Здравствуй, мой любитель подводного плавания! В этой статье я продолжу заплыв в пространство имен переведя вторую часть сего произведения технической мысли. БУЛЬК!
Изоляция процессов — ключевой компонент контейнеров. Одним из ключевых базовых механизмов являются пространства имен . Сегодня мы рассмотрим пространства имен USER, MNT, UTS, IPC и CGROUP и, наконец, объединим все для создания полностью изолированной среды для процесса.
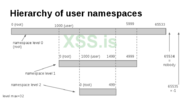
Все процессы в мире Linux имеют своего владельца. Есть привилегированные и непривилегированные процессы в зависимости от их уникального идентификатора пользователя (UID). Пространство имен пользователя — это функция ядра позволяющая виртуализировать этот UID для каждого процесса. В документации Linux пространство имен пользователя определяется следующим образом:
В основном это означает, что процесс имеет полные привилегии для операций внутри своего текущего пользовательского пространства имен, но непривилегирован за его пределами. Начиная с Linux 3.8 (и в отличие от флагов, используемых для создания других типы пространств имен), в некоторых дистрибутивах Linux привилегии не требуется для создания пользовательского пространства имен. Давайте попробуем!
В новом пользовательском пространстве имён наш процесс принадлежит nobody с UID=65334, которого нет в системе. Хорошо, но как ОС разрешает это, когда дело доходит до системных действий (изменение файлов, взаимодействие с программами)? В соответствии в документации Linux он предопределен в файле:
Если идентификатор пользователя не имеет сопоставления внутри пространства имен, то системные вызовы, которые возвращают идентификаторы пользователей вернут значение, определенное в файле /proc/sys/kernel/overflowuid, которое в стандартной системе по умолчанию используется значение 65534. Первоначально пользователь пространства имен не имеет сопоставления идентификаторов пользователей, поэтому все идентификаторы пользователей внутри пространства имен сопоставлены с этим значением.
Чтобы ответить на вторую часть вопроса - есть динамический идентификатор пользователя сопоставление, когда процесс должен выполнять общесистемные операции.
Из кода выше мы видим чтозаплыли за буйки фаил hello принадлежит пользователю, которого нет в системе. Давайте проверим владение этим файлом с точки зрения процесса в корне пространства имен USER.
Как видно из приведенного выше фрагмента кода, shell-процесс в пространствe имен пользователя root видит, что процесс внутри пространства имен USER имеет тот же UID. Это также объясняет, почему файл, созданный nobody рассматривается как принадлежащий nobody в новом пространстве имен USER, на самом деле принадлежит пользователю с ID=1000. Как уже упоминалось, пространства имен пользователей также может быть вложенным - процесс может иметь родительское пространство имен пользователя (кроме процессf в пространстве имен корневого пользователя) и ноль или более дочерних пользователей пространства имен. Теперь посмотрим, как процесс видит файловую систему, право собственности на содержимое которой определено в пространстве имен пользователя root.
Хорошо, хотя странно - содержимое корневого каталога, видимое из нового пространства имен пользователя, принадлежит пользователю, владеющему процессом в пространстве имен USER, но процесс не может изменить содержимое каталога? В новом пространстве имен пользователя (root), которому принадлежат эти файлы, не переназначем, поэтому он не существует. Поэтому процесс видит nobody и nogroup. Но когда он пытается изменить содержимое каталога, он делает это, используя свой UID в пространстве имен пользователя root, который отличается от UID файлов. Хорошо, но как процесс может взаимодействовать с файловой системой в этом случае? Нам придется использовать сопостовления.
Некоторые процессы должны работать под UID 0, чтобы обеспечить свои службы и иметь возможность взаимодействовать с файловой системой ОС. Одно из наиболее распространенных приемов при использовании пользовательских пространств имен — это сопоставление. Это делается с помощью /proc/<PID>/uid_map и /proc/<PID>/gid_map. Формат следующий:
ID-inside-ns (соответственно ID-outside-ns) определяет начальную точку UID сопоставления внутри пространства имен пользователя (соответственно вне пространства имен пользователя) а длина определяет количество последующих отображений UID (соответственно GID). Сопоставления применяются, когда процесс в пространстве имен USER пытается управлять системными ресурсами, принадлежащими другому пространству имен USER.
Некоторые важные правила согласно документации Linux:
Процесс внутри пространства имен пользователя считает, что его эффективный UID — root но в корневом пространстве имен его UID совпадает с процессом который его создал (UID=1000).

А общий вид переназначения таков:

Еще одна важная вещь, которую следует отметить, это то, что в определенном пространстве имен USER процесс имеет эффективный UID=0 и все возможности, установленные в разрешенный набор. Давайте посмотрим, каково представление файловой системы для процесса внутри переназначеного пространства имен пользователей.
Как видно, переназначенный пользователь воспринимает право собственности на файлы относительно текущего сопоставления пространства имен пользователя. Так как файл принадлежит UID=1000, который сопоставляется с UID=0 (root), процесс видит файл, принадлежащий пользователю root в текущем пространстве имен.
Хорошо, мы видим, что переназначенный shell - процесс воспринимает пользователя переназначение на основе собственного пользовательского пространства имен. Результаты могут интерпретируется следующим образом: UID=0 в пространстве имен пользователя для процесса 6638 соответствует UID=200 в текущем пространстве имен. Это все относительно! Согласно документации Linux:
Как мы видим, процесс внутри нового пространства имён имеет полный набор разрешенных и эффективных возможностей в пределах имени пользователя, даже хотя программа запускалась от непривилегированного пользователя. Однако в родительском пространствео имен пользователя, у него нет никаких возможностей. Это потому что каждый раз, когда создается новое пространство имен пользователя, первый процесс получает все возможности для правильной инициализации пространства имен, прежде чем в нем будут созданы какие-либо другие процессы. Это действительно важно для последней главы этой статьи, когда мы собирается объединить почти все пространства имен, чтобы изолировать данный процесс.
Пространства имен Linux дают возможность копировать эту структуру данных и передавать копию различным процессам. Таким образом, эти процессы могут изменять эту структуру (монтировать и размонтировать), не затрагивая точки монтирования друг друга. Предоставляя различные копии структуры файловой системы, ядро изолирует список точек монтирования, видимые процессам в пространстве имен. Определение пространства имен монтирования также может позволить процессу изменить свой корень - поведение, аналогичное системному вызову chroot. Разница в том, что chroot привязан к текущей структуре файловой системы, и все изменения (монтирование, размонтирование) в среде с повторным корнем будут затрагивать всю файловую систему. С пространствами имен mount это невозможно, так как вся структура виртуализируется, что обеспечивает полную изоляцию исходной файловой системы в плане событий монтирования и размонтирования.

Давайте попробуемзанырнуть на самое дно создать что то подообное!
Из фрагмента видно, что процессы в изолированном пространстве имен монтирования могут создавать различные точки монтирования и файлы под ними без отражения родительского пространства имен монтирования.
Общие поддеревья
Монтирование и размонтирование каталогов отражает файловую систему ОС. В классической ОС Linux эта система представлена в виде дерева. Как показано на рисунке выше, создание различных пространств имен монтирования технически приводит к созданию виртуальных структур дерева для каждого процесса. Эти структуры могут быть общими. Согласно документации Linux:
Ключевым преимуществом разделяемых поддеревьев является возможность автоматического, контролируемого распространения событий монтирования и размонтирования между пространствами имен. Это означает, например, что монтирование оптического диска в одном пространстве имен монтирования может вызвать монтирование этого диска во всех других пространствах имен.
Общие деревья состоят в основном из маркировки каждой точки монтирования тегом, говорящим о том, что произойдет, если мы добавим/удалим точки монтирования, которые присутствуют в разных пространствах имен монтирования. Добавление/удаление точек монтирования вызывает событие, которое распространяется в так называемых пиринговых группах. Пиринговая группа - это набор vfsmounts (точек монтирования виртуальных файловых систем), которые передают друг другу события монтирования и размонтирования.
Существует 4 типа монтирования:
MS_SHARED: Эта точка монтирования обменивается событиями монтирования и размонтирования с другими точками монтирования, которые являются членами ее "одноранговой группы". Когда под этой точкой монтирования добавляется или удаляется точка монтирования, это изменение распространяется на группу аналогов, так что монтирование или размонтирование также произойдет под каждой из точек монтирования аналогов. Распространение также происходит в обратном направлении, так что события монтирования и размонтирования в одноранговой точке монтирования также будут распространяться на эту точку монтирования.
MS_PRIVATE: Это обратная ситуация по сравнению с общей точкой монтирования. Точка монтирования не распространяет события ни для каких аналогов и не получает события распространения ни от каких аналогов.
MS_SLAVE: Этот тип распространения находится посередине между MS_SHARED и MS_PRIVATE. У MS_SLAVEедомого монтирования есть master - общая группа , члены которой распространяют события монтирования и размонтирования на ms_slave монтирование. Однако ms_slave монтирование не передает события ведущей peer - группе.
MS_UNBINDABLE - не получает и не передает никаких событий монтирования и не может быть смотрирован.
Состояние точки монтирования определяется для каждой точки монтирования. Это означает, что если у вас есть, например, / и /boot, вам придется отдельно применить нужное состояние к каждой точке монтирования.
Информация о различных типах монтажа в текущем процессе пространство имен можно найти в /proc/self/mountinfo.
Пространство имен UTS изолирует имя хоста системы для данного процесса.
Большинство коммуникаций с хостом и обратно осуществляется через IP-адрес и порт. Однако, намного проще жить, когда у нас есть какое-то имя, привязанное к процессу. Например, поиск в файлах журналов значительно упрощается при определении имени хоста. Но помни, что в динамичной среде IP-адреса могут меняться. По аналогии с названиями жилый кварталов. Сказать водителю такси, что я живу в апартаментах City Place, обычно более результативно, чем назвать фактический адрес. Наличие нескольких имен хостов на одном физическом узле является большим подспорьем в больших контейнерных средах. Поэтому пространство имен UTS обеспечивает разделение имен хостов для процессов. Таким образом, проще общаться со службами в частной сети и проверять их журналы на хосте.
Пространство имен IPC
Пространство имен IPC обеспечивает изоляцию для механизмов взаимодействия процессов, таких как семафоры, очереди сообщений, сегменты общей памяти и т.д. Обычно при fork() процесса он наследует все IPC, которые были открыты его родителем. Процессы внутри пространства имен IPC не могут видеть или взаимодействовать с ресурсами IPC верхнего пространства имен. Вот краткий пример использования сегментов общей памяти.
Пространство имен CGROUP
Cgroups - это технология, которая контролирует количество аппаратных ресурсов (RAM, HDD, I/O), потребляемых процессом.
По умолчанию CGroups создаются в виртуальной файловой системе /sys/fs/cgroup. Создание другого пространства имен CGroup, по сути, перемещает корневой каталог CGroup. Если CGroup была, например, /sys/fs/cgroup/mycgroup, новое пространство имен CGroup может использовать ее в качестве корневого каталога. Хост может видеть /sys/fs/cgroup/mycgroup/{group1,group2,group3}, но создание нового пространства имен CGroup будет означать, что новое пространство имен будет видеть только {group1,group2,group3}. Таким образом, пространства имен Cgroup виртуализируют другую виртуальную файловую систему в качестве пространства имен PID. Но какова цель обеспечения изоляции для этой системы? Согласно man-странице:
"Она предотвращает утечку информации, при которой пути каталогов cgroup за пределами контейнера иначе были бы видны процессам в контейнере. Такие утечки могли бы, например, раскрыть информацию о контейнерном фреймворке для приложений с контейнером."
В традиционной иерархии CGroup существует вероятность того, что вложенная CGroup может получить доступ к своему предку. Это означает, что процесс в /sys/fs/cgroup/mycgroup/group1 имеет возможность читать и/или манипулировать всем, что вложено в mycgroup.
А теперь всплываем!
Давайте используем все, что мы обсудили, чтобы построить полностью изолированную среду для заданного процесса, шаг за шагом, используя unshare! POC этой статьи, написанный на C и использующий системный вызов clone(), также доступен тутЪ.
Хорошо, теперь у нас есть каталог, содержимое которого такое же, как у классического root-каталога Linux.
Важно отметить порядок создания пространства имен, процедур обертывания, некоторые операции (такие как PID, UTC, пространство имен IPC создание) нуждаются в расширенных привилегиях в текущем пространстве имен.
Следующий алгоритм иллюстрирует его:
1. Создайте пространство имен USER
2. Переназначить UID процесса в новом пространстве имен USER.
3. Создайте пространство имен UTC
4. Измените имя хоста в новом пространстве имен UTC.
5. Создайте пространства имен IPC/CGROUP.
6. Создайте пространство имен NET
7. Создайте и настройте veth-пару
9. Создайте пространство имен PID
10. Создайте пространство имен MNT
11. Изменение root-процесса
12. Смонтируйте /proc внутрь под новым корнем
13. Размонтировать старый корень
14. Поместите процесс в новый корневой каталог.
Пользователь в пользовательском пространстве имен не может создавать новые пространства имен, поскольку он не иметь еUID=0. Чтобы исправить это, мы должны предоставить привилегии root с помощью процедуры переназначения. Как упоминалось выше, это переназначение должно выполняться из процесса в непосредственном верхнем пользовательском пространстве имен. Однако для из соображений безопасности, мы переназначим его непривилегированному пользователю за пределами пространство имен (eUID=0 -> eUID!=0).
Теперь мы можем продолжить создание пространств имен IPC и UTS!
Далее мы собираемся создать сетевое пространство имен, используя виртуальный интерфейсы.
Давайте теперь создадим отдельный PID и смонтируем пространства имен и отсоединим корень файловой системы.
Теперь полностью изолируем процесс внутри текущего каталога.
Мы изолировали процесс, используя почти все пространства имен. Другими словами мы сделали действительно примитивный контейнер (для тех, кто знаком с этим). НО, нет ограничений на использование аппаратных ресурсов, которое накладываются по контрольным группам.
Изоляция процессов — ключевой компонент контейнеров. Одним из ключевых базовых механизмов являются пространства имен . Сегодня мы рассмотрим пространства имен USER, MNT, UTS, IPC и CGROUP и, наконец, объединим все для создания полностью изолированной среды для процесса.
пространство имен USER
Все процессы в мире Linux имеют своего владельца. Есть привилегированные и непривилегированные процессы в зависимости от их уникального идентификатора пользователя (UID). Пространство имен пользователя — это функция ядра позволяющая виртуализировать этот UID для каждого процесса. В документации Linux пространство имен пользователя определяется следующим образом:
Пространства имен пользователей изолируют идентификаторы и атрибуты, связанные с безопасностью, в в частности, идентификаторы пользователей и идентификаторы групп, корневой каталог, ключи и возможности. Идентификаторы пользователя и группы процесса могут различаться внутри и вне пространства имен пользователя. В частности, процесс может иметь нормальный непривилегированный идентификатор пользователя вне пространства имен пользователя, в то же время с идентификатором пользователя 0 внутри пространства имен.
В основном это означает, что процесс имеет полные привилегии для операций внутри своего текущего пользовательского пространства имен, но непривилегирован за его пределами. Начиная с Linux 3.8 (и в отличие от флагов, используемых для создания других типы пространств имен), в некоторых дистрибутивах Linux привилегии не требуется для создания пользовательского пространства имен. Давайте попробуем!
Код:
cryptonite@cryptonite:~ $uname -a
Linux qb 5.11.0-25-generic #27~20.04.1-Ubuntu SMP Tue Jul 13 17:41:23 UTC 2021 x86_64 x86_64 x86_64 GNU/Linux
# root user namespace
cryptonite@cryptonite:~ $id
uid=1000(cryptonite) gid=1000(cryptonite) groups=1000(cryptonite) ...
cryptonite@cryptonite:~ $unshare -U /bin/bash
nobody@cryptonite:~$ id
uid=65534(nobody) gid=65534(nogroup) groups=65534(nogroup)В новом пользовательском пространстве имён наш процесс принадлежит nobody с UID=65334, которого нет в системе. Хорошо, но как ОС разрешает это, когда дело доходит до системных действий (изменение файлов, взаимодействие с программами)? В соответствии в документации Linux он предопределен в файле:
Если идентификатор пользователя не имеет сопоставления внутри пространства имен, то системные вызовы, которые возвращают идентификаторы пользователей вернут значение, определенное в файле /proc/sys/kernel/overflowuid, которое в стандартной системе по умолчанию используется значение 65534. Первоначально пользователь пространства имен не имеет сопоставления идентификаторов пользователей, поэтому все идентификаторы пользователей внутри пространства имен сопоставлены с этим значением.
Чтобы ответить на вторую часть вопроса - есть динамический идентификатор пользователя сопоставление, когда процесс должен выполнять общесистемные операции.
Код:
#inside the USER namespace we create a file
nobody@cryptonite:~$ touch hello
nobody@cryptonite:~ $ls -l hello
-rw-rw-r-- 1 nobody nogroup 0 Jun 29 17:06 helloИз кода выше мы видим что
Код:
cryptonite@cryptonite:~ $ls -al hello
-rw-rw-r-- 1 cryptonite cryptonite 0 Jun 29 17:09 hello
# under what UID runs the process who has created this file?
cryptonite@cryptonite:~ $ps l | grep /bin/bash
F S UID PID PPID C PRI NI ADDR SZ WCHAN TTY TIME CMD
0 1000 18609 3135 20 0 19648 5268 poll_s S+ pts/0 0:00 /bin/bashКак видно из приведенного выше фрагмента кода, shell-процесс в пространствe имен пользователя root видит, что процесс внутри пространства имен USER имеет тот же UID. Это также объясняет, почему файл, созданный nobody рассматривается как принадлежащий nobody в новом пространстве имен USER, на самом деле принадлежит пользователю с ID=1000. Как уже упоминалось, пространства имен пользователей также может быть вложенным - процесс может иметь родительское пространство имен пользователя (кроме процессf в пространстве имен корневого пользователя) и ноль или более дочерних пользователей пространства имен. Теперь посмотрим, как процесс видит файловую систему, право собственности на содержимое которой определено в пространстве имен пользователя root.
Код:
cryptonite@cryptonite:~ $unshare -U /bin/bash
nobody@cryptonite:/$ ls -al
drwxr-xr-x 20 nobody nogroup 4096 Jun 12 17:25 .
drwxr-xr-x 20 nobody nogroup 4096 Jun 12 17:25 ..
lrwxrwxrwx 1 nobody nogroup 7 Jun 12 17:21 bin -> usr/bin
drwxr-xr-x 5 nobody nogroup 4096 Jun 25 10:23 boot
...
nobody@cryptonite:~$ id
uid=65534(nobody) gid=65534(nogroup) groups=65534(nogroup)
nobody@cryptonite:~$ touch /heloo.txt
touch: cannot touch '/heloo.txt': Permission deniedХорошо, хотя странно - содержимое корневого каталога, видимое из нового пространства имен пользователя, принадлежит пользователю, владеющему процессом в пространстве имен USER, но процесс не может изменить содержимое каталога? В новом пространстве имен пользователя (root), которому принадлежат эти файлы, не переназначем, поэтому он не существует. Поэтому процесс видит nobody и nogroup. Но когда он пытается изменить содержимое каталога, он делает это, используя свой UID в пространстве имен пользователя root, который отличается от UID файлов. Хорошо, но как процесс может взаимодействовать с файловой системой в этом случае? Нам придется использовать сопостовления.
Сопоставление UID и GID
Некоторые процессы должны работать под UID 0, чтобы обеспечить свои службы и иметь возможность взаимодействовать с файловой системой ОС. Одно из наиболее распространенных приемов при использовании пользовательских пространств имен — это сопоставление. Это делается с помощью /proc/<PID>/uid_map и /proc/<PID>/gid_map. Формат следующий:
ID-inside-ns ID-outside-ns length
ID-inside-ns (соответственно ID-outside-ns) определяет начальную точку UID сопоставления внутри пространства имен пользователя (соответственно вне пространства имен пользователя) а длина определяет количество последующих отображений UID (соответственно GID). Сопоставления применяются, когда процесс в пространстве имен USER пытается управлять системными ресурсами, принадлежащими другому пространству имен USER.
Некоторые важные правила согласно документации Linux:
Если два процесса находятся в одном и том же пространстве имен, то интерпретируется ID-outside-ns как идентификатор пользователя (идентификатор группы) в пространстве имен родительского пользователя PID процесса. Обычным случаем здесь является то, что процесс записывает в свое собственное отображение файл (/proc/self/uid_map или /proc/self/gid_map).
Если два процесса находятся в разных пространствах имен, то ID-outside-ns интерпретируется как пользователь ID (идентификатор группы) в пользовательском пространстве имён открытия процесса /proc/PID/uid_map (/proc/PID/gid_map). Затем идет процесс написания определение сопоставления относительно своего собственного пользовательского пространства имен.
Код:
# adding a mapping for a shell process with PID=18609 in a user namespace
cryptonite@cryptonite:~ $echo "0 1000 65335" | sudo tee /proc/18609/uid_map
0 1000 65335
cryptonite@cryptonite:~ $echo "0 1000 65335" | sudo tee /proc/18609/gid_map
0 1000 65335
# back to the user namespaced shell
nobody@cryptonite:~$ id
uid=0(root) gid=0(root) groups=0(root)
# create a file
nobody@cryptonite:~$ touch hello
# back to the root namespace
cryptonite@cryptonite:~ $ls -l hello
-rw-rw-r-- 1 cryptonite cryptonite 0 Jun 29 17:50 helloПроцесс внутри пространства имен пользователя считает, что его эффективный UID — root но в корневом пространстве имен его UID совпадает с процессом который его создал (UID=1000).
А общий вид переназначения таков:
Еще одна важная вещь, которую следует отметить, это то, что в определенном пространстве имен USER процесс имеет эффективный UID=0 и все возможности, установленные в разрешенный набор. Давайте посмотрим, каково представление файловой системы для процесса внутри переназначеного пространства имен пользователей.
Код:
# in the root user namespace
cryptonite@cryptonite:~ $ls -l
total 0
-rw-rw-r-- 1 cryptonite cryptonite 0 Jul 2 11:07 hello
# in the sub user namespace
nobody@cryptonite:~/test$ ls -l
-rw-rw-r-- 1 root root 0 Jul 2 11:07 helloКак видно, переназначенный пользователь воспринимает право собственности на файлы относительно текущего сопоставления пространства имен пользователя. Так как файл принадлежит UID=1000, который сопоставляется с UID=0 (root), процесс видит файл, принадлежащий пользователю root в текущем пространстве имен.
Проверим текущие сопоставления процесса
Файлы /proc/<PID>/uid_map и /proc/<PID>/ gid_map также могут использоваться для проверки отображения данного процесса. Этот проверка относится к пользовательскому пространству имен, в котором находится процесс. Там два правила:- Если процесс в том же пространстве имен проверяет сопоставление другого процесса в том же пространстве имен, он увидит сопоставление с родительским пространством имен пользователя.
- Если процесс из другого пространства имен проверяет сопоставление процесса, он увидит сопоставление относительно своего собственного сопоставления.
Код:
# in shell number 1
cryptonite@cryptonite:~ $unshare -U /bin/bash
nobody@cryptonite:~$
# in shell number 2 define the user remapping
cryptonite@cryptonite:~ $echo "0 1000 65335" | sudo tee /proc/6638/uid_map
0 1000 65335
# perception from inside the remapped namespace
nobody@cryptonite:~ $cat /proc/self/uid_map
0 1000 65335
nobody@cryptonite:~ $id
uid=0(root) gid=65534(nogroup) groups=65534(nogroup)
# now in a 3rd shell we create a new user namespace
cryptonite@cryptonite:~ $unshare -U /bin/sh
$
# in the 2nd shell we define a new mapping of the sh shell
cryptonite@cryptonite:~ $echo "200 1000 65335" | sudo tee /proc/7061/uid_map
# back to the sh shell
# perception of the own remapping
$ cat /proc/self/uid_map
200 1000 65335
# perception of the bash shell remapping
$ cat /proc/6638/uid_map
0 200 65335Хорошо, мы видим, что переназначенный shell - процесс воспринимает пользователя переназначение на основе собственного пользовательского пространства имен. Результаты могут интерпретируется следующим образом: UID=0 в пространстве имен пользователя для процесса 6638 соответствует UID=200 в текущем пространстве имен. Это все относительно! Согласно документации Linux:
Есть несколько важных правил определения переназначения.Если процесс, открывающий файл, находится в том же пользовательском пространстве имен, что и PID процесса, то ID-outside-ns определяется относительно родительского пользовательского пространства имен. Если процесс, открывающий файл, находится в другом пространстве имен, ID-outside-ns определяет относительно пользовательского пространства имен процесс открытия файла.
Определение сопоставления — это одноразовая операция для каждого пространства имен: мы можем выполнять только одну запись (которая может содержать несколько записей, разделенных новой строкой) в файл uid_map ровно одного из процессов в пользовательском пространстве имен. Кроме того, количество строк которые могут быть записаны в файл, в настоящее время ограничено пятью.
Файл /proc/PID/uid_map принадлежит ID пользователя, который создал пространство имен и доступен для записи только этому пользователю (или более привилегированному пользователю). Кроме того, должны быть соблюдены все следующие требования: процесс записи должен иметь CAP_SETUID (CAP_SETGID для gid_map) возможность в пользовательском пространстве имен процесса PID - не смотря на это, процесс записи должен быть либо в пользовательском пространство имен процесса PID или внутри (непосредственного) родительского пользователя пространство имен PID процесса.
Пространство имен и возможности пользователя
Как мы упоминали ранее, первый процесс внутри нового пользовательского пространства имен имеет полный набор возможностей внутри текущего пользовательского пространства имен . Согласно документации Linux:Таким образом, возможности процесса инициализируются и интерпретируются относительно пространства имен пользователя. Давайте посмотрим, как обстоят дела, используя эту программу, которая порождает новый процесс внутри пользовательского пространства имен и показывает его возможности с точки зрения родительского пользовательского пространства имен и дочернее пространство имен.Когда пространство имен пользователя создается, первому процессу в пространстве имен предоставляется полный набор возможностей в пространстве имен. Это позволяет этому процессу выполнять любые инициализации, которые необходимы в пространстве имен перед другими процессами создаваемыми в пространстве имен. Хотя новый процесс имеет полный набор возможностей в новом пользовательском пространстве имён, он ничего не может в родительском пространстве имен. Это верно независимо от учетных данных и возможности процесса, вызывающего clone(). В в частности, даже если root использует CLONE_NEWUSER, результирующий дочерний процесс не будет иметь возможностей в родительском пространстве имен.
Код:
cryptonite@cryptonite:~ $ ./main
Capabilities of child process viewed from parent namespace =
Capabilities of child process viewed from child namespace =ep
Namespaced process eUID = 65534; eGID = 65534;Как мы видим, процесс внутри нового пространства имён имеет полный набор разрешенных и эффективных возможностей в пределах имени пользователя, даже хотя программа запускалась от непривилегированного пользователя. Однако в родительском пространствео имен пользователя, у него нет никаких возможностей. Это потому что каждый раз, когда создается новое пространство имен пользователя, первый процесс получает все возможности для правильной инициализации пространства имен, прежде чем в нем будут созданы какие-либо другие процессы. Это действительно важно для последней главы этой статьи, когда мы собирается объединить почти все пространства имен, чтобы изолировать данный процесс.
Пространство имен MNT
Пространства имен Mount (MNT) - это мощный инструмент для создания деревьев файловых систем для каждого процесса, а значит, и предоставлений корневой файловой системы для каждого процесса. Linux поддерживает структуру данных для всех различных файловых систем, смонтированных в системе. Эта структура является атрибутом каждого процесса, а также пространства имен. Она включает информацию о том, какие разделы диска смонтированы, куда они смонтированы и тип монтирования (RO/RW).
Код:
cryptonite@cryptonite:~ $ cat /proc/$$/mounts
sysfs /sys sysfs rw,nosuid,nodev,noexec,relatime 0 0
proc /proc proc rw,nosuid,nodev,noexec,relatime 0 0
...Пространства имен Linux дают возможность копировать эту структуру данных и передавать копию различным процессам. Таким образом, эти процессы могут изменять эту структуру (монтировать и размонтировать), не затрагивая точки монтирования друг друга. Предоставляя различные копии структуры файловой системы, ядро изолирует список точек монтирования, видимые процессам в пространстве имен. Определение пространства имен монтирования также может позволить процессу изменить свой корень - поведение, аналогичное системному вызову chroot. Разница в том, что chroot привязан к текущей структуре файловой системы, и все изменения (монтирование, размонтирование) в среде с повторным корнем будут затрагивать всю файловую систему. С пространствами имен mount это невозможно, так как вся структура виртуализируется, что обеспечивает полную изоляцию исходной файловой системы в плане событий монтирования и размонтирования.
Код:
# find the ID of the namespace of the current shell process
cryptonite@cryptonite:~ $readlink /proc/$$/ns/mnt
mnt:[4026531840]Давайте попробуем
Код:
# create and enter a new mount namespace
cryptonite@cryptonite:~ $sudo unshare -m /bin/bash
root@cryptonite:/home/cryptonite# mount -t tmpfs tmpfs /mnt
root@cryptonite:/home/cryptonite# touch /mnt/hello
# in a second terminal <=> in a separate mount namespace
cryptonite@cryptonite:~ $ls -al /mnt
total 8
drwxr-xr-x 2 root root 4096 Feb 9 19:47 .
drwxr-xr-x 20 root root 4096 Jun 8 23:24 .
# changes didn't reflect the other mount namespaceИз фрагмента видно, что процессы в изолированном пространстве имен монтирования могут создавать различные точки монтирования и файлы под ними без отражения родительского пространства имен монтирования.
Общие поддеревья
Монтирование и размонтирование каталогов отражает файловую систему ОС. В классической ОС Linux эта система представлена в виде дерева. Как показано на рисунке выше, создание различных пространств имен монтирования технически приводит к созданию виртуальных структур дерева для каждого процесса. Эти структуры могут быть общими. Согласно документации Linux:
Ключевым преимуществом разделяемых поддеревьев является возможность автоматического, контролируемого распространения событий монтирования и размонтирования между пространствами имен. Это означает, например, что монтирование оптического диска в одном пространстве имен монтирования может вызвать монтирование этого диска во всех других пространствах имен.
Общие деревья состоят в основном из маркировки каждой точки монтирования тегом, говорящим о том, что произойдет, если мы добавим/удалим точки монтирования, которые присутствуют в разных пространствах имен монтирования. Добавление/удаление точек монтирования вызывает событие, которое распространяется в так называемых пиринговых группах. Пиринговая группа - это набор vfsmounts (точек монтирования виртуальных файловых систем), которые передают друг другу события монтирования и размонтирования.
Существует 4 типа монтирования:
MS_SHARED: Эта точка монтирования обменивается событиями монтирования и размонтирования с другими точками монтирования, которые являются членами ее "одноранговой группы". Когда под этой точкой монтирования добавляется или удаляется точка монтирования, это изменение распространяется на группу аналогов, так что монтирование или размонтирование также произойдет под каждой из точек монтирования аналогов. Распространение также происходит в обратном направлении, так что события монтирования и размонтирования в одноранговой точке монтирования также будут распространяться на эту точку монтирования.
MS_PRIVATE: Это обратная ситуация по сравнению с общей точкой монтирования. Точка монтирования не распространяет события ни для каких аналогов и не получает события распространения ни от каких аналогов.
MS_SLAVE: Этот тип распространения находится посередине между MS_SHARED и MS_PRIVATE. У MS_SLAVEедомого монтирования есть master - общая группа , члены которой распространяют события монтирования и размонтирования на ms_slave монтирование. Однако ms_slave монтирование не передает события ведущей peer - группе.
MS_UNBINDABLE - не получает и не передает никаких событий монтирования и не может быть смотрирован.
Состояние точки монтирования определяется для каждой точки монтирования. Это означает, что если у вас есть, например, / и /boot, вам придется отдельно применить нужное состояние к каждой точке монтирования.
Код:
# create a mount point and tag it as shared between peers (child namespaces)
cryptonite@cryptonite:~ $mkdir X
cryptonite@cryptonite:~ $sudo mount --make-shared -t tmpfs tmpfs X/
# enter a new mount namespace
cryptonite@cryptonite:~ $sudo unshare --mount /bin/bash
root@cryptonite:/home/cryptonite#
# now let's create another mount point in the parent mount namespace
cryptonite@cryptonite:~ $mkdir Y; mount --make-shared -t tmpfs tmpfs Y/
# back to the shell within the mount namespace
root@cryptonite:/home/cryptonite/X# mount | grep Y
tmpfs on /home/cryptonite/X/Y type tmpfs (rw,relatime)
# okay we see that there is propagation on change between the two namespaces
# the mount point was tagged shared => changes are reflected in all members
# of the peer group
# back to the root mount namespace
cryptonite@cryptonite:~ $mkdir Z; sudo mount --make-private -t tmpfs tmpfs Z
cryptonite@cryptonite:~ $mount | grep Z
tmpfs on /home/cryptonite/test/Z type tmpfs (rw,relatime)
# back to the child mount namespace
root@cryptonite:/home/cryptonite/test# mount | grep Z
# nothing --> mount point tagged private from the parent namespace is
# not present in the child mount namespaceИнформация о различных типах монтажа в текущем процессе пространство имен можно найти в /proc/self/mountinfo.
Код:
╭─cryptonite@cryptonite ~
╰─$ cat /proc/self/mountinfo | head -n 3
24 31 0:22 / /sys rw,nosuid,nodev,noexec,relatime shared:7 - sysfs sysfs rw
25 31 0:23 / /proc rw,nosuid,nodev,noexec,relatime shared:15 - proc proc rw
26 31 0:5 / /dev rw,nosuid,noexec,relatime shared:2 - devtmpfs udev rw,size=8031108k,nr_inodes=2007777,mode=755UTS пространство имен
Пространство имен UTS изолирует имя хоста системы для данного процесса.
Большинство коммуникаций с хостом и обратно осуществляется через IP-адрес и порт. Однако, намного проще жить, когда у нас есть какое-то имя, привязанное к процессу. Например, поиск в файлах журналов значительно упрощается при определении имени хоста. Но помни, что в динамичной среде IP-адреса могут меняться. По аналогии с названиями жилый кварталов. Сказать водителю такси, что я живу в апартаментах City Place, обычно более результативно, чем назвать фактический адрес. Наличие нескольких имен хостов на одном физическом узле является большим подспорьем в больших контейнерных средах. Поэтому пространство имен UTS обеспечивает разделение имен хостов для процессов. Таким образом, проще общаться со службами в частной сети и проверять их журналы на хосте.
Код:
cryptonite@cryptonite:~ $sudo unshare -u /bin/bash
root@cryptonite:/home/cryptonite# hostname
cryptonite
root@cryptonite:/home/cryptonite# hostname test
root@cryptonite:/home/cryptonite# hostname
test
# meanwhile in a second terminal
cryptonite@cryptonite:~ $hostname
cryptoniteПространство имен IPC
Пространство имен IPC обеспечивает изоляцию для механизмов взаимодействия процессов, таких как семафоры, очереди сообщений, сегменты общей памяти и т.д. Обычно при fork() процесса он наследует все IPC, которые были открыты его родителем. Процессы внутри пространства имен IPC не могут видеть или взаимодействовать с ресурсами IPC верхнего пространства имен. Вот краткий пример использования сегментов общей памяти.
Код:
cryptonite@cryptonite:~ $ipcs -m
------ Shared Memory Segments --------
key shmid owner perms bytes nattch status
0x00000000 32769 cryptonite 600 4194304 2 dest
0x00000000 6 cryptonite 600 524288 2 dest
0x00000000 13 cryptonite 600 393216 2 dest
0x00000000 16 cryptonite 600 524288 2 dest
0x00000000 32785 cryptonite 600 32768 2 dest
cryptonite@cryptonite:~ $sudo unshare -i /bin/bash
root@cryptonite:/home/cryptonite#
------ Shared Memory Segments --------
key shmid owner perms bytes nattch statusПространство имен CGROUP
Cgroups - это технология, которая контролирует количество аппаратных ресурсов (RAM, HDD, I/O), потребляемых процессом.
По умолчанию CGroups создаются в виртуальной файловой системе /sys/fs/cgroup. Создание другого пространства имен CGroup, по сути, перемещает корневой каталог CGroup. Если CGroup была, например, /sys/fs/cgroup/mycgroup, новое пространство имен CGroup может использовать ее в качестве корневого каталога. Хост может видеть /sys/fs/cgroup/mycgroup/{group1,group2,group3}, но создание нового пространства имен CGroup будет означать, что новое пространство имен будет видеть только {group1,group2,group3}. Таким образом, пространства имен Cgroup виртуализируют другую виртуальную файловую систему в качестве пространства имен PID. Но какова цель обеспечения изоляции для этой системы? Согласно man-странице:
"Она предотвращает утечку информации, при которой пути каталогов cgroup за пределами контейнера иначе были бы видны процессам в контейнере. Такие утечки могли бы, например, раскрыть информацию о контейнерном фреймворке для приложений с контейнером."
В традиционной иерархии CGroup существует вероятность того, что вложенная CGroup может получить доступ к своему предку. Это означает, что процесс в /sys/fs/cgroup/mycgroup/group1 имеет возможность читать и/или манипулировать всем, что вложено в mycgroup.
А теперь всплываем!
Давайте используем все, что мы обсудили, чтобы построить полностью изолированную среду для заданного процесса, шаг за шагом, используя unshare! POC этой статьи, написанный на C и использующий системный вызов clone(), также доступен тутЪ.
Код:
# First let's download a minimal filesystem image
# which is going to be the new root fs of the isolated process
cryptonite@cryptonite:~ $wget http://dl-cdn.alpinelinux.org/alpine/v3.10/releases/x86_64/alpine-minirootfs-3.10.1-x86_64.tar.gz
cryptonite@cryptonite:~ $mkdir rootfs_alpine; tar -xzf alpine-minirootfs-3.10.1-x86_64.tar.gz -C rootfs_alpine
cryptonite@cryptonite:~ $ls rootfs_alpine
bin etc hostfs_root media opt root sbin sys usr
dev home lib mnt proc run srv tmp varХорошо, теперь у нас есть каталог, содержимое которого такое же, как у классического root-каталога Linux.
Важно отметить порядок создания пространства имен, процедур обертывания, некоторые операции (такие как PID, UTC, пространство имен IPC создание) нуждаются в расширенных привилегиях в текущем пространстве имен.
Следующий алгоритм иллюстрирует его:
1. Создайте пространство имен USER
2. Переназначить UID процесса в новом пространстве имен USER.
3. Создайте пространство имен UTC
4. Измените имя хоста в новом пространстве имен UTC.
5. Создайте пространства имен IPC/CGROUP.
6. Создайте пространство имен NET
7. Создайте и настройте veth-пару
9. Создайте пространство имен PID
10. Создайте пространство имен MNT
11. Изменение root-процесса
12. Смонтируйте /proc внутрь под новым корнем
13. Размонтировать старый корень
14. Поместите процесс в новый корневой каталог.
Код:
# create a privileged user namespace in order
# to be able to create namespaces needing administrative privileges
cryptonite@cryptonite:~ $unshare -U --kill-child /bin/bash
nobody@cryptonite:~$ id
uid=65534(nobody) gid=65534(nogroup) groups=65534(nogroup)
# let's try to create new namespaces
nobody@cryptonite:~$ unshare -iu /bin/bash
unshare: unshare failed: Operation not permitted
nobody@cryptonite:~$ id
uid=65534(nobody) gid=65534(nogroup) groups=65534(nogroup)Пользователь в пользовательском пространстве имен не может создавать новые пространства имен, поскольку он не иметь еUID=0. Чтобы исправить это, мы должны предоставить привилегии root с помощью процедуры переназначения. Как упоминалось выше, это переназначение должно выполняться из процесса в непосредственном верхнем пользовательском пространстве имен. Однако для из соображений безопасности, мы переназначим его непривилегированному пользователю за пределами пространство имен (eUID=0 -> eUID!=0).
Код:
# in another terminal; get the PID of user namespaced process
# then remap the root user inside of the namespace to an unprivileged one
# in the upper user namespace
cryptonite@cryptonite:~ $ps aux | grep /bin/bash
crypton+ 26739 0.2 0.0 19516 5040 pts/0 S+ 18:04 0:00 /bin/bash
cryptonite@cryptonite:~ $echo "0 1000 65335" | sudo tee /proc/26739/uid_map
0 1000 65335
cryptonite@cryptonite:~ $echo "0 1000 65335" | sudo tee /proc/26739/gid_map
0 1000 65335
# back to the user namespaced process
nobody@cryptonite:~/test$ id
uid=0(root) gid=0(root) groups=0(root),65534(nogroup)Теперь мы можем продолжить создание пространств имен IPC и UTS!
Код:
#create IPC and UTC namespaces
nobody@cryptonite:~$ unshare --ipc --uts --kill-child /bin/bash
root@cryptonite:~/test# ipcs
------ Message Queues --------
key msqid owner perms used-bytes messages
------ Shared Memory Segments --------
key shmid owner perms bytes nattch status
------ Semaphore Arrays --------
key semid owner perms nsems
root@cryptonite:~# hostname isolated
root@cryptonite:~# hostname
isolatedДалее мы собираемся создать сетевое пространство имен, используя виртуальный интерфейсы.
Код:
# back to the first terminal
# in order to create a pair of virtual interfaces
cryptonite@cryptonite:~ $sudo ip link add veth0 type veth peer name ceth0
# turn on one of the virtual edges and assign it an IP address
cryptonite@cryptonite:~ $sudo ip link set veth0 up
cryptonite@cryptonite:~ $sudo ip addr add 172.12.0.11/24 dev veth0
# create the network namespace
root@cryptonite:~# unshare --net --kill-child /bin/bash
root@isolated:~# sleep 30
# find the PID of the isolated process
cryptonite@cryptonite:~ $ps -fC sleep
UID PID PPID C STIME TTY TIME CMD
crypton+ 78625 78467 0 11:44 pts/0 00:00:00 sleep 30
# put the other end inside of the net space of the process
cryptonite@cryptonite:~ $sudo ip link set ceth0 netns /proc/78467/ns/net
# Let's go back to the namespaced process
# and turn the other pair of veth up and assign it an IP address
root@isolated:~# ip link
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
9: ceth0@if10: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether 76:8d:bb:61:1b:f5 brd ff:ff:ff:ff:ff:ff link-netnsid 0
root@isolated:~# ip link set lo up
root@isolated:~# ip link set ceth0 up
root@isolated:~# ip addr add 172.12.0.12/24 dev ceth0
# check the connectivity
root@isolated:~# ping -c 1 172.12.0.11
PING 172.12.0.11 (172.12.0.11) 56(84) bytes of data.
64 bytes from 172.12.0.11: icmp_seq=1 ttl=64 time=0.079 ms
...Давайте теперь создадим отдельный PID и смонтируем пространства имен и отсоединим корень файловой системы.
Код:
// create a new PID and MNT namespaces
root@cryptonite:~/test# unshare --pid --mount --fork --kill-child /bin/sh
#
# mount | grep ext4
/dev/mapper/vgcryponite-lvcryptoniteroot on / type ext4 (rw,relatime,errors=remount-ro)
// we have a copy of the rootfs mount in the mount namespace
// make the alpine root fs mountable
# mount --bind rootfs_alpine rootfs_alpine
# cd rootfs_alpine
# pwd
/home/cryptonite/test/rootfs_alpine
# mkdir hostfs_root
# ls
bin dev etc home hostfs_root lib media mnt opt proc root run sbin srv sys tmp usr var
// change the current root fs mount
# pivot_root . hostfs_root
# ls hostfs_root
bin dev lib libx32 mnt root snap tmp
boot etc lib32 lost+found opt run srv usr
cdrom home lib64 media proc sbin sys var
// at the current state we have a bind mount of the host file system in the new mount namespace
# touch hostfs_root/home/cryptonite/test/hello
cryptonite@cryptonite:~ $ls hello -l
-rw-rw-r-- 1 cryptonite cryptonite 0 Jul 6 13:45 hello
# ps
PID USER TIME COMMAND
// okay no output - the new procfs is searched at proc directory of the alpine image
// and there is nothing - let's mount the relative procfs in the alpine /proc directory
# mount -t proc proc /proc
# ps
PID USER TIME COMMAND
1 root 0:00 /bin/sh
12 root 0:00 psТеперь полностью изолируем процесс внутри текущего каталога.
Код:
// unmount the old root in the mount namespace process
# umount -l hostfs_root
# mount | wc -l
2
// we have three mount points - let's check the upper mount namespace
cryptonite@cryptonite:~ $mount | wc -l
59
# cd /
# pwd
/
# whoami
root
# ps
PID USER TIME COMMAND
1 root 0:00 /bin/sh
20 root 0:00 ps
# ipcs
------ Message Queues --------
key msqid owner perms used-bytes messages
------ Shared Memory Segments --------
key shmid owner perms bytes nattch status
------ Semaphore Arrays --------
key semid owner perms nsems
# hostname
isolated
# ls hostfs_root/
// empty directory
# rmdir hostfs_root
# ls
bin etc lib mnt proc run srv tmp var
dev home media opt root sbin sys usrМы изолировали процесс, используя почти все пространства имен. Другими словами мы сделали действительно примитивный контейнер (для тех, кто знаком с этим). НО, нет ограничений на использование аппаратных ресурсов, которое накладываются по контрольным группам.