Переведено https://arthurchiao.art/blog/cracking-k8s-network-policy/
Надеюсь что, прочитав этот пост, читатели получат более глубокое понимание основ сетевых политик на практике.

Ниже приведен минимальные настройки NetworkPolicy для достижения вышеуказанной цели (при условии все поды работают в default пространстве имен)
Kubernetes формализует это описание, ориентированное на пользователя, но оставляет реализацию каждому сетевому решению как дополнительная функция , что означает, что они могут выбрать поддерживать это или нет - если ответ НЕТ, сетевые политики созданный вами в Kubernetes, будут просто проигнорирован.
Сетевые инженеры или инженеры по безопасности могут задаться вопросом: если бы мы были ответственны за поддерживая такую функцию, как мы могли применять политику высокого уровня спецификация в базовом пути данных ? Самый простой способ может заключаться в перехвате и фильтрации в сети интерфейс каждого пода. Но на уровне трафика все, что у нас есть, это необработанные пакеты , которые содержат заголовки MAC/IP/TCP вместо меток (например, role=backend), как показано ниже:
Представление о сети и безопасности входящего трафика на сетевом интерфейсе
Встраивание меток в каждый отдельный пакет теоретически возможно, но это определенно одна из худших идей, учитывая эффективность, прозрачность, производительность, стоимость эксплуатации и т.д. Подводя итог техническому вопросу: как мы могли разрешить/запретить пакет или поток пока отсутствует возможность непосредственно понимать политику описаную на языке высокого уровня?
Разработка средства обеспечения соблюдения политик данных
Мы возьмем политику входа в качестве примера в оставшейся части этого поста. Выход аналогичен. Теперь сначала резюмируем, что у нас было под рукой:

Давайте посмотрим на первый: идентификатор службы.
Селекторы, такие как role=frontend являются метаданными, поддерживающими плоскость управления, в то время как политика Enforcer на плоскости данных хорошо справляется только с числовыми данными. Итак, для NetworkPolicy чтобы нас понял план данных, нам нужно интерпретировать селектор на основе меток в числовой. Чтобы быть конкретным, для тех модулей, которые могут быть выбраны с помощью определенных групп значений (например role=frontend;namespce=default") , мы выделяем числовой идентификатор (например 10002) для них. Итак, есть соотношение между метками и числовым идентификатором. Числовой идентификатор фактически действует как «идентификатор службы/приложения», поскольку все модули одного и того же сервиса/приложения имеют один и тот же идентификатор . Для простого примера в начале этого поста у нас будет
, мы выделяем числовой идентификатор (например 10002) для них. Итак, есть соотношение между метками и числовым идентификатором. Числовой идентификатор фактически действует как «идентификатор службы/приложения», поскольку все модули одного и того же сервиса/приложения имеют один и тот же идентификатор . Для простого примера в начале этого поста у нас будет
Талица соотношений
Здесь мы включили только две метки role=<role>; namespace=<ns> для идентификации сопоставление/распределение, но на самом деле их много, например, можно было бы хотелось бы включить serviceaccount=<sa> метку. Нам также нужен алгоритм для выделения идентификатора из заданных меток, но это выходит за рамки этого поста. Мы просто жестко кодируем это и делаем вид, что мы уже есть правильный алгоритм распределения идентификаторов.

Представление удостоверений и хранилища удостоверений для сопоставления приложений/модулей с числовым идентификатором безопасности
В нашем дизайне это простое хранилище ключей и значений с labels мы могли бы получить соответствующий identity, и наоборот. Когда структурные тождества услуг превратились в числовые тождества, мы на шаг ближе к исполнению политики.
Кэш политик с учетом уровня данных
Из соображений производительности кэш политик должен быть спроектирован как для каждого узла или для каждого модуля кэша. Здесь мы используем помодульную модель например, для политики, упомянутой в начале поста.
Мы используем src_identity:proto:dst_port:direction как ключ, вставим правило в кэш, существование правила указывает на то, что это src_identity мог дать доступ к этому proto:dst_port в этом direction.
При получении пакета, если бы мы могли решить какое приложение приходит от ( src_identity), затем по пакету можно определить путем сопоставления политик в этом кэше: если правило совпало, пусть пакет проходит, иначе просто сбросим его. Теперь вопрос превращается в: как соотнести пакет с его личностью (отправителя) -- >> создайте кэш IP-адресов.
Учитывайте тот факт, что:
Так, IP-адрес модуля может быть однозначно сопоставлен с идентификатором модуля. . Таким образом, мы вводим еще один кеш: сопоставление pod IP-адреса с его идентификатором, мы называем это ipcache, который делиться этой информацией, как показано на схеме ниже:

Представляем ipcache для хранения сопоставлений IP->Identity
Например, если role=frontend имеет два pod 10.5.2.2 а также 10.5.3.3, и role=backend есть pod с IP 10.5.4.4, то в ipcache будем иметь:
Теперь пакеты могут быть легко проанализированы.

Перехват и анализ трафика, а также запрос и применение политик входящего трафика

Шаги 1–3 связаны с панелью управления:
Этот пост в основном посвящен части плоскости данных, поэтому для реализации POC мы просто жестко закодируем то, что делает плоскость управления (шаги 1–3). Для части dataplane (шаги 4–7) мы используем eBPF.
Некоторые макросы, константы, структуры, а также наш кэш политик сам (жестко запрограммированный только с одним правилом):
Логика пути к данным, включая ipcache и поиск кэша политик, а также как основная логика политики:
Загрузите и прикрепите bpf:
Очистка:
Мы предполагаем, что pod использует пару veth в качестве своего сетевого интерфейса, это верно для большинства сетевых решений Kubernetes;
$nicявляется хост-концом пары veth;
Хост-конец пары veth имеет противоположное направление трафика с стороны, например, входящий трафик пода соответствует выход хост-конца. Вот почему мы прикрепляем программ BPF с egress-флагом. Эти вещи будут более понятны в разделе с примерами. Просто продолжайте, если они сейчас вас смущают.

Имитация подов с помощью контейнеров, поскольку в нашем случае они не будут иметь значения
Создайте четыре контейнера напрямую с помощью docker run, каждый представляет role=db, role=frontend также role=backendpod
Контейнеры подключены к стандартному docker Линукс-мостом витой парой. Мы используем официальную redis docker, поэтому мы можем легко протестировать подключение L4. Мы также будем использовать nsenter-ctn выполнять команды в пространстве имен контейнера, чтобы обойти отсутствие инструментов (например, ifconfig, iproute2, tcpdump) в контейнере,
Поместите фрагмент в свой ~/.bashrc файл затем source ~/.bashrc.
Теперь сначала проверьте IP-адрес каждого pod :
ПРОВЕРКИ
$ docker exec -it frontend sh | $ docker exec -it backend1 sh | $ docker exec -it backend2 sh
# redis-cli -h 172.17.0.2 ping | # redis-cli -h 172.17.0.2 ping | # redis-cli -h 172.17.0.2 ping
PONG | PONG | PONG
Как и ожидалось! Результат показан ниже:

Нет политики: доступ есть как у внешних, так и у внутренних модулей. tcp:6379@db
Теперь давайте загрузим и подключим нашу программу BPF к сетевому интерфейсу role=dbсpod. У нас есть два возможных места для прикрепления программы:
Окончательный эффект политики будет таким же, поэтому мы просто выбираем второй, т.к. это позволяет избежать переключения сетевых пространств имен при выполнении команд. Теперь найти хост-конец пары veth за role=dbконтейнер:
Сетевые устройства с уникальным индексом 4, а также 5 находятся два конца пары veth , поэтому мы ищем ifindex=5 устройство на хосте, к которому мы прикрепим программу BPF:
Теперь мы можем загрузить и подключить наш BPF Enforcer и жестко заданную в нем политику:
Протестируйте еще раз:
$ docker exec -it frontend sh | $ docker exec -it backend1 sh | $ docker exec -it backend2 sh
# redis-cli -h 172.17.0.2 ping | # redis-cli -h 172.17.0.2 ping | # redis-cli -h 172.17.0.2 ping
^C | PONG | PONG
Backend1, а также backend2 все еще правильно настроены, но на frontend время ответа вышло (поскольку его пакеты молча отбрасывались нами в соответствии с политикой), как и ожидалось:

С политикой: внешний модуль запрещен, а внутренние модули разрешены
Теперь удалиm BPF Enforcer и политику и снова протестируем
$ docker exec -it frontend sh | $ docker exec -it backend1 sh | $ docker exec -it backend2 sh
# redis-cli -h 172.17.0.2 ping | # redis-cli -h 172.17.0.2 ping | # redis-cli -h 172.17.0.2 ping
PONG | PONG | PONG
Связь с фронтенд-модулем восстановлена !

Политика разрешения по умолчанию: применение на стороне хоста пары veth
 эквивалентно, если Прикрепляем программу BPF к стороне контейнера пары veth
эквивалентно, если Прикрепляем программу BPF к стороне контейнера пары veth
Политика по умолчанию может быть достигнута легко: мы можем обозначить специальное {0, 0, 0, 0} правило по умолчанию allow any правило, тогда начальный кеш политик для пода будет выглядеть следующим образом:
потом cat канал трассировки для проверки журнала:
Практическое решение NerworkPolice
Переизобразим схему, составленную выше.

Cilium как сетевое решение Kubernetes реализует, а также расширяет стандартный Kubernetes NetworkPolicy. Если быть точным, он поддерживает три виды политик: стандартные Kubernetes NetworkPolicy, CiliumNetworkPolicy и ClusterwideCiliumNetworkPolicy.
По сути, Cilium работает почти так:, компоненты дизайна нашей игрушки могут быть отображены напрямую к соответствующим компонентам в Cilium:

Применение политики входа внутри узла Cilium
Мы еще не упомянули одну вещь: свойство прозрачности (прозрачно подключать и фильтровать трафик) нашего игрушечного энфорсера к верхним сетевым инфраструктурам делает его совместимым с некоторыми сетевыми решениями, которые еще не поддерживают сетевую политику, такими как flannel. Именно поэтому Cilium поддерживает CNI chaining с flannel.
Со всем, что было обсуждено выше, интересно поразмыслить над Kubernetes модель .
Kubernetes использует модель «IP-адрес на модуль» , которая имеет три принципа, давайте глянем их и поймем как разрабатывать политики:
Этот пост описывает механизм образовательной политики для Kubernetes. NetworkPolicy, и реализует его менее чем в 100 строках кода eBPF (без сюрпризов, фрагменты кода позаимствовали из проекта Cilium , и намеренно назвали переменные/функции в стиле Cilium).
После прочтения этого поста пользователи должны быть более знакомы с основные рабочие механизмы контроля доступа в Kubernetes+Cilium.
Взлом сетевой политики Kubernetes
Код и скрипты: https://github.com/ArthurChiao/arth...aster/assets/code/cracking-k8s-network-policyНадеюсь что, прочитав этот пост, читатели получат более глубокое понимание основ сетевых политик на практике.
Контроль доступа ( NetworkPolicy ) в Kubernetes.
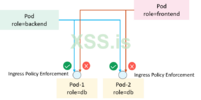
Kubernetes предоставляет NetworkPolicy контролировать L3/L4 потоки трафика приложений. Пример изображен ниже, где мы хотели бы все машины помечены role=backend(клиенты) чтобы получить доступ к tcp: 6379из все машины с тегом role=db(серверы), а все остальные клиенты должны быть запрещены.
Контроль доступа в Kubernetes с помощью NetworkPolicy
Ниже приведен минимальные настройки NetworkPolicy для достижения вышеуказанной цели (при условии все поды работают в default пространстве имен)
Код:
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: network-policy-allow-backend
spec:
podSelector: # Targets that this NetworkPolicy will be applied on
matchLabels:
role: db
ingress: # Apply on targets's ingress traffic
- from:
- podSelector: # Entities that are allowed to access the targets
matchLabels:
role: backend
ports: # Allowed proto+port
- protocol: TCP
port: 6379Kubernetes формализует это описание, ориентированное на пользователя, но оставляет реализацию каждому сетевому решению как дополнительная функция , что означает, что они могут выбрать поддерживать это или нет - если ответ НЕТ, сетевые политики созданный вами в Kubernetes, будут просто проигнорирован.
1.2 Как применяются сетевые политики?
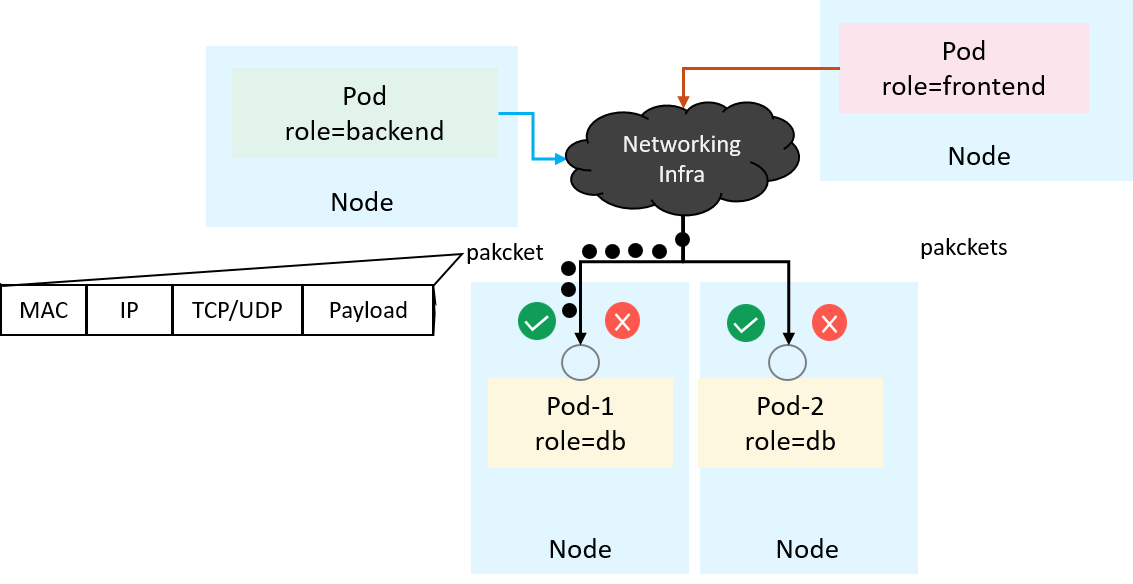
Сетевые инженеры или инженеры по безопасности могут задаться вопросом: если бы мы были ответственны за поддерживая такую функцию, как мы могли применять политику высокого уровня спецификация в базовом пути данных ? Самый простой способ может заключаться в перехвате и фильтрации в сети интерфейс каждого пода. Но на уровне трафика все, что у нас есть, это необработанные пакеты , которые содержат заголовки MAC/IP/TCP вместо меток (например, role=backend), как показано ниже:
Представление о сети и безопасности входящего трафика на сетевом интерфейсе
Встраивание меток в каждый отдельный пакет теоретически возможно, но это определенно одна из худших идей, учитывая эффективность, прозрачность, производительность, стоимость эксплуатации и т.д. Подводя итог техническому вопросу: как мы могли разрешить/запретить пакет или поток пока отсутствует возможность непосредственно понимать политику описаную на языке высокого уровня?
Разработка средства обеспечения соблюдения политик данных
Мы возьмем политику входа в качестве примера в оставшейся части этого поста. Выход аналогичен. Теперь сначала резюмируем, что у нас было под рукой:
Что знает или понимает каждый уровень управления/данных
- В панели управления Kubernetes у нас есть сервис, модуль и политика. Ресурсы описаны в их specс (и отражено в их status ),
- В панель данных все, что может видеть, это сырые пакеты.
Давайте посмотрим на первый: идентификатор службы.
Знакомство с идентификацией службы
Селекторы, такие как role=frontend являются метаданными, поддерживающими плоскость управления, в то время как политика Enforcer на плоскости данных хорошо справляется только с числовыми данными. Итак, для NetworkPolicy чтобы нас понял план данных, нам нужно интерпретировать селектор на основе меток в числовой. Чтобы быть конкретным, для тех модулей, которые могут быть выбраны с помощью определенных групп значений (например role=frontend;namespce=default
, мы выделяем числовой идентификатор (например 10002) для них. Итак, есть соотношение между метками и числовым идентификатором. Числовой идентификатор фактически действует как «идентификатор службы/приложения», поскольку все модули одного и того же сервиса/приложения имеют один и тот же идентификатор . Для простого примера в начале этого поста у нас будетТалица соотношений
| названия | Значение |
| role=db;namespace=default; | 10001 |
| role=frontend;namespace=default; | 10002 |
| role=backend;namespace=default; | 10003 |
Здесь мы включили только две метки role=<role>; namespace=<ns> для идентификации сопоставление/распределение, но на самом деле их много, например, можно было бы хотелось бы включить serviceaccount=<sa> метку. Нам также нужен алгоритм для выделения идентификатора из заданных меток, но это выходит за рамки этого поста. Мы просто жестко кодируем это и делаем вид, что мы уже есть правильный алгоритм распределения идентификаторов.
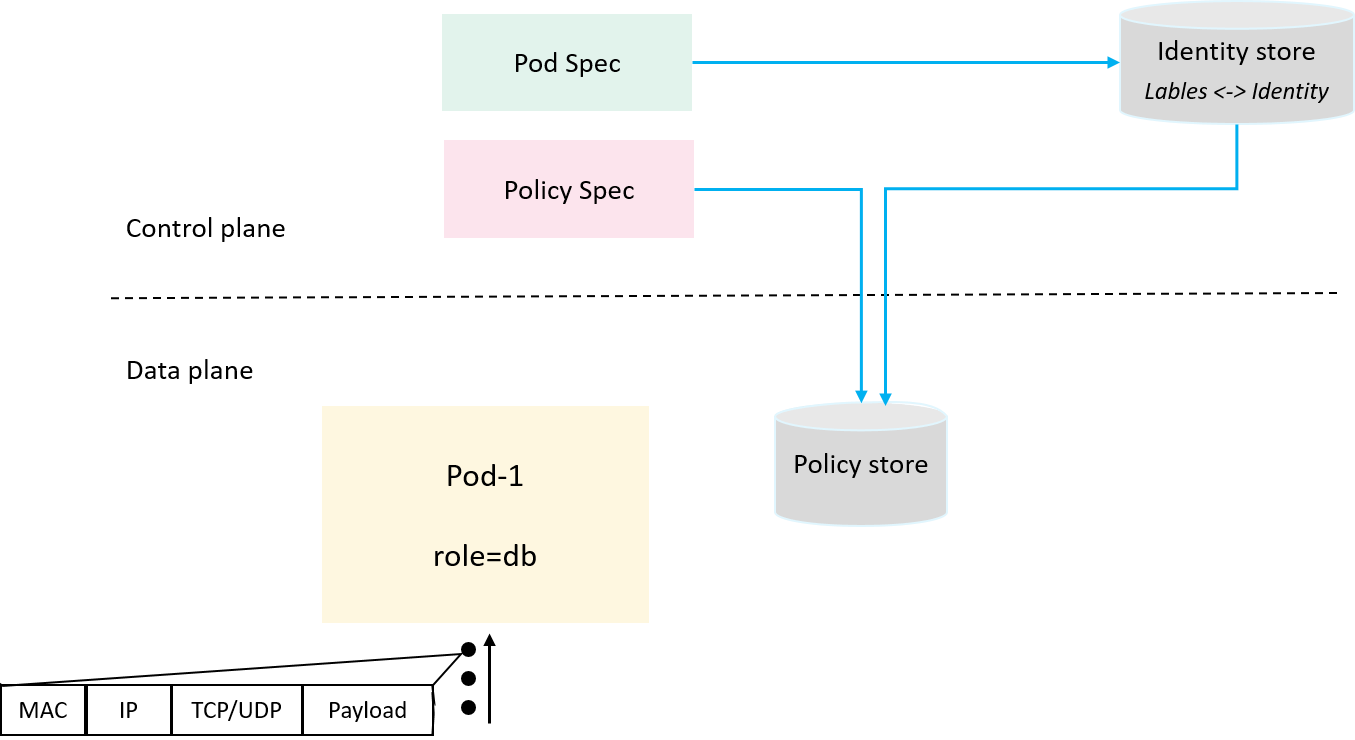
2.2 Представляем хранилище удостоверений: Labels <-> Identity
Для хранения labels <-> identity метаданных, нам нужно хранилище удостоверений .
Представление удостоверений и хранилища удостоверений для сопоставления приложений/модулей с числовым идентификатором безопасности
В нашем дизайне это простое хранилище ключей и значений с labels мы могли бы получить соответствующий identity, и наоборот. Когда структурные тождества услуг превратились в числовые тождества, мы на шаг ближе к исполнению политики.
2.3 Знакомство с кэшем политик
С labels <-> identity сопоставлением, мы можем преобразовать спецификацию политики на основе меток в числовое представление, которое наша плоскость данных понимает. Нам также нужно сохранить его в кеше dataplane, и мы назовем его кэш политик , как показано ниже,
Кэш политик с учетом уровня данных
Из соображений производительности кэш политик должен быть спроектирован как для каждого узла или для каждого модуля кэша. Здесь мы используем помодульную модель например, для политики, упомянутой в начале поста.
Код:
spec:
podSelector: # Targets that this NetworkPolicy will be applied on
matchLabels:
role: db
ingress: # Apply on targets's ingress traffic
- from:
- podSelector: # Entities that are allowed to access the targets
matchLabels:
role: backend
ports: # Allowed proto+port
- protocol: TCP
port: 6379Мы используем src_identity:proto:dst_port:direction как ключ, вставим правило в кэш, существование правила указывает на то, что это src_identity мог дать доступ к этому proto:dst_port в этом direction.
Содержимое кэша политик для role=db pode
| Ключ ( SrcIdentity:Proto:Portirection) | Значение (значение игнорируется) |
| 10003cp:6379:ingress | 1 |
При получении пакета, если бы мы могли решить какое приложение приходит от ( src_identity), затем по пакету можно определить путем сопоставления политик в этом кэше: если правило совпало, пусть пакет проходит, иначе просто сбросим его. Теперь вопрос превращается в: как соотнести пакет с его личностью (отправителя) -- >> создайте кэш IP-адресов.
Знакомство с IPCache: PodIP -> Identity
Несмотря на то, что существует много случаев сопоставления пакета с его идентификатором, здесь мы начать со сложного: пользовательский трафик не изменяется или инкапсулируется сетевым решением. Это означает, что мы не можем получить идентификационную информацию непосредственно из самого пакета. Позже мы увидим другие сценарии.
Учитывайте тот факт, что:
- IP-адрес пода уникален ( hostNetwork pod оставлены для последующего обсуждения)
- Идентификация модуля является детерминированной (все модули с одинаковыми метками имеют одинаковую идентичность).
Так, IP-адрес модуля может быть однозначно сопоставлен с идентификатором модуля. . Таким образом, мы вводим еще один кеш: сопоставление pod IP-адреса с его идентификатором, мы называем это ipcache, который делиться этой информацией, как показано на схеме ниже:
Представляем ipcache для хранения сопоставлений IP->Identity
Например, если role=frontend имеет два pod 10.5.2.2 а также 10.5.3.3, и role=backend есть pod с IP 10.5.4.4, то в ipcache будем иметь:
IP-кэш
| Ключ ( IP) | ( Identit |
| 10.5.2.2 | 10001 |
| 10.5.3.3 | 10001 |
| 10.5.4.4 | 10002 |
Теперь пакеты могут быть легко проанализированы.
Перехват и парсинг трафика
Далее создадим последнюю часть нашего решения: перехват трафика, извлечение информация об IP/протоколе/портах из заголовков пакетов, затем запрос и принудительное применение политики:
Перехват и анализ трафика, а также запрос и применение политик входящего трафика
Compose up: сквозной рабочий процесс
Сквозной рабочий процесс
Шаги 1–3 связаны с панелью управления:
- Поды созданы , удостоверения, выделенные и видимые всеми сторонами (глобальное хранилище удостоверений);
- ip->identity сопоставления, синхронизированные с данными ipcache ;
- Политика создана , преобразованное из описания на основе меток в описание на основе удостоверений и синхронизировано с кэшем политики данных;
- Разобрать заголовок пакета , извлечь информацию об IP/протоколе/порте и т. д.;
- Получить src_identity из ipcache с src_ip как ключ;
- Получить политику из кеша политик с информацией src_identity/proto/dst_port/direction;
- allow если политика найдена, иначе deny.
Реализуйте средство принудительного исполнения с помощью eBPF
Этот пост в основном посвящен части плоскости данных, поэтому для реализации POC мы просто жестко закодируем то, что делает плоскость управления (шаги 1–3). Для части dataplane (шаги 4–7) мы используем eBPF.
Код
Некоторые макросы, константы, структуры, а также наш кэш политик сам (жестко запрограммированный только с одним правилом):
Код:
const int l3_off = ETH_HLEN; // IP header offset in raw packet data
const int l4_off = l3_off + 20; // TCP header offset: l3_off + IP header
const int l7_off = l4_off + 20; // Payload offset: l4_off + TCP header
#define DB_POD_IP 0x020011AC // 172.17.0.2 in network order
#define FRONTEND_POD_IP 0x030011AC // 172.17.0.3 in network order
#define BACKEND_POD1_IP 0x040011AC // 172.17.0.4 in network order
#define BACKEND_POD2_IP 0x050011AC // 172.17.0.5 in network order
struct policy { // Ingress/inbound policy representation:
int src_identity; // traffic from a service with 'identity == src_identity'
__u8 proto; // are allowed to access the 'proto:dst_port' of
__u8 pad1; // the destination pod.
__be16 dst_port;
};
struct policy db_ingress_policy_cache[4] = { // Per-pod policy cache,
{ 10003, IPPROTO_TCP, 0, 6379 }, // We just hardcode one policy here
{},
};Логика пути к данным, включая ipcache и поиск кэша политик, а также как основная логика политики:
Код:
static __always_inline int ipcache_lookup(__be32 ip) {
switch (ip) {
case DB_POD_IP: return 10001;
case FRONTEND_POD_IP: return 10002;
case BACKEND_POD1_IP: return 10003;
case BACKEND_POD2_IP: return 10003;
default: return -1;
}
}
static __always_inline int policy_lookup(int src_identity, __u8 proto, __be16 dst_port) {
struct policy *c = db_ingress_policy_cache;
for (int i=0; i<4; i++) {
if (c[i].src_identity == src_identity && c[i].proto == proto && c[i].dst_port == dst_port)
return 1;
}
return 0; // not found
}
static __always_inline int __policy_can_access(struct __sk_buff *skb, int src_identity, __u8 proto) {
void *data = (void *)(long)skb->data;
void *data_end = (void *)(long)skb->data_end;
if (proto == IPPROTO_TCP) {
if (data_end < data + l7_off)
return 0;
struct tcphdr *tcp = (struct tcphdr *)(data + l4_off);
return policy_lookup(src_identity, proto, ntohs(tcp->dest))? 1 : 0;
}
return 0;
}
__section("egress") // veth's egress relates to pod's ingress
int tc_egress(struct __sk_buff *skb) {
// 1. Basic validation
void *data = (void *)(long)skb->data;
void *data_end = (void *)(long)skb->data_end;
if (data_end < data + l4_off) // May be system packet, for simplicity just let it go
return TC_ACT_OK;
// 2. Extract header and map src_ip -> src_identity
struct iphdr *ip4 = (struct iphdr *)(data + l3_off);
int src_identity = ipcache_lookup(ip4->saddr);
if (src_identity < 0) // packet from a service with unknown identity, just drop it
return TC_ACT_SHOT;
// 3. Determine if traffic with src_identity could access this pod
if (__policy_can_access(skb, src_identity, ip4->protocol))
return TC_ACT_OK;
return TC_ACT_SHOT;
}Компиляция
Код:
$ export app=toy-enforcer
$ clang -O2 -Wall -c $app.c -target bpf -o $app.oЗагрузите и прикрепите bpf:
Код:
sudo tc qdisc add dev $nic clsact && sudo tc filter add dev $nic egress bpf da obj $app.o sec egressОчистка:
Код:
sudo tc qdisc del dev $nic clsact 2>&1 >/dev/nullМы предполагаем, что pod использует пару veth в качестве своего сетевого интерфейса, это верно для большинства сетевых решений Kubernetes;
$nicявляется хост-концом пары veth;
Хост-конец пары veth имеет противоположное направление трафика с стороны, например, входящий трафик пода соответствует выход хост-конца. Вот почему мы прикрепляем программ BPF с egress-флагом. Эти вещи будут более понятны в разделе с примерами. Просто продолжайте, если они сейчас вас смущают.
Тестовая среда и проверка
Настройка тестовой среды
Для управления трафиком на сетевом интерфейсе пода, исходит ли трафик с одного и того же узла или другие узлы не имеют значения для нас. Таким образом, мы можем проверить политику в такой упрощенной топологии:
Имитация подов с помощью контейнеров, поскольку в нашем случае они не будут иметь значения
Создайте четыре контейнера напрямую с помощью docker run, каждый представляет role=db, role=frontend также role=backendpod
Код:
$ sudo docker run -d --name db redis:6.2.6
$ sudo docker run -d --name frontend redis:6.2.6 sleep 100d
$ sudo docker run -d --name backend1 redis:6.2.6 sleep 100d
$ sudo docker run -d --name backend2 redis:6.2.6 sleep 100dКонтейнеры подключены к стандартному docker Линукс-мостом витой парой. Мы используем официальную redis docker, поэтому мы можем легко протестировать подключение L4. Мы также будем использовать nsenter-ctn выполнять команды в пространстве имен контейнера, чтобы обойти отсутствие инструментов (например, ifconfig, iproute2, tcpdump) в контейнере,
Код:
# A simple wrapper over nsenter
function nsenter-ctn () {
CTN=$1 # container ID or name
PID=$(sudo docker inspect --format "{{.State.Pid}}" $CTN)
shift 1 # remove the first arguement, shift others to the left
sudo nsenter -t $PID $@
}Поместите фрагмент в свой ~/.bashrc файл затем source ~/.bashrc.
Теперь сначала проверьте IP-адрес каждого pod :
Код:
$ for ctn in db frontend backend1 backend2; do nsenter-ctn $ctn -n ip addr show eth0 | grep inet | awk '{print $2}'; done
172.17.0.2/16
172.17.0.3/16
172.17.0.4/16
172.17.0.5/16ПРОВЕРКИ
Без политики
Сделайте повторный пинг role=db контейнер из каждого клиентского контейнера, сервер вернет PONG если все правильно :$ docker exec -it frontend sh | $ docker exec -it backend1 sh | $ docker exec -it backend2 sh
# redis-cli -h 172.17.0.2 ping | # redis-cli -h 172.17.0.2 ping | # redis-cli -h 172.17.0.2 ping
PONG | PONG | PONG
Как и ожидалось! Результат показан ниже:
Нет политики: доступ есть как у внешних, так и у внутренних модулей. tcp:6379@db
С определенной политикой: allow role=backend -> tcp:6379@role=db
Теперь давайте загрузим и подключим нашу программу BPF к сетевому интерфейсу role=dbсpod. У нас есть два возможных места для прикрепления программы:
- Контейнерная сторона пары veth ( eth0 внутри контейнера)
- Принимающая сторона пары veth ( veth xxx устройство на мосту)
Окончательный эффект политики будет таким же, поэтому мы просто выбираем второй, т.к. это позволяет избежать переключения сетевых пространств имен при выполнении команд. Теперь найти хост-конец пары veth за role=dbконтейнер:
Код:
$ nsenter-ctn db -n ip link 4: eth0@if5: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT
link/ether 02:42:ac:11:00:02 brd ff:ff:ff:ff:ff:ff link-netnsid 0Сетевые устройства с уникальным индексом 4, а также 5 находятся два конца пары veth , поэтому мы ищем ifindex=5 устройство на хосте, к которому мы прикрепим программу BPF:
Код:
$ ip link 5: vethcf236fd@if4: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master docker0
link/ether 66:d9:a0:1a:2b:a5 brd ff:ff:ff:ff:ff:ff link-netnsid 0Теперь мы можем загрузить и подключить наш BPF Enforcer и жестко заданную в нем политику:
Код:
$ export nic=vethcf236fd
$ sudo tc qdisc add dev $nic clsact && sudo tc filter add dev $nic egress bpf da obj $app.o sec egressПротестируйте еще раз:
$ docker exec -it frontend sh | $ docker exec -it backend1 sh | $ docker exec -it backend2 sh
# redis-cli -h 172.17.0.2 ping | # redis-cli -h 172.17.0.2 ping | # redis-cli -h 172.17.0.2 ping
^C | PONG | PONG
Backend1, а также backend2 все еще правильно настроены, но на frontend время ответа вышло (поскольку его пакеты молча отбрасывались нами в соответствии с политикой), как и ожидалось:
С политикой: внешний модуль запрещен, а внутренние модули разрешены
Теперь удалиm BPF Enforcer и политику и снова протестируем
Код:
$ sudo tc qdisc del dev $nic clsact 2>&1 >/dev/null$ docker exec -it frontend sh | $ docker exec -it backend1 sh | $ docker exec -it backend2 sh
# redis-cli -h 172.17.0.2 ping | # redis-cli -h 172.17.0.2 ping | # redis-cli -h 172.17.0.2 ping
PONG | PONG | PONG
Связь с фронтенд-модулем восстановлена !
С политикой по умолчанию: allow any
Мы могли бы также поддерживать значение по умолчанию allow any политики , которая имеет самый низкий приоритет , и ведет себя так, как будто политики вообще нет. С таким дизайном наш игрушечные настройки политики можно загружаться и подключаться, когда pod создается и отсоединяется и удаляется при уничтожении модуля - согласованно с жизненным циклом pod. Проиллюстрируем эффект:
Политика разрешения по умолчанию: применение на стороне хоста пары veth
Политика по умолчанию может быть достигнута легко: мы можем обозначить специальное {0, 0, 0, 0} правило по умолчанию allow any правило, тогда начальный кеш политик для пода будет выглядеть следующим образом:
Код:
struct policy db_ingress_policy_cache[] = {
{ 0, 0, 0, 0 }, // default rule: allow any
};
{/CODE]
Пока пользователь добавляет конкретную политику, агент для поддержания кэш политики должен удалить это правило по умолчанию .
[HEADING=1]4.3 Регистрация и отладка [/HEADING]
Мы также встроили в исходный код некоторый код ведения журнала для отладки. Использовать это, сначала убедитесь, что переключатель трассировки включен:
[CODE]$ sudo cat /sys/kernel/tracing/tracing_on
1потом cat канал трассировки для проверки журнала:
Код:
$ sudo cat /sys/kernel/debug/tracing/trace_pipe | grep redis
redis-server-2581 [001] d.s1 46820.560456: bpf_trace_printk: policy_lookup: 10003 6 6379
redis-server-2581 [001] d.s1 46820.560468: bpf_trace_printk: Toy-enforcer: PASS, as policy found
redis-cli-10540 [003] d.s1 46824.145704: bpf_trace_printk: policy_lookup: 10002 6 6379
redis-cli-10540 [003] d.s1 46824.145724: bpf_trace_printk: Toy-enforcer: DROP, as policy not foundПрактическое решение NerworkPolice
Переизобразим схему, составленную выше.
- Автоматизируйте шаги 1–3. Такие как,
- Предоставляем глобальное хранилище удостоверений (вместо жесткого кода) и алгоритм распределения идентификаторов;
- Предоставляем агента для каждого узла , который отвечает за
- Распределение личности,
- Отслеживание ресурсов политик в Kubernetes, преобразование и отправка в кэш политик dataplane,
- Просмотр ресурсов пода в Kubernetes и отправка IP->identityметаданные в локальный ipcache.
- Выполнять за поток вместо за пакет обеспечение соблюдения политики.
Например, кэш политик поиска только для пакетов рукопожатия TCP-потока, и если соединение разрешено и установлено, все последующие пакеты этого потока могут просто проходить без сопоставления с политики. Это включает в себя отслеживание соединения (коннтрак) - Поддержка других типов целевых селекторов, таких как селектор пространства имен или селектор IPBlock.
- Оптимизации
- Внедрить идентификатор вместе с пакетом если у нас есть дополнительные ресурсы, например, в случае туннелирования VxLAN. ipcache можно избежать в этом сценарии.
- Хранение ipcache/policycache с подходящими картами eBPF .
- Использование хеширования при поиске политики вместо нескольких необработанных проверок на равенство.
NetworkPolicy поддержка Cilium
Cilium как сетевое решение Kubernetes реализует, а также расширяет стандартный Kubernetes NetworkPolicy. Если быть точным, он поддерживает три виды политик: стандартные Kubernetes NetworkPolicy, CiliumNetworkPolicy и ClusterwideCiliumNetworkPolicy.
По сути, Cilium работает почти так:, компоненты дизайна нашей игрушки могут быть отображены напрямую к соответствующим компонентам в Cilium:
- Глобальный магазин удостоверений -> Cilium kvstore (cilium-etcd)
- Агент для каждого узла -> cilium-agent
- ipcache -> Cilium на узел ipcache ( /sys/fs/bpf/tc/globals/cilium_ipcache)
- кеш политики -> Cilium для каждой конечной точки кэш политик ( /sys/fs/bpf/tc/globals/cilium_policy_xx)
Применение политики входа внутри узла Cilium
Мы еще не упомянули одну вещь: свойство прозрачности (прозрачно подключать и фильтровать трафик) нашего игрушечного энфорсера к верхним сетевым инфраструктурам делает его совместимым с некоторыми сетевыми решениями, которые еще не поддерживают сетевую политику, такими как flannel. Именно поэтому Cilium поддерживает CNI chaining с flannel.
Размышления о сетевой модели Kubernetes
Со всем, что было обсуждено выше, интересно поразмыслить над Kubernetes модель .
Kubernetes использует модель «IP-адрес на модуль» , которая имеет три принципа, давайте глянем их и поймем как разрабатывать политики:
- Принцип 1: «модули на узле могут взаимодействовать со всеми модулями на всех узлах без NAT»
Это основа нашего решения по обеспечению безопасности. Без этого свойства связь модуля будет совершенно другой, например: через NAT и/или уникальные порты на узле, что нарушит нашу идентификацию и дизайн ipcache. - Принцип 2: «агенты на узле (например, системные демоны, kubelet) могут взаимодействовать со всеми модулями на этом узле»
Он не может идентифицировать «узлы» в нашем предыдущем дизайне, и поскольку все узлы могут общаться со всеми модулями, будут утечки безопасности, если мы не сможем контролировать от/к узлам pod-трафика. Итак, мы должны предоставить что-то для определениять, что такое узел, и даже точнее, что такое локальный узел и что такое удаленный узел для модуля. Это как раз то, что node и remote-node специальные идентичности предназначены для Cilium.
Кроме того, Cilium также поддерживает так называемый «хост-брандмауэр», таргетинг трафика от/к узлам (идентифицируется по IP-адресу узла в базовом). - Принцип 3: «модули в хост-сети узла могут взаимодействовать со всеми модулями на всех узлах без NAT»
Опять же, это свойство противоречит нашему дизайну ipcache: хотя селекторы меток могут идентифицировать эти модули, у них нет IP-адресов. Это также limitation of Cilium (модули hostNetwork нельзя отличить друг от друга).
Заключение
Этот пост описывает механизм образовательной политики для Kubernetes. NetworkPolicy, и реализует его менее чем в 100 строках кода eBPF (без сюрпризов, фрагменты кода позаимствовали из проекта Cilium , и намеренно назвали переменные/функции в стиле Cilium).
После прочтения этого поста пользователи должны быть более знакомы с основные рабочие механизмы контроля доступа в Kubernetes+Cilium.