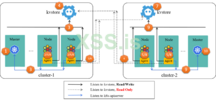В этом посте рассказывается о наших исследованиях облачной нативной безопасности для Kubernetes. а также с старыми рабочими нагрузками, с CiliumNetworkPolicy для доступа L3/L4 контроль в качестве первого шага. Необходимы некоторые базовые знания об управлении доступом в Kubernetes. прежде чем углубляться в детали. Если вы уже знакомы с этими вещами, вы можно просто перемотать вперед.
В Kubernetes пользователи могут контролировать L3/L4(уровень IP/порта) потоки трафика приложений с NetworkPolicies.
А NetworkPolicy описывает как общаться различным сущностям на уровне OSI L3/L4, где «сущности» здесь могут быть идентифицированы комбинацией следующих 3 идентификаторов:

Мы хотели бы, чтобы все сущности с тегом role=backend (сторона клиента) для доступа к сервису TCP/6379 всех сущностей с тэгом role=db(серверная сторона), а также другие клиенты, не входящие в эту спецификацию, должны быть отклонены. Ниже приведен минимальный NetworkPolicy для достижения цели (при условии, что клиентские и серверные модули в default пространстве имен):
Хотя Kubernetes определяет NetworkPolicy, это оставляет реализацию на усмотрение каждому сетевому решению , это означает, что если вы не используете сетевое решение, поддерживающее NetworkPolicy, примененные вами политики не будут иметь никакого эффекта.
Дополнительные сведения о Kubernetes NetworkPolicy см. Сетевые политики
Cilium как сетевое решение Kubernetes реализует, а также расширяет стандартный Кубернет NetworkPolicy. Чтобы быть конкретным, он поддерживает три вида политик:
4. Как управлять устаревшими рабочими нагрузками (например, VM/BM/non-cilium-pods)?
Для компаний, которые развивались более десяти лет, весьма вероятно, что существует не только прямой трансграничный трафик, но и устаревшие рабочие нагрузки, таких как виртуальные машины в OpenStack, системе BM или модулях Kubernetes на базе сетевые решения, отличных от Cilium.
Некоторые из них могут быть временными, например, миграция машин, не оснащенных non-cilium-pods в кластер на базе Cilium, но некоторые могут и не быть, типа ВМ все равно нельзя, заменены контейнерами в определенных сценариях.
Поэтому возникает естественный вопрос: как скрыть эти объекты в вашем решении для обеспечения безопасности?
5. Соображения производительности
Производительность должна быть одним из основных соображений для любого технического решения. С точки зрения решения безопасности мы должны позаботиться как минимум о:
Будьте лучше знакомы со своей системой, чем ваши пользователи, вместо того, чтобы вас называли до последнего в полночь.
Сейчас мы увидим, как мы разработали решение сначала до конца, отвечающее следующим требованиям:
Начиная с самого простого случая, рассмотрим контроль доступа в автономный кластер Kubernetes на базе Cilium.
Как показано в логической архитектуре ниже, агент Cilium на каждом сервере Kubernetes рабочий узел слушает два хранилища ресурсов :

В этой стандартной конфигурации с одним кластером собственного CNP/CCNP будет достаточно для применение политики, в том, что cilium-agent на каждом узле кэширует все активное идентификационное пространство кластера . Пока клиенты приходят из одного и того же кластера, каждый агент будет знать свой идентификатор безопасности, просматривая его локальный кеш, затем решите, куда направить трафик:


Теперь рассмотрим случай с несколькими кластерами.
Представьте, что модули серверов находятся в одном кластере, но клиентские модули разбросаны по нескольким кластерам , а клиенты обращаются к серверам напрямую (без шлюзов).
Cilium поставляется со встроенным многокластерным решением под названием ClusterMesh. По сути, он настраивает каждый cilium-агент на прослушку KVStore других кластеров . Таким образом, каждый агент получает информацию об идентификаторе безопасности модулей в удаленных кластерах . Ниже представлен случай с двумя кластерами как с сеткой:

Таким образом, при поступлении трафика от удаленных кластеров локальный агент может определить его контекст безопасности с локальной базой знаний:

ClusterMesh как многокластерное решение является простым, но это имеет тенденцию быть уязвимым для большинства кластеров. Поэтому в итоге мы разработали собственное мультикластерное решение под названием KVStoreMesh. Он легкий и совместимый с исходящим трафиком потоком .
Короче говоря, вместо того, чтобы позволять каждому агенту извлекать удаленные удостоверения для всех удаленных KVStore мы разработали для этого оператор области кластера, который синхронизирует удаленные удостоверения KVStore локального кластера . Проще говоря, в каждом кластере Kubernetes мы запускаем kvstoremesh-operator, который
Двухкластерный: Настройка мультикластера с помощью KVStoreMesh

Настройка мультикластера с помощью KVStoreMesh (оператор kvstoremesh для краткости опущен)

Технически, с KVStoreMesh агенты получают удаленные удостоверения от своих локальный kvstore напрямую. Это гарантирует - только что как ClusterMesh, но без проблем со стабильностью и гибкостью. Сравнение ClusterMesh и KVStoreMesh будет подробно описано позже.
Превосходный дизайн Cilium заставляет вышеописанную идею работать большую часть времени, и мы исправили некоторые ошибки (большинство из которых уже находится на рассмотрении), чтобы остальные случаи также работали.
2.3 Применение политики к устаревшим клиентам
С помощью CNP/CCNP и KVStoreMesh мы решили задачи с одним и несколькими кластерами. Теперь давайте сделаем один шаг Кроме того, рассмотрим как поддерживать устаревшие рабочие нагрузки, например, виртуальные машины из OpenStack.
Основываясь на нашем понимании дизайна и реализации Cilium, мы ввели пользовательское расширение по сравнению с Cilium Endpoint модель:
Мы назвали его CiliumExternalResource (CER), чтобы отличить его от более позднего CiliumExternalWorkload (CEW).
CEW поставлялся с Cilium 1.9.x, а CER был развернут внутри компании с версии 1.8.x. Их сравнение будет подробно описано в следующем разделе.
Запись CER — это часть Метаданные с поддержкой ресничек, хранящиеся в KVStore (cilium-etcd), что соответствует одной устаревшей рабочей нагрузке , например, экземпляр виртуальной машины. Благодаря этому взлому каждый cilium-агент распознает эти устаревшие рабочие нагрузки. при выполнении входного контроля доступа для модулей Non-cilium-CN
Мы также предоставили API ( cer-apiserver), чтобы позволить устаревшим платформам или инструментам (например, OpenStack, система BM, Non-cilium-CNI) для загрузки своей рабочей нагрузки в Хранилище метаданных Cilium.
Обеспечивая синхронный вызов cer-apiserverкогда есть последующие операции с рабочей нагрузкой (такие как создание или удаление экземпляра ВМ), кластер Cilium сохраняет последние состояния устаревших рабочих нагрузок.
мы создаем плоскость данных, которая пересекает как облачную, так и устаревшую инфраструктуру, как показано ниже:

Гибридная плоскость данных за счет объединения CER и KVStoreMesh.
Теперь все проблемы с плоскостью данных решены, мы готовы построить плоскость управления.
Одна из наших целей — сделать плоскость управления достаточно общей, даже если базовая мода на применение политики однажды изменилась (например, CCNP прекратила свое существование), плоскость управления не претерпела бы никаких изменений (или как можно меньше). Таким образом, мы в конечном итоге абстрагировались от AccessControlPolicy модель, это дает много преимуществ:
AccessControlPolicy похож на АВС AccessPolicyи многие другие модели управления доступом на основе RBAC, все это концептуально управление доступом на основе ролей :
 Модель AccessControlPolicy
Модель AccessControlPolicy
Ниже показан пример, который позволяет приложению 888а и 999 получить доступ к кластеру Redis bobs-cluster:
Агностицизм плоскости управления требует адаптеры для преобразования ACP в определенные форматы Enforcer.
Другая часть плоскости управления толкает трансформированный трафик политике учитывающие уровень данных в кластеры Kubernetes.
Мы используем kubefed (v2) для достижения этой цели:
Теперь все технические опоры нашего храма безопасности завершены, т.к. пример — теперь вы можете создать ACP из файла yaml, и он будет автоматически преобразуется в FCCNP, затем преобразуется в CCNP и далее передается в отдельные кластеры Kubernetes — но только если вы можете получить доступ к kubefed и знать «сырой» yaml, модель ACP и т. д.
Реальные пользователи - разработчикам бизнес-приложений - нужен удобный интерфейс не заботясь обо всех фоновых концепциях и вещах, как это делаем мы, команды инфраструктуры.
Мы достигли цели, интегрировав возможность манипулирования политикой и authN/authZ встраиваются в нашу внутреннюю платформу непрерывной доставки, которая разработчики используют в повседневной работе.

Рабочий процесс запроса политики на стороне пользователя
Если авторизованный пользователь является владельцем приложения, он может отправить запрос с чем-то вроде этого:
Затем тикет будет отправлен на согласование нескольким лицам, на всех одобренных, платформа вызывает определенный API, чтобы добавить политику в плоскость управления.
Что касается представления существующих политик:

Предположим, у нас есть
Одним из первых моментов при оценке решения по обеспечению безопасности является пространство идентичности , или сколько идентификаторов безопасности поддерживает решение.
Cilium описывает свою концепцию идентичности в Documentation: Identity . Он имеет тождественное пространство 64K для одного кластера что происходит от его представления 16-битного идентификатора идентификатора :
Идентичности разных кластеров избегают перекрытия уникальным кластером cluster-idс.
Но что для нас значит 64K? Ознакомимся механизм распределения идентификаторов .
Короткий ответ заключается в том, что Cilium выделяет идентификаторы для структур с определенными метками безопасности : модули с одинаковыми группами меток имеют одинаковую идентичность.

Здесь возникает одна проблема для больших кластеров: список меток по умолчанию, используемый для получения тождества очень маленький, что приводит к назначению каждому компьютеру своих меток - например, если вы используете statefulsets, pod-name лейбл будет присвоен, и он уникален для каждого модуля, как показано ниже:
Хотя это не повредит окончательному применению политики (например, при указании app=cilium-smokeв CNP он будет охватывать все машины этого statefulset), это запрещает масштабирование кластера Kubernetes : 64K структуры будут верхней границей для каждого кластера, что неприемлемо для крупных компаний.
Эту проблему можно обойти, указав собственные метки, относящиеся к безопасности.
Например, если мы хотим
тогда мы могли бы настроить label-опцию cilium-agent:
С этой настройкой все структуры com.trip/appid=888 (и в том же кластер с той же учетной записью службы) будет иметь один и тот же идентификатор (другие две метки автоматически вставляются агентом Cilium)
С технической точки зрения одним из преимуществ решения на основе CNP является то, что весь процесс контроля доступа является прозрачен как для клиентов, так и для серверов , что означает, что никаких изменений клиент/сервер не требуется.
Но означает ли это также прозрачное развертывание в бизнес? Ответ - нет.
Чтобы быть конкретным, CNP — однократный переключатель :
Мы также хотели бы иметь некоторые удобные способы включения/выключения политик управления , вместо того, чтобы удалять/добавлять их каждый раз, когда есть новые подключения или обслуживание. Cilium поставляется с уровнем узла и уровнем конечной точки. настройка конфигурации режима аудита уровня через CLI,
что является хорошим началом, но еще недостаточно.
Во время расследования мы заметили что режим аудита политики на уровне CNP был предложен. Это правильный путь, но нет четкого графика (на самом деле не закончил до написания этого поста).
3.3.1 Режим аудита политик на уровне ресурсов
В качестве быстрого решения мы ввели аудит политик на уровне ресурсов. Режим, например, statefulset является ресурсом . При переключении режима аудита для statefulset в плоскости управления, это повлияет на все его модули. Мы намеренно сделали этот патч совместимым с сообществом, поэтому однажды мы могли бы отказаться от этого хака и перейти на уровень CNP.
Реализация:
Эта функция реализована как необязательная функция, поэтому мы можем включать/выключать ее с параметром конфигурации cilium-agent. При настройке его как выкл., cilium-agent вернется к поведению сообщества и просто проигнорирует метки.
Изменения в агенте были небольшими, так как мы повторно использовали код включения/выключения аудита на уровне конечной точки. Но нужна одна дополнительная конфигурация чтобы настройка режима аудита выдержала перезагрузку . Хорошей новостью является то, что cilium также обеспечивают эту конфигурацию. просто добавляю keep-config: trueв карту конфигурации агента.
Нормальный АКП должен быть [app list] -> specific-resource политика контроля входящего трафика, но есть это также [app list] -> *требование, например, некоторые инструменты управления должны получить доступ ко всем ресурсам. Поэтому нам нужна поддержка групповой политики или белого списка. В частности, мы поддерживаем два вида белых списков.
Пример, показанный ниже,
он будет преобразован в следующий FCCNP:
затем обрабатывается и передается в кластеры-члены как CCNP.
В настоящее время мы создаем белый список CIDR напрямую через FCCNP:
Наши настройки, среди которых некоторые непосредственно связаны с безопасностью, а некоторые для надежность (например, быть более устойчивым к отказам компонентов):


Учитывая все вышесказанное, вот наша стратегия развертывания:
Одной из ключевых подготовительных работ перед запуском чего-либо в производство является планы реагирования на системные сбои мы использовали cilium-compose для развертывания Cilium, и вот наша СОП пониженной версии:

Это решение развернуk в наших UAT и производственных средах. и проработал более полугода.
Версия некоторых компонентов:
4.1 Сравнение ClusterMesh и KVStoreMesh
ClusterMesh для больших кластеров имеет проблемы со стабильностью, что приводит к каскадным сбоям. Поведение подробно описанои здесь показан только типичный сценарий:

Ожидается, что по сравнению с последним, KVStoreMesh обеспечивает лучшую отказоустойчивость. изоляция, горизонтальная масштабируемость, а также гибкость развертывания и поддержки.
Эти три понятия очень похожи по названию, постараемся их немного пояснить.
CiliumEndpointэто Cilium CRD в Kubernetes:
ciliumexternalEndpoint представляет собой внутреннюю структуру, включающую в себя все конечные точки в удаленных кластерах в настройках ClusterMesh. Например, если кластер-1 и кластер-2 настроены как ClusterMesh, то все конечные точки в кластере-2 будут отображаться как externalEndpoint в cilium-agent кластера-1.
Мы считаем, что режим аудита на уровне CNP — правильный способ выполнить эту работу. Для сравнения, наш хак не является достойным решением, так как он включает в себя введение еще одного контроллера для согласования конкретных меток модулей. Если бы уровень CNP был завершен и готов к использованию в производстве в будущем, мы бы подумайте о том, чтобы принять это.
Еще одна важная вещь, касающаяся идентичности Cilium, о которой не говорилось: как определяется личность пакета когда пакет прибывает в точку применения политики? Ответ: это зависит от прямого режима маршрутизации , Cilium выделяет и синхронизирует удостоверения через KVStore, ниже приведена краткая временная последовательность, показывающая, как синхронизируется идентификация и применяется политика:

Картинка пытается проиллюстрировать как удостоверение клиентского модуля прибыло на Node2 до прибытие его пакетов . Теоретически, есть вероятность, что личность приходит после пакетов , что приведет к немедленному отказу.
Соответствующие стеки вызовов
Туннельный (VxLAN) режим встраивает личность в в tunnel_idполе (соответствует Поле VNI в заголовке VxLAN ) каждого отдельного пакета, поэтому вышеупомянутый сценарий отказа никогда не произойдет:
Также есть проблем отслеживание SPIFFE (Secure Production Identity Framework для Всем) поддержка в Cilium, которая восходит к 2018 году и продолжается до сих пор.
Возможно, самая удивительная часть сетевых политик на базе Cilium: включение CNP не замедлит работу - наоборот повысит производительность немного! Ниже приведен один из наших тестов:

где мы можем видеть, что после применения входного CCNP к серверному модулю его количество запросов в секунду увеличивается, а задержка уменьшается. Но почему? Код говорит правду. Если политика не применяется (по умолчанию), Cilium вставит политику по умолчанию, allow-all политика для каждого модуля:
И при поиске политики для входящего пакета вот соответствующая логика:
Соответствующий приоритет:
Событие создания удостоверения вызовет немедленную регенерацию BPF, но события удаления не будет, так как удаление личности по дизайну проходит через сборщик мусора.
Тогда мы можем задаться вопросом, что большинство модулей в кластере не должны иметь отношения к вновь созданному удостоверению, повторное создание всех модулей для каждого события удостоверения (создать/обновить/удалить) не было бы слишком расточительно (с точки зрения системных ресурсов такие как процессор, память и т. д.)?
Получается, что для неактуальных подов у cilium-agent есть логика «пропуска»:
Большинство стручков пойдет в else логика, которая также объясняет, почему время регенерации P99 резко уменьшается после исключения bpfLogProg:

Вы можете дважды подтвердить это поведение, просмотрев объектные файлы bpf в /var/run/cilium/state/<endpoint id>а также /var/run/cilium/state/<endpoint id>_next.
У нас есть еще технические вопросы, которые стоит обсудить, но давайте остановимся здесь, так как эта статья уже слишком длинная. Теперь давайте завершим это.
В этом посте рассказывается о нашем дизайне и реализации собственного облачного контроля доступа, решение для рабочих нагрузок Kubernetes (а также для устаревших рабочих нагрузок, если они действуют как клиенты). Решение в настоящее время используется для управления доступом L3/L4, и с более полученным опытом, мы расширим решение для большего количества вариантов использования. Мы хотели бы поблагодарить сообщество Cilium за их блестящую работу, и я лично хотел бы поблагодарить всех моих товарищей по команде и коллег за их замечательную работа над тем, чтобы сделать это возможным.
Перевод статьи https://arthurchiao.art/blog/trip-first-step-towards-cloud-native-security/#1-introduction
1.1 Контроль доступа в Kubernetes
В Kubernetes пользователи могут контролировать L3/L4(уровень IP/порта) потоки трафика приложений с NetworkPolicies.
А NetworkPolicy описывает как общаться различным сущностям на уровне OSI L3/L4, где «сущности» здесь могут быть идентифицированы комбинацией следующих 3 идентификаторов:
- Пространства имен , например модули из/в пространство имен default
- IP-блоки (CIDR) , например трафик из/в 192.168.1.0/24
- другие сущности, на пример app=client
Мы хотели бы, чтобы все сущности с тегом role=backend (сторона клиента) для доступа к сервису TCP/6379 всех сущностей с тэгом role=db(серверная сторона), а также другие клиенты, не входящие в эту спецификацию, должны быть отклонены. Ниже приведен минимальный NetworkPolicy для достижения цели (при условии, что клиентские и серверные модули в default пространстве имен):
Код с оформлением (BB-коды):
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: network-policy-allow-backend
spec:
podSelector: # Targets that this NetworkPolicy will be applied on
matchLabels:
role: db
ingress: # Apply on targets's ingress traffic
- from:
- podSelector: # Entities that are allowed to access the targets
matchLabels:
role: backend
ports: # Allowed proto+port
- protocol: TCP
port: 6379Хотя Kubernetes определяет NetworkPolicy, это оставляет реализацию на усмотрение каждому сетевому решению , это означает, что если вы не используете сетевое решение, поддерживающее NetworkPolicy, примененные вами политики не будут иметь никакого эффекта.
Дополнительные сведения о Kubernetes NetworkPolicy см. Сетевые политики
1.2 Реализация и расширение в Cilium
Cilium как сетевое решение Kubernetes реализует, а также расширяет стандартный Кубернет NetworkPolicy. Чтобы быть конкретным, он поддерживает три вида политик:
- NetworkPolicy: стандартная сеть Kubernetes, контроль L3/L4 трафика;
- CiliumNetworkPolicy(CNP): расширение стандартной Kubernetes NetworkPolicy, L3-L7 трафик;
- ClusterwideCiliumNetworkPolicy(CCNP): без пространства имен CCNP
Код:
apiVersion: "cilium.io/v2"
kind: CiliumNetworkPolicy
metadata:
name: "rule1"
spec:
description: "Allow HTTP GET /public from env=prod to app=service"
endpointSelector:
matchLabels:
app: service
ingress:
- fromEndpoints:
- matchLabels:
env: prod
toPorts:
- ports:
- port: "80"
protocol: TCP
rules:
http:
- method: "GET"
path: "/public"1.3 Проблемы крупных развертываний
Как показано выше, с помощью NetworkPolicy/CNP/CCNP можно обеспечить доступ L3-L7 элементам управления внутри кластера Kubernetes. Однако для крупных развертываний в реальные кластеры с работающими критически важными предприятиями, нужно гораздо больше информации, некоторую я представлю вам сейчас.- Как управлять политиками , и что такое интерфейс для конечных пользователей (разработчики, службы безопасности и т. д.)?
- Самым «ленивым» способом управления политиками может быть создание git-репозиторий и настроить политики через raw policy yam, но -
- Разработчики приложений в большинстве случаев не имеют доступа к Kubernetes инфраструктуры, как мы (команда инфраструктуры), поэтому мы не можем полагаться на них в манипуляциях необработанными файлами yaml, как мы.
- Как выполнять аутентификация и авторизация при манипулировании политикой?
Изучите 4A model (Учет, Аутентификация, Авторизация, Аудит).
- Как проверить (человека) пользователя (разработчика, администратора и т. д.)?
- Кто может запросить политику для какого ресурса (приложения, базы данных и т. д.)?
- Кто отвечает за утверждение/отклонение конкретного запроса политики?
- Аудит инфраструктуры, жизненно важный для решения безопасности.
- Как обрабатывать трансграничный доступ ? Например, прямое соединение между модулями, трафик между кластерами Kubernetes.
В идеальном мире все обращения к службам сходятся к границам кластера, и весь трансграничный трафик идет через шлюзы, такие шлюзы Kubernetes Egress/Ingress.
Но на самом деле у большинства компаний нет такой чистой инфраструктуры. Причины связаны со многими аспектами, такими как
- затраты (фактически включает дублирование всей инфраструктуры в каждом кластере)
- совместимость с устаревшими (технически устаревшими, но важными для бизнеса) инфраструктурами
Все эти вещи приводят к прямым кросс-кластерам трафика между модулями, которые по своей сути вовлекает нас в решение Kubernetes мультикластерных проблем.
4. Как управлять устаревшими рабочими нагрузками (например, VM/BM/non-cilium-pods)?
Для компаний, которые развивались более десяти лет, весьма вероятно, что существует не только прямой трансграничный трафик, но и устаревшие рабочие нагрузки, таких как виртуальные машины в OpenStack, системе BM или модулях Kubernetes на базе сетевые решения, отличных от Cilium.
Некоторые из них могут быть временными, например, миграция машин, не оснащенных non-cilium-pods в кластер на базе Cilium, но некоторые могут и не быть, типа ВМ все равно нельзя, заменены контейнерами в определенных сценариях.
Поэтому возникает естественный вопрос: как скрыть эти объекты в вашем решении для обеспечения безопасности?
5. Соображения производительности
Производительность должна быть одним из основных соображений для любого технического решения. С точки зрения решения безопасности мы должны позаботиться как минимум о:
- Производительность пересылки: приведет ли решение к серьезному снижению производительности?
- Время вступления политики в силу (задержка)
Будьте лучше знакомы со своей системой, чем ваши пользователи, вместо того, чтобы вас называли до последнего в полночь.
2. Контроль доступа: от требований к решению
Сейчас мы увидим, как мы разработали решение сначала до конца, отвечающее следующим требованиям:
- Контроль доступа к гибридным инфраструктурам
- Поддержка Kubernetes (main case) OpenStack, Baremetal и т. д.
- Поддержка локальных инфраструктур, а также инфраструктур в общедоступном облаке.
- Поддержка прямого межкластерного трафика
- Эволюционная архитектура
- Поддержка нескольких политик
- Поддержка контроля доступа L3-L7
- Высокая производительность
2.1 Применение политик в одном кластере
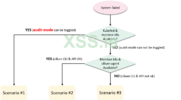
Начиная с самого простого случая, рассмотрим контроль доступа в автономный кластер Kubernetes на базе Cilium.
Как показано в логической архитектуре ниже, агент Cilium на каждом сервере Kubernetes рабочий узел слушает два хранилища ресурсов :
Кластер Kubernetes на базе Cilium
- API-сервер Kubernetes (до k8s-etcd): для просмотра CNP/CCNP
- KVStore (cilium-etcd): для просмотр идентификаторов струкур (и другие метаданные) всего кластера
В этой стандартной конфигурации с одним кластером собственного CNP/CCNP будет достаточно для применение политики, в том, что cilium-agent на каждом узле кэширует все активное идентификационное пространство кластера . Пока клиенты приходят из одного и того же кластера, каждый агент будет знать свой идентификатор безопасности, просматривая его локальный кеш, затем решите, куда направить трафик:
Применение политики Ingress внутри узла Cilium
Этапы обработки (включая применение политик) трафика в кластере Kubernetes на базе Cilium
2.2 Применение политики в нескольких кластерах
Теперь рассмотрим случай с несколькими кластерами.
Представьте, что модули серверов находятся в одном кластере, но клиентские модули разбросаны по нескольким кластерам , а клиенты обращаются к серверам напрямую (без шлюзов).
Лучшие практики Kubernetes предлагают избегать этой настройки, вместо этого всегда делайте межкластерный доступ через шлюзы. Но реальный мир, важный бизнес требования и/или технические недоделки часто проникают в архитектуру.
2.2.1 Кластерная сетка
Cilium поставляется со встроенным многокластерным решением под названием ClusterMesh. По сути, он настраивает каждый cilium-агент на прослушку KVStore других кластеров . Таким образом, каждый агент получает информацию об идентификаторе безопасности модулей в удаленных кластерах . Ниже представлен случай с двумя кластерами как с сеткой:
ClusterMesh: каждый cilium-агент также слушает KVStore других кластеров
Таким образом, при поступлении трафика от удаленных кластеров локальный агент может определить его контекст безопасности с локальной базой знаний:
Межкластерный контроль доступа с помощью Cilium ClusterMesh
2.2.2 KVStoreMesh
ClusterMesh как многокластерное решение является простым, но это имеет тенденцию быть уязвимым для большинства кластеров. Поэтому в итоге мы разработали собственное мультикластерное решение под названием KVStoreMesh. Он легкий и совместимый с исходящим трафиком потоком .
Короче говоря, вместо того, чтобы позволять каждому агенту извлекать удаленные удостоверения для всех удаленных KVStore мы разработали для этого оператор области кластера, который синхронизирует удаленные удостоверения KVStore локального кластера . Проще говоря, в каждом кластере Kubernetes мы запускаем kvstoremesh-operator, который
- Слушает изменения метаданных Cilium (например, идентификаторы безопасности) из KVStore Cilium всех других кластеров
- Запишите изменения в локальный Cilium KVStore
Двухкластерный: Настройка мультикластера с помощью KVStoreMesh
Настройка мультикластера с помощью KVStoreMesh (оператор kvstoremesh для краткости опущен)
Технически, с KVStoreMesh агенты получают удаленные удостоверения от своих локальный kvstore напрямую. Это гарантирует - только что как ClusterMesh, но без проблем со стабильностью и гибкостью. Сравнение ClusterMesh и KVStoreMesh будет подробно описано позже.
Превосходный дизайн Cilium заставляет вышеописанную идею работать большую часть времени, и мы исправили некоторые ошибки (большинство из которых уже находится на рассмотрении), чтобы остальные случаи также работали.
2.3 Применение политики к устаревшим клиентам
С помощью CNP/CCNP и KVStoreMesh мы решили задачи с одним и несколькими кластерами. Теперь давайте сделаем один шаг Кроме того, рассмотрим как поддерживать устаревшие рабочие нагрузки, например, виртуальные машины из OpenStack.
Обратите внимание, что наше техническое требование к устаревшей рабочей нагрузке здесь упрощено: мы рассматриваем только управление устаревшими рабочими нагрузками, когда они действуют как клиенты ; для тех, кто выступает в качестве серверов, мы считаем, что они выходят за рамки этого решение. Для нас это хорошая отправная точка.
2.3.1 CiliumExternalResource
Основываясь на нашем понимании дизайна и реализации Cilium, мы ввели пользовательское расширение по сравнению с Cilium Endpoint модель:
Код:
// pkg/endpoint/endpoint.go
// Endpoint represents a container or similar which can be individually
// addresses on L3 with its own IP addresses.
//
// The representation of the Endpoint which is serialized to disk for restore
// purposes is the serializableEndpoint type in this package.
type Endpoint struct {
...
IPv4 addressing.CiliumIPv4
SecurityIdentity *identity.Identity `json:"SecLabel"`
K8sPodName string
K8sNamespace string
...
}Мы назвали его CiliumExternalResource (CER), чтобы отличить его от более позднего CiliumExternalWorkload (CEW).
CEW поставлялся с Cilium 1.9.x, а CER был развернут внутри компании с версии 1.8.x. Их сравнение будет подробно описано в следующем разделе.
И причина, по которой мы не назвали это ExternalEndpoint это уже есть externalEndpointпонятие в Cilium, которое используется для совершенно других целей. Мы подробнее остановимся на этом позже.
Запись CER — это часть Метаданные с поддержкой ресничек, хранящиеся в KVStore (cilium-etcd), что соответствует одной устаревшей рабочей нагрузке , например, экземпляр виртуальной машины. Благодаря этому взлому каждый cilium-агент распознает эти устаревшие рабочие нагрузки. при выполнении входного контроля доступа для модулей Non-cilium-CN
2.3.2 cer-apiserver
Мы также предоставили API ( cer-apiserver), чтобы позволить устаревшим платформам или инструментам (например, OpenStack, система BM, Non-cilium-CNI) для загрузки своей рабочей нагрузки в Хранилище метаданных Cilium.
Обеспечивая синхронный вызов cer-apiserverкогда есть последующие операции с рабочей нагрузкой (такие как создание или удаление экземпляра ВМ), кластер Cilium сохраняет последние состояния устаревших рабочих нагрузок.
2.3.3 Подведение итогов: гибридная плоскость данных
- CER (подача метаданных внешних ресурсов в один кластер)
- KVStoreMesh (вытягивать метаданные ресурсов из всех остальных кластеров, в итоге метаданные во всех кластерах сходятся к одному и тому же),
мы создаем плоскость данных, которая пересекает как облачную, так и устаревшую инфраструктуру, как показано ниже:
Гибридная плоскость данных за счет объединения CER и KVStoreMesh.
Теперь все проблемы с плоскостью данных решены, мы готовы построить плоскость управления.
2.4 Панель управления
2.4.1 Моделирование политики управления доступом (ACP)
Одна из наших целей — сделать плоскость управления достаточно общей, даже если базовая мода на применение политики однажды изменилась (например, CCNP прекратила свое существование), плоскость управления не претерпела бы никаких изменений (или как можно меньше). Таким образом, мы в конечном итоге абстрагировались от AccessControlPolicy модель, это дает много преимуществ:
- Обеспечьте независимое развитие плоскостей управления и данных
- Возможность интеграции различных типов плоскостей данных в единый элемент управления плоскости, такие как CCNP на основе eBPF, Istio на основе mTLS AuthorizationPolicy, или даже некоторые методы на основе WireGuard в будущем.
AccessControlPolicy похож на АВС AccessPolicyи многие другие модели управления доступом на основе RBAC, все это концептуально управление доступом на основе ролей :
Некоторые удобные сопоставления, если вы не знакомы с терминами RBAC:
- Субъекты/Директора -> клиенты
- Ресурсы -> серверы
Ниже показан пример, который позволяет приложению 888а и 999 получить доступ к кластеру Redis bobs-cluster:
Код:
kind: AccessControlPolicy
spec:
statements:
- actions:
- redis:connect
effect: allow
resources:
- trnv1:rsc:trip-com:redis:clusters:bobs-cluster
subjects:
- trnv1:rsc:trip-com:iam:sa:app/888
- trnv1:rsc:trip-com:iam:sa:app/8892.4.2 Адаптеры Enforcer
Агностицизм плоскости управления требует адаптеры для преобразования ACP в определенные форматы Enforcer.
- Адаптер ACP->CCNP (основной вариант использования в настоящее время)
- Адаптер ACP->AuthorizationPolicy (вариант использования Istio, POC проверен)
2.4.3 Отправка (и согласование) политики в кластеры Kubernetes
Другая часть плоскости управления толкает трансформированный трафик политике учитывающие уровень данных в кластеры Kubernetes.
Мы используем kubefed (v2) для достижения этой цели:
- AccessControlPolicyреализован как CRD в kubefed
- acp2ccnp-adapter прослушивает ресурсы ACP и преобразует их в FCCNP (Federated CCNP)
- kubefed-controller-manager прослушивает ресурсы FCCNP, преобразует их в CCNP и подталкивает последний к указанным кластерам-членам kubernetes в спецификации FCCNP.
Теперь все технические опоры нашего храма безопасности завершены, т.к. пример — теперь вы можете создать ACP из файла yaml, и он будет автоматически преобразуется в FCCNP, затем преобразуется в CCNP и далее передается в отдельные кластеры Kubernetes — но только если вы можете получить доступ к kubefed и знать «сырой» yaml, модель ACP и т. д.
Реальные пользователи - разработчикам бизнес-приложений - нужен удобный интерфейс не заботясь обо всех фоновых концепциях и вещах, как это делаем мы, команды инфраструктуры.
2.4.4 Интеграция в платформу CD
Мы достигли цели, интегрировав возможность манипулирования политикой и authN/authZ встраиваются в нашу внутреннюю платформу непрерывной доставки, которая разработчики используют в повседневной работе.
AuthN и AuthZ здесь относятся к материалам проверки и предоставления привилегий. участвует во время запроса изменения политики (добавить/обновить/удалить) от пользователей.
Рабочий процесс запроса политики на стороне пользователя
Если авторизованный пользователь является владельцем приложения, он может отправить запрос с чем-то вроде этого:
Содержание: я владелец приложения <appid>, и я хотел бы получить доступ к вашему ресурс <resource identifier>( например, имя кластера Redis).
Причина: <some reason>.
Затем тикет будет отправлен на согласование нескольким лицам, на всех одобренных, платформа вызывает определенный API, чтобы добавить политику в плоскость управления.
Что касается представления существующих политик:
- Клиентский доступ
- Владелец клиентского приложения мог видеть, к каким ресурсам может получить доступ приложение;
- Владелец серверного приложения мог видеть, какие клиентские приложения могут получить доступ к этому ресурсу;
- Доступ администратора
2.4.5 Подведение итогов
Высокоуровневая архитектура управления
2.5 Типовой рабочий процесс
Предположим, у нас есть
- Клиентское приложение с меткой модуля appid=888(уникальный для каждого приложения), принадлежащий Алисе,
- База данных в памяти с меткой модуля redis-cluster=bobs-cluster(уникальный для каждой базы данных), принадлежащий Бобу,
- Алиса
- вход на платформу CD
- перейти к app 888 страница
- нажмите «Redis Access Request»,
- выберите bobs-cluster, Отправить запрос
- Запрос отправляется лицам из списка утверждения
- Запрос рассмотрен и одобрен
- Одобрено непосредственным руководителем Алисы
- Одобрено Бобом
- Утверждено службой безопасности (при необходимости)
- Платформа CD: вызываем API уровня управления, добавляем ACP в kubefed
- Добавлен ACP в kubefed
- Адаптер ACP->CCNP: при прослушивании добавленного ACP создает FCCNP
- kubefed-controller-manager: при прослушивании созданного FCCNP рендерит CCNP и отправляет в указанные кластеры Kubernetes (kube-apiserver)
- Все cilium-агенты во всех (покрытых CCNP) кластерах Kubernetes: на прослушивании при создании CCNP выполняет принудительное применение политики для модуля (если есть redis-cluster=bobs-clusterpod находится на узле). Применяется CCNP.
3 Внедрение в производство
3.1 Оценка пропускной способности
Одним из первых моментов при оценке решения по обеспечению безопасности является пространство идентичности , или сколько идентификаторов безопасности поддерживает решение.
3.1.1 Идентификационное пространство
Cilium описывает свою концепцию идентичности в Documentation: Identity . Он имеет тождественное пространство 64K для одного кластера что происходит от его представления 16-битного идентификатора идентификатора :
Код:
// pkg/identity/numericidentity.go
// NumericIdentity is the numeric representation of a security identity.
//
// Bits:
// 0-15: identity identifier
// 16-23: cluster identifier
// 24: LocalIdentityFlag: Indicates that the identity has a local scope
type NumericIdentity uint32Идентичности разных кластеров избегают перекрытия уникальным кластером cluster-idс.
Но что для нас значит 64K? Ознакомимся механизм распределения идентификаторов .
3.1.2 Механизм распределения идентификаторов
Короткий ответ заключается в том, что Cilium выделяет идентификаторы для структур с определенными метками безопасности : модули с одинаковыми группами меток имеют одинаковую идентичность.
Распределение удостоверений в Cilium из Cilium Doc
Здесь возникает одна проблема для больших кластеров: список меток по умолчанию, используемый для получения тождества очень маленький, что приводит к назначению каждому компьютеру своих меток - например, если вы используете statefulsets, pod-name лейбл будет присвоен, и он уникален для каждого модуля, как показано ниже:
Код:
$ cilium endpoint list
ENDPOINT IDENTITY LABELS (source:key[=value]) IPv4 STATUS
2362 322854 k8s:app=cilium-smoke 10.2.2.2 ready
k8s:io.cilium.k8s.policy.cluster=default
k8s:io.cilium.k8s.policy.serviceaccount=default
k8s:statefulset.kubernetes.io/pod-name=cilium-smoke-2
2363 288644 k8s:app=cilium-smoke 10.2.2.5 ready
k8s:io.cilium.k8s.policy.cluster=default
k8s:io.cilium.k8s.policy.serviceaccount=default
k8s:statefulset.kubernetes.io/pod-name=cilium-smoke-3Хотя это не повредит окончательному применению политики (например, при указании app=cilium-smokeв CNP он будет охватывать все машины этого statefulset), это запрещает масштабирование кластера Kubernetes : 64K структуры будут верхней границей для каждого кластера, что неприемлемо для крупных компаний.
Эту проблему можно обойти, указав собственные метки, относящиеся к безопасности.
3.1.3 Настройка меток, относящихся к безопасности
Например, если мы хотим
- Все структуры с одинаковым com.trip/appid=<appid> иметь одну и ту же личность
- Все структуры с одинаковым com.trip/redis-cluster-name=<name> разделять ту же идентичность
тогда мы могли бы настроить label-опцию cilium-agent:
Код:
reserved:.* k8s:!io.cilium.k8s.namespace.labels.* k8s:io.cilium.k8s.policy k8s:com.trip/appid k8s:com.trip/redis-cluster-nameС этой настройкой все структуры com.trip/appid=888 (и в том же кластер с той же учетной записью службы) будет иметь один и тот же идентификатор (другие две метки автоматически вставляются агентом Cilium)
Код:
$ cilium endpoint list
ENDPOINT IDENTITY LABELS (source:key[=value]) IPv4 STATUS
2113 322854 k8s:com.trip/appid=888 10.5.1.4 ready
k8s:io.cilium.k8s.policy.cluster=k8s-cluster-1
k8s:io.cilium.k8s.policy.serviceaccount=default
2114 322854 k8s:com.trip/appid=888 10.5.1.8 ready
k8s:io.cilium.k8s.policy.cluster=k8s-cluster-1
k8s:io.cilium.k8s.policy.serviceaccount=default3.2 Прозрачность бизнес - процессов
С технической точки зрения одним из преимуществ решения на основе CNP является то, что весь процесс контроля доступа является прозрачен как для клиентов, так и для серверов , что означает, что никаких изменений клиент/сервер не требуется.
Но означает ли это также прозрачное развертывание в бизнес? Ответ - нет.
Чтобы быть конкретным, CNP — однократный переключатель :
- Если политика не указана (по умолчанию), она действует как allow-any
- Если вы создали политику, например разрешающую appid=888 чтобы получить доступ к ресурсу, то все остальные клиенты, не входящие в эту политику, сразу получат отключение доступа, что может легко привести к сбоям в бизнесе, так как трудно получить accurate initial policy при этом не привлекая бизнес-пользователей если у вас есть только один шанс сделать это (применить политику).
3.3 Переключатель режима детального аудита политик
Мы также хотели бы иметь некоторые удобные способы включения/выключения политик управления , вместо того, чтобы удалять/добавлять их каждый раз, когда есть новые подключения или обслуживание. Cilium поставляется с уровнем узла и уровнем конечной точки. настройка конфигурации режима аудита уровня через CLI,
Код:
# Node-level
$ cilium config PolicyAuditMode=true
Код:
# Endpoint-level
$ cilium endpoint config <ep_id> PolicyAuditMode=trueчто является хорошим началом, но еще недостаточно.
Во время расследования мы заметили что режим аудита политики на уровне CNP был предложен. Это правильный путь, но нет четкого графика (на самом деле не закончил до написания этого поста).
3.3.1 Режим аудита политик на уровне ресурсов
В качестве быстрого решения мы ввели аудит политик на уровне ресурсов. Режим, например, statefulset является ресурсом . При переключении режима аудита для statefulset в плоскости управления, это повлияет на все его модули. Мы намеренно сделали этот патч совместимым с сообществом, поэтому однажды мы могли бы отказаться от этого хака и перейти на уровень CNP.
Реализация:
- Добавьте контроллер в kubefed для переключения режима аудита ресурса, по сути, это изменит конкретную метку на всех модулях ресурс, что-то вроде policy-audit-mode=true/false
- Отправка в кластеры Kubernetes с помощью kubefed-controller-managerтак же, как нажатие CCNP
- Взломанный cilium-agent для соблюдения метки модели аудита политик.
Эта функция реализована как необязательная функция, поэтому мы можем включать/выключать ее с параметром конфигурации cilium-agent. При настройке его как выкл., cilium-agent вернется к поведению сообщества и просто проигнорирует метки.
3.3.2 Пережить перезагрузку (сохранить конфигурацию)
Изменения в агенте были небольшими, так как мы повторно использовали код включения/выключения аудита на уровне конечной точки. Но нужна одна дополнительная конфигурация чтобы настройка режима аудита выдержала перезагрузку . Хорошей новостью является то, что cilium также обеспечивают эту конфигурацию. просто добавляю keep-config: trueв карту конфигурации агента.
3.4 Управление белым списком
Нормальный АКП должен быть [app list] -> specific-resource политика контроля входящего трафика, но есть это также [app list] -> *требование, например, некоторые инструменты управления должны получить доступ ко всем ресурсам. Поэтому нам нужна поддержка групповой политики или белого списка. В частности, мы поддерживаем два вида белых списков.
3.4.1 Белый список ACP
Пример, показанный ниже,
Код:
kind: AccessControlPolicy
metadata:
name: management-tool-whitelist
spec:
description: ""
statements:
- actions:
- credis:connect
effect: allow
resources:
- trnv1:rsc:trip-com:redis:clusters:*
subjects:
- trnv1:rsc:trip-com:iam:sa:app/858
- trnv1:rsc:trip-com:iam:sa:app/676он будет преобразован в следующий FCCNP:
Код:
apiVersion: types.kubefed.io/v1beta1
kind: FederatedCiliumClusterwideNetworkPolicy
metadata:
spec:
placement:
clusterSelector: {}
template:
metadata:
labels:
name: management-tool-whitelist
spec:
endpointSelector:
matchExpressions:
- key: k8s:com.trip/redis-cluster-name
operator: Exists
ingress:
- fromEndpoints:
- matchLabels:
k8s:com.trip/appid: "858"
- matchLabels:
k8s:com.trip/appid: "676"
toPorts:
- ports:
- port: "6379"
protocol: TCPзатем обрабатывается и передается в кластеры-члены как CCNP.
3.4.2 Белый список CIDR
В настоящее время мы создаем белый список CIDR напрямую через FCCNP:
Код:
apiVersion: types.kubefed.io/v1beta1
kind: FederatedCiliumClusterwideNetworkPolicy
metadata:
name: cidr-whitelist-1
spec:
placement:
clusterSelector: {} # Push to all member k8s clusters
template:
metadata:
labels:
name: cidr-whitelist-1
spec:
endpointSelector:
matchExpressions:
- key: k8s:com.trip/redis-cluster-name
operator: Exists
ingress:
- fromCIDR:
- 10.5.0.0/24
toPorts:
- ports:
- port: "6379"
protocol: TCP
- fromCIDR:
- 10.6.0.0/24
toPorts:
- ports:
- port: "6379"
protocol: TCP3.5 Пользовательские конфигурации
Наши настройки, среди которых некоторые непосредственно связаны с безопасностью, а некоторые для надежность (например, быть более устойчивым к отказам компонентов):
- allocator-list-timeout: 48h
- api-rate-limit: {"endpoint-create":"rate-limit:1000/s,rate-burst:256,auto-adjust:false,parallel-requests:256", "endpoint-delete":"rate-limit:1000/s,rate-burst:256,auto-adjust:false,parallel-requests:256", "endpoint-get":"rate-limit:1000/s,rate-burst:256,auto-adjust:false,parallel-requests:256", "endponit-patch":"rate-limit:1000/s,rate-burst:256,auto-adjust:false,parallel-requests:256", "endpoint-list":"rate-limit:10/s,rate-burst:10,auto-adjust:false,parallel-requests:10"}
- cluster-id: <unique id>
- cluster-name: <unique name>
- disable-cnp-status-updates: true
- enable-hubble: true
- k8s-sync-timeout: 600s
- keep-config: true
- kvstore-lease-ttl: 86400s
- kvstore-max-consecutive-quorum-errors: 5
- labels: <custom labels>
- log-driver: syslog
- log-opt: {"syslog.level":"info","syslog.facility":"local5"}
- masqurade: false
- monitor-aggregation: maximum
- monitor-aggregation-interval: 600s
- sockops-enable: true
- tunnel=disabled: прямая маршрутизация с BIRDкак агент BGP
3.6 Регистрация, мониторинг и оповещение
- Написал простенькую программу Hubble adapter for OpenTelemetry в Журнал аудита плоскости управления общего назначения в режиме реального времени
- Запуск в качестве «сайдкара» к каждому cilium агенту
- Подобно Hubble adapter for OpenTelemetry релиз в недавней Cilium v1.11
- Отправлять журналы аудита в ClickHouse, таким же образом мы агрегировали наши первоначальные политики для каждого ресурса.
- Визуализация с помощью внутренней инфраструктуры (на основе Kibana)
- Оповещение с внутренней инфраструктурой
Журнал аудита в нашем формате журнала аудита общего назначения
Некоторые общие сводки журналов аудита
3.7 Стратегия развертывания
Учитывая все вышесказанное, вот наша стратегия развертывания:
- Включить режим аудита политик : проверять все и отправлять журналы аудита центральная инфраструктура регистрации
- Определить первоначальную политику : запустить простую программу для агрегирования ACP для определенного ресурса из его журнала истории и применить ACP
- Уточнить начальную политику : обновить ACP, если effect=audit найдены обращения к ресурсу
- Опубликовать план контроля доступа : пусть разработчики приложение знают, что контроль доступа будет включен, а также процедуры запроса политики самопомощи, интегрированные в платформу CD
- Официально включить политику : отключить режим аудита политик для ресурс через переключатель уровня ресурса, и все новые клиентские приложения, которые хотели бы получить доступ на этот ресурс должны пройти процесс запроса тикета.
3.8 Даунгрейд при системных сбоях
Одной из ключевых подготовительных работ перед запуском чего-либо в производство является планы реагирования на системные сбои мы использовали cilium-compose для развертывания Cilium, и вот наша СОП пониженной версии:
Сценарии понижения версии при системных сбоях
Вкратце, когда происходят системные сбои, которые требуют от нас отключить контроль доступа , мы бы реагировали по трем основным сценариям:
- Кластер Kubefed и кластеры-члены Kubernetes готовы: мы можем отключить ACP путем переключения режима аудита политик на уровне ресурсов.
- Кластер Kubefed уже вышел из строя, но кластеры-участники Kubernetes готовы, мы можем:
- Отключите нашу функцию аудита на уровне ресурсов на cilium-agent, это вернет cilium-agent к поведению сообщества, а затем
- cilium config PolicyAuditMode=true чтобы открыть режим аудита для всех модулей на узле
Мы могли бы сделать это для одного узла или группы узлов с salt. - Кластер Kubefed и все кластеры Kubernetes-членов вышли из строя:
начала полностью отключите cilium-agent (чтобы он не согласовывал политики для конечных точек), затемиспользованием bpftoolчтобы напрямую написать необработанный all any правило для каждого модуля (конечной точки), команды, показанные ниже:Код:# Check if allow-any rule exists for a specific endpoint 3240 root@cilium-agent:/sys/fs/bpf/tc/globals# bpftool map lookup pinned cilium_policy_03240 key hex 00 00 00 00 00 00 00 00 key: 00 00 00 00 00 00 00 00 Not found # Insert an allow-any rule root@cilium-agent:/sys/fs/bpf/tc/globals# bpftool map update pinned cilium_policy_03240 key hex 00 00 00 00 00 00 00 00 value hex 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 noexist # Check again root@cilium-agent:/sys/fs/bpf/tc/globals# bpftool map lookup pinned cilium_policy_03240 key hex 00 00 00 00 00 00 00 00 key: 00 00 00 00 00 00 00 00 value: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 Запускаем команду bpftool в контейнере, созданном с образом cilium-agent чтобы избежать возможных проблем с несоответствием версий.
3.9 Среды и текущий статус развертывания
Это решение развернуk в наших UAT и производственных средах. и проработал более полугода.
Версия некоторых компонентов:
- cilium 1.9.5с пользовательскими исправлениями (sts с фиксированным IP-адресом и режим аудита на уровне ресурсов)
- Ядро: 4.14/4.19/5.10( 5%/80%/15%)
- 7 000+ cilium-узлов (серверы без ПО), пересекающие несколько кластеров Kubernetes.
- 170 тыс.+ cilium
- 40 000+ CER (BM/VM/модули без питания cilium )
- 4K+ CCNP (уменьшено с пикового 10K+с некоторой работой по агрегации политик)
- 800 тыс.+ потоков в минуту
- Правила L3/L4
- Селекторы ярлыков
- Селекторы CIDR
- Правила L7 (сделал только POC, написал плагин L7 для управления доступом на уровне приложений)
- Селекторы полных доменных имен
- Селекторы пространства имен
4 Обсуждения
4.1 Сравнение ClusterMesh и KVStoreMesh
ClusterMesh для больших кластеров имеет проблемы со стабильностью, что приводит к каскадным сбоям. Поведение подробно описанои здесь показан только типичный сценарий:
Распространение и усиление отказа в ClusterMesh
Следуя номерам шагов на картинке:
- kube-apiserver@cluster-1 терпит неудачу
- Все cilium-agents@cluster-1 терпят неудачу, так как не могут подключиться к kube-apiserver@cluster-1
- Все cilium-agents@cluster-1 начинают перезапускаться, и при запуске они подключатся к
- kube-apiserver@cluster-1
- kvstore@cluster-1
- kvstore@cluster-2
- kvstore@cluster-1 вниз, большие объемы одновременных операций LisWatch с тысяч узлов привели к его сбою (например, он выполнял резервное копирование, уже в состоянии высокого уровня ввода-вывода),
- Все cilium-agents@cluster-1и все cilium-agents@cluster-2 вниз, когда они соединяются с kvstore@cluster-1,
- Все cilium-agents@cluster-1и все cilium-agents@cluster-2 начинают перезапускаться, и аналогичным образом это оказывает значительное давление:
- kvstore@cluster-1
- kvstore@cluster-2
- kube-apiserver@cluster-2
- kvstore@cluster-2терпит неудачу
- Все cilium-agents@cluster-1и все cilium-agents@cluster-2 down
- Все cilium-agents@cluster-1и все cilium-agents@cluster-2 begin to restart
- kube-apiserver@cluster-2происходит сбой, так как он не может одновременно обслуживать ListWatch от тысяч агентов в кластере-2.
Ожидается, что по сравнению с последним, KVStoreMesh обеспечивает лучшую отказоустойчивость. изоляция, горизонтальная масштабируемость, а также гибкость развертывания и поддержки.
4.2 CER против CEW
4.2.1 Плюсы и минусы- CER ненавязчив и прозрачен для устаревших рабочих нагрузок. Нужен только синхронизировать метаданные рабочих нагрузок с кластером Cilium; CEW с другой стороны навязчива для устаревших систем, так как необходимо установить cilium-agent в каждую виртуальную машину со значительными изменениями.
- CER работает только тогда, когда устаревшие рабочие нагрузки действуют как клиенты на входе модулей Cilium. точка применения политики, в то время как CEW поддерживает собственную политику входящего/исходящего трафика.
4.2.2 CiliumEndpoint / CiliumEndpoint / externalEndpoint
Эти три понятия очень похожи по названию, постараемся их немного пояснить.
CiliumEndpoint является концептом, локальным для узла, и его данные сериализуются в локальный файл на узле:
Код:
// pkg/endpoint/endpoint.go
// Endpoint represents a container or similar which can be individually
// addresses on L3 with its own IP addresses.
//
// The representation of the Endpoint which is serialized to disk for restore
// purposes is the serializableEndpoint type in this package.
type Endpoint struct {
...
IPv4 addressing.CiliumIPv4
SecurityIdentity *identity.Identity `json:"SecLabel"`
K8sPodName string
K8sNamespace string
...
}
Код:
root@node-1 $ cilium endpoint list
ENDPOINT POLICY (ingress) POLICY (egress) IDENTITY LABELS (source:key[=value]) IPv4 STATUS
ENFORCEMENT ENFORCEMENT
139 Disabled Disabled 263455 k8s:io.cilium.k8s.policy.cluster=cluster-1 10.2.4.4 ready
k8s:io.cilium.k8s.policy.serviceaccount=default
k8s:io.kubernetes.pod.namespace=defaultCiliumEndpointэто Cilium CRD в Kubernetes:
Код:
root@master: $ k get pods cilium-smoke-0 -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
cilium-smoke-0 1/1 Running 2 10d 10.2.4.4 node-1 <none> <none>
root@master: $ k get ciliumendpoints.cilium.io cilium-smoke-0
NAME ENDPOINT ID IDENTITY ID INGRESS ENFORCEMENT EGRESS ENFORCEMENT VISIBILITY POLICY ENDPOINT STATE IPV4
cilium-smoke-0 139 263455 ready 10.2.4.4
root@master: $ k get ciliumendpoints.cilium.io cilium-smoke-0 -o yaml
apiVersion: cilium.io/v2
kind: CiliumEndpoint
metadata:
....
status:
external-identifiers:
container-id: 44c4bdb1f0533c6d7cef396
k8s-namespace: default
k8s-pod-name: cilium-smoke-0
pod-name: default/cilium-smoke-0
id: 139
identity:
id: 263455
labels:
- k8s:io.cilium.k8s.policy.cluster=cluster-1
- k8s:io.cilium.k8s.policy.serviceaccount=default
- k8s:io.kubernetes.pod.namespace=default
named-ports:
- name: cilium-smoke
port: 80
protocol: TCP
networking:
addressing:
- ipv4: 10.2.4.4
node: 10.6.6.6
state: readyciliumexternalEndpoint представляет собой внутреннюю структуру, включающую в себя все конечные точки в удаленных кластерах в настройках ClusterMesh. Например, если кластер-1 и кластер-2 настроены как ClusterMesh, то все конечные точки в кластере-2 будут отображаться как externalEndpoint в cilium-agent кластера-1.
Код:
// pkg/k8s/endpoints.go
// externalEndpoints is the collection of external endpoints in all remote
// clusters. The map key is the name of the remote cluster.
type externalEndpoints struct {
endpoints map[string]*Endpoints
}
// Endpoints is an abstraction for the Kubernetes endpoints object. Endpoints
// consists of a set of backend IPs in combination with a set of ports and
// protocols. The name of the backend ports must match the names of the
// frontend ports of the corresponding service.
type Endpoints struct {
// Backends is a map containing all backend IPs and ports. The key to
// the map is the backend IP in string form. The value defines the list
// of ports for that backend IP, plus an additional optional node name.
Backends map[string]*Backend
}4.3 Режим аудита политик на уровне ресурсов и на уровне CNP
Мы считаем, что режим аудита на уровне CNP — правильный способ выполнить эту работу. Для сравнения, наш хак не является достойным решением, так как он включает в себя введение еще одного контроллера для согласования конкретных меток модулей. Если бы уровень CNP был завершен и готов к использованию в производстве в будущем, мы бы подумайте о том, чтобы принять это.
4.4 Перенос идентификаторов: асинхронный, туннельный и SPIFFE
Еще одна важная вещь, касающаяся идентичности Cilium, о которой не говорилось: как определяется личность пакета когда пакет прибывает в точку применения политики? Ответ: это зависит от прямого режима маршрутизации , Cilium выделяет и синхронизирует удостоверения через KVStore, ниже приведена краткая временная последовательность, показывающая, как синхронизируется идентификация и применяется политика:
Распространение удостоверений во время масштабирования клиента Cilium
- Модули сервера находятся на узле Node2.
- Новый клиентский модуль создается на узле Node1.
Картинка пытается проиллюстрировать как удостоверение клиентского модуля прибыло на Node2 до прибытие его пакетов . Теоретически, есть вероятность, что личность приходит после пакетов , что приведет к немедленному отказу.
Соответствующие стеки вызовов
Код:
__section("from-netdev")
from_netdev
|-handle_netdev
|-validate_ethertype
|-do_netdev
|-identity = resolve_srcid_ipv4() // extract src identity
|-ctx_store_meta(CB_SRC_IDENTITY, identity) // save identity to ctx->cb[CB_SRC_IDENTITY]
|-ep_tail_call(ctx, CILIUM_CALL_IPV4_FROM_LXC) // tail call
|
|------------------------------
|
__section_tail(CILIUM_MAP_CALLS, CILIUM_CALL_IPV4_FROM_LXC)
tail_handle_ipv4_from_netdev
|-tail_handle_ipv4
|-handle_ipv4
|-ep = lookup_ip4_endpoint()
|-ipv4_local_delivery(ctx, ep)
|-tail_call_dynamic(ctx, &POLICY_CALL_MAP, ep->lxc_id);Туннельный (VxLAN) режим встраивает личность в в tunnel_idполе (соответствует Поле VNI в заголовке VxLAN ) каждого отдельного пакета, поэтому вышеупомянутый сценарий отказа никогда не произойдет:
Код:
handle_xgress // for packets leaving container
|-tail_handle_ipv4
|-encap_and_redirect_lxc
|-encap_and_redirect_lxc
|-__encap_with_nodeid(seclabel) // seclabel==identity
|-key.tunnel_id = seclabel
|-ctx_set_tunnel_key(&key)
|-skb_set_tunnel_key() // or call xdp_set_tunnel_key__stub()
|-bpf_skb_set_tunnel_key // kernel: net/core/filter.cТакже есть проблем отслеживание SPIFFE (Secure Production Identity Framework для Всем) поддержка в Cilium, которая восходит к 2018 году и продолжается до сих пор.
4.5 Вопросы производительности
Возможно, самая удивительная часть сетевых политик на базе Cilium: включение CNP не замедлит работу - наоборот повысит производительность немного! Ниже приведен один из наших тестов:
где мы можем видеть, что после применения входного CCNP к серверному модулю его количество запросов в секунду увеличивается, а задержка уменьшается. Но почему? Код говорит правду. Если политика не применяется (по умолчанию), Cilium вставит политику по умолчанию, allow-all политика для каждого модуля:
Код:
|-regenerateBPF // pkg/endpoint/bpf.go
|-runPreCompilationSteps // pkg/endpoint/bpf.go
| |-regeneratePolicy // pkg/endpoint/policy.go
| | |-UpdatePolicy // pkg/policy/distillery.go
| | | |-cache.updateSelectorPolicy // pkg/policy/distillery.go
| | | |-cip = cache.policies[identity.ID] // pkg/policy/distillery.go
| | | |-resolvePolicyLocked // -> pkg/policy/repository.go
| | |-e.selectorPolicy.Consume // pkg/policy/distillery.go
| | |-if !IngressPolicyEnabled || !EgressPolicyEnabled
| | | |-AllowAllIdentities(!IngressPolicyEnabled, !EgressPolicyEnabled)И при поиске политики для входящего пакета вот соответствующая логика:
Код:
__policy_can_access // bpf/lib/policy.h
|-if p = map_lookup_elem(l3l4_key); p // L3+L4 policy
| return TC_ACK_OK
|-if p = map_lookup_elem(l4only_key); p // L4-Only policy
| return TC_ACK_OK
|-if p = map_lookup_elem(l3only_key); p // L3-Only policy
| return TC_ACK_OK
|-if p = map_lookup_elem(allowall_key); p // Allow-all policy
| return TC_ACK_OK
|-return DROP_POLICY; // DROPСоответствующий приоритет:
- Политика L3+L4
- Политика только L4
- Политика только L3
- Разрешить все политики
- drop
4.6 Частые регенерации BPF
При создании модуля может быть выделена новая идентификация. При получении события создания удостоверения все Cilium агенты будут регенерировать BPF для всех модулей на узле, чтобы соблюдать личности, что является достаточно тяжелой операцией, так как составление и перезагрузка BPF только для одного модуля заняла бы несколько секунд.Событие создания удостоверения вызовет немедленную регенерацию BPF, но события удаления не будет, так как удаление личности по дизайну проходит через сборщик мусора.
Тогда мы можем задаться вопросом, что большинство модулей в кластере не должны иметь отношения к вновь созданному удостоверению, повторное создание всех модулей для каждого события удостоверения (создать/обновить/удалить) не было бы слишком расточительно (с точки зрения системных ресурсов такие как процессор, память и т. д.)?
Получается, что для неактуальных подов у cilium-agent есть логика «пропуска»:
Код:
// pkg/endpoint/bpf.go
if datapathRegenCtxt.regenerationLevel > regeneration.RegenerateWithoutDatapath {
// Compile and install BPF programs for this endpoint
if regenerationLevel == RegenerateWithDatapathRebuild {
e.owner.Datapath().Loader().CompileAndLoad()
Info("Regenerated endpoint BPF program")
compilationExecuted = true
} else if regenerationLevel == RegenerateWithDatapathRewrite {
e.owner.Datapath().Loader().CompileOrLoad()
Info("Rewrote endpoint BPF program")
compilationExecuted = true
} else { // RegenerateWithDatapathLoad
e.owner.Datapath().Loader().ReloadDatapath()
Info("Reloaded endpoint BPF program")
}
e.bpfHeaderfileHash = datapathRegenCtxt.bpfHeaderfilesHash
} else {
Debug("BPF header file unchanged, skipping BPF compilation and installation")
}Большинство стручков пойдет в else логика, которая также объясняет, почему время регенерации P99 резко уменьшается после исключения bpfLogProg:
Вы можете дважды подтвердить это поведение, просмотрев объектные файлы bpf в /var/run/cilium/state/<endpoint id>а также /var/run/cilium/state/<endpoint id>_next.
У нас есть еще технические вопросы, которые стоит обсудить, но давайте остановимся здесь, так как эта статья уже слишком длинная. Теперь давайте завершим это.
5 Заключение и дальнейшая работа
В этом посте рассказывается о нашем дизайне и реализации собственного облачного контроля доступа, решение для рабочих нагрузок Kubernetes (а также для устаревших рабочих нагрузок, если они действуют как клиенты). Решение в настоящее время используется для управления доступом L3/L4, и с более полученным опытом, мы расширим решение для большего количества вариантов использования. Мы хотели бы поблагодарить сообщество Cilium за их блестящую работу, и я лично хотел бы поблагодарить всех моих товарищей по команде и коллег за их замечательную работа над тем, чтобы сделать это возможным.
Перевод статьи https://arthurchiao.art/blog/trip-first-step-towards-cloud-native-security/#1-introduction