.
Код:
const packed_array = [1,2,3,5.5,'x'];
// Elements Kind: PACKED_ELEMENTS
const holey_array = [1,2,,5,'x'];
// Elements Kind: HOLEY_ELEMENTSКак видите, holey_array имеет «дыры», так как мы забыли добавить 3 в индекс и просто оставил его пустым или неопределенным. Причина, по которой V8 делает это различие, заключается в том, что операции с упакованными массивами могут быть оптимизированы более агрессивно, чем операции с дырявыми массивами. Если вы хотите узнать об этом больше, я предлагаю вам посмотреть выступление Матиаса Байненса « Внутреннее устройство V8 для разработчиков JavaScript », в котором это очень подробно описано.
V8 также реализует ранее упомянутые переходы типов элементов на обоих PACKEDа также HOLEY массивы, образующие «решетку». Простую визуализацию этих переходов можно увидеть ниже.
Опять же, мы должны помнить, что виды элементов имеют односторонние нисходящие переходы через эту решетку. Например, добавление числа с плавающей запятой в массив SMI помечает его как двойное, и аналогичным образом, как только в массиве создается дыра, она навсегда помечается как дырявая, даже если вы ее заполните позже.
V8 также имеет второе важное различие, касающееся элементов, которые нам необходимо понять. В резервных хранилищах элементов, как и в хранилище свойств, элементы также могут быть либо быстрыми, либо в режиме словаря (медленными). Быстрые элементы — это просто массив, в котором индекс свойства соответствует смещению элемента в хранилище элементов. Что касается медленных массивов, то это происходит при наличии больших разреженных массивов, в которых занято всего несколько элементов. В этом случае резервное хранилище массива использует представление словаря, подобное тому, которое мы видели в хранилище свойств, для экономии памяти за счет снижения производительности. Этот словарь будет хранить атрибуты ключа, значения и элемента в значениях триплетов словаря.
Просмотр объектов Chrome в памяти
На данный момент мы рассмотрели множество сложных тем как по JavaScript, так и по внутреннему устройству V8. Надеюсь, к этому моменту у вас уже есть достаточное понимание некоторых концепций, благодаря которым V8 работает «под капотом». Теперь, когда у нас есть эти знания, пора перейти к наблюдению за тем, как V8 и его объекты выглядят в памяти при наблюдении через WinDBG и какие типы оптимизации используются.
Причина, по которой мы используем WinDBG, заключается в том, что когда мы будем писать эксплойты, отлаживать наш POC и т. д., мы в основном будем использовать WinDBG в сочетании с d8. В этом случае нам полезно иметь возможность уловить и понять нюансы структуры памяти V8. Если вы не знакомы с WinDBG, то я предлагаю вам прочитать и ознакомиться с сообщением в « Начало работы с WinDbg (режим пользователя) блоге » от Microsoft и прочитать « Команды GDB для пользователей WinDbg », если вы использовали GDB раньше.
Я знаю, что мы уже заглядывали в структуры памяти объектов и карт, и возились с d8 — так что у нас должно быть общее представление о том, что на что указывает и где вещи находятся в памяти. Но не обманывайтесь, что это будет так просто. Как и все в V8, оптимизация играет большую роль в том, чтобы сделать его быстрым и эффективным, это также относится к тому, как он обрабатывает и хранит значения в памяти.
Что я имею в виду? Что ж, давайте быстро рассмотрим простую структуру объектов V8 с использованием d8 и WinDBG. Для начала давайте снова инициируем
d8 с --allow-natives-syntaxoption и создайте простой объект, например:
Код:
d8> var obj = {x:1, y:2}После этого давайте продолжим и воспользуемся %DebugPrint() для вывода информации об объектах.
Код:
d8> var obj = {x:1, y:2};
d8> %DebugPrint(obj)
DebugPrint: 000002530010A509: [JS_OBJECT_TYPE]
- map: 0x025300259735 <Map[20](HOLEY_ELEMENTS)> [FastProperties]
- prototype: 0x025300244669 <Object map = 0000025300243D25>
- elements: 0x025300002259 <FixedArray[0]> [HOLEY_ELEMENTS]
- properties: 0x025300002259 <FixedArray[0]>
- All own properties (excluding elements): {
00000253000041ED: [String] in ReadOnlySpace: #x: 1 (const data field 0), location: in-object
00000253000041FD: [String] in ReadOnlySpace: #y: 2 (const data field 1), location: in-object
}
0000025300259735: [Map] in OldSpace
- type: JS_OBJECT_TYPE
- instance size: 20
- inobject properties: 2
- elements kind: HOLEY_ELEMENTS
- unused property fields: 0
- enum length: invalid
- stable_map
- back pointer: 0x0253002596ed <Map[20](HOLEY_ELEMENTS)>
- prototype_validity cell: 0x0253002043cd <Cell value= 1>
- instance descriptors (own) #2: 0x02530010a539 <DescriptorArray[2]>
- prototype: 0x025300244669 <Object map = 0000025300243D25>
- constructor: 0x02530024422d <JSFunction Object (sfi = 000002530021BA25)>
- dependent code: 0x0253000021e1 <Other heap object (WEAK_ARRAY_LIST_TYPE)>
- construction counter: 0После этого запустите WinDBG и подключите его к процессу d8. Как только отладчик подключится, мы выполним команду dq, за которой следует адрес памяти нашего объекта ( 0x0000020C0010A509) для отображения содержимого памяти. Ваш вывод должен быть очень похож на:
Глядя на вывод WinDBG, мы видим, что используем правильный адрес памяти для объекта. Но когда мы смотрим на содержимое памяти, первый адрес (который должен быть указателем на карту, если вы помните нашу структуру JSObject) кажется поврежденным. Что ж, можно было бы подумать, что он поврежден, более опытные реверс-инженеры или разработчики эксплойтов, возможно, даже подумали бы, что существует проблема смещения/выравнивания, и технически вы были бы близки, но не правы.
Опять же, друзья мои, оптимизация V8 работает. Вы можете понять, почему нам нужно обсудить эти оптимизации, потому что для неопытного глаза вы серьезно потеряетесь и запутаетесь в том, что происходит в памяти. На самом деле мы видим здесь две вещи: сжатие указателя и тегирование указателя.
Мы начнем с разбора Pointer или Value в V8.
Pointer Tagging
Итак, что такое тегирование указателей и почему мы его используем? Насколько нам известно, в V8 значения представлены как объекты и размещены в куче — независимо от того, являются ли они объектом, массивом, числом или строкой. Теперь многие программы JavaScript фактически выполняют вычисления над целыми значениями, поэтому, если бы нам постоянно приходилось создавать новый Number()объект в JavaScript каждый раз, когда мы увеличиваем или изменяем значение, это приводит к накладным расходам времени на создание объекта, отслеживание кучи и увеличивает используемое пространство памяти, что делает это очень неэффективным.
В этом случае, что будет делать V8, так это то, что вместо того, чтобы каждый раз создавать новый объект, он фактически будет хранить некоторые значения в строке. Хотя это работает, это создает для нас вторую проблему. И эта проблема заключается в том, как отличить указатель объекта от встроенного значения? Ну, вот где тегирование указателя вступает в игру.
Техника тегирования указателя основана на наблюдении, что в системах x32 и x64 выделенные данные должны быть выровнены по словам (4 байта). Поскольку данные выравниваются таким образом, младшие значащие биты (LSB) всегда будут равны нулю. Затем при тегировании будут использоваться два младших бита или младшие значащие биты, чтобы различать указатель объекта кучи и целое число или SMI.
В архитектуре x64 используется следующая схема тегов:
Код:
|----- 32 bits -----|----- 32 bits -------|
Pointer: |________________address______________(w1)|
Smi: |____int32_value____|000000000000000000(0)|Как видно из примера, 0 используется для представления SMI, а 1 — для представления указателя. Следует отметить только одну вещь: вы просматриваете SMI в памяти, хотя они хранятся в строке, они фактически удваиваются, чтобы избежать тега указателя. Итак, если исходное значение равно 1, в памяти будет 2.
В указателе у нас также есть w во втором LSB, который обозначает бит, который используется для различения сильной или слабой ссылки указателя. Если вы не знакомы с тем, что такое сильный и слабый указатель, я объясню. Просто сильный указатель — это указатель, который указывает, что объект, на который он указывает, должен оставаться в памяти (он представляет объект), а слабый указатель — это указатель, который просто указывает на данные, которые могли быть удалены. Когда GC или сборщик мусора удаляет объект, он должен удалить сильный указатель, поскольку он содержит счетчик ссылок.
С этой схемой тегирования указателя арифметические или бинарные операции с целыми числами могут игнорировать тег, поскольку младшие 32 бита будут равны нулю. Однако, когда дело доходит до разыменования HeapObject, V8 должен сначала маскировать младший значащий бит, для чего используется специальный метод доступа, который позаботится об очистке LSB. Теперь, зная это, давайте вернемся к нашему примеру в WinDBG и очистим этот LSB, вычитая 1 из адреса. Затем это должно предоставить нам действительные адреса памяти. После этого ваш вывод должен выглядеть так.
Как видите, как только мы очистили LSB, теперь у нас есть действительные адреса указателей в памяти! В частности, у нас есть карта, свойства, элементы, а затем наши встроенные объекты. Опять же, обратите внимание, что SMI удваиваются, поэтому x, который содержит 1, на самом деле равен 2 в памяти, и то же самое верно для 2, поскольку теперь он равен 4.
Те, у кого зоркий глаз, могли заметить, что только половина указателя на самом деле указывает на объект в памяти. Почему это? Если бы ваш ответ был «еще одна оптимизация», то вы были бы правы. Это то, что называется сжатием указателя, о котором мы сейчас поговорим.
Сжатие указателя
Сжатие указателей в Chrome и V8 использует интересное свойство объектов в куче, а именно то, что объекты кучи обычно расположены близко друг к другу, поэтому наиболее значимые биты указателя, вероятно, будут одинаковыми. В этом случае V8 сохраняет только половину указателя (младшие значащие биты) в памяти и помещает старшие значащие биты (старшие 32 бита) кучи V8 (известной как isolate root) в root register (R13). Всякий раз, когда нам нужно получить доступ к указателю, регистр и значение в памяти просто складываются вместе, и мы получаем наш полный адрес. Схема сжатия реализована в /src/common/ptr-compr-inl.h в V8.
По сути, цель, которую пыталась выполнить команда V8, заключалась в том, чтобы каким-то образом уместить оба типа теговых значений в 32-битные 64-битные архитектуры, в частности, чтобы уменьшить накладные расходы в V8, чтобы попытаться вернуть как можно больше потерянных 4 байтов в пределах х64 архитектура.