- Автор темы
- Добавить закладку
- #21
Прошу совета. Конвертирую в кронос авиабилеты 2019. Много трудностей с 40 млн записей, но вроде все проблемы удалось решить. Кроме одной. Внутри текста ряда полей есть запятые, которые путаются с запятыми, разделяющими поля. Из-за чего записи бьются и съезжают.
Три строки из исходного csv, проблемные запятые во второй строке:
PassengerDetailsID,PassengerID,ReservationID,Address1,Address2,City,County,Postcode,CountryName,Fax,Telephone,Email,EmergContact_Title,EmergContact_FirstName,EmergContact_SurName,EmergContact_Relationship,EmergContact_AreaCode,EmergContact_Telephone,IsSendSMS,BusinessContactNo
25400,46597,"OD1276468","130,Jalan Pulai Jaya 8,Bandar Pulai Jaya","","Johor Bahru","","81300","Malaysia","","","farahdyra@gmail.com","","","","","","",,
25401,46598,"OD1276469","292-f","","Kota bharu","","15200","Malaysia","","0134999880","b.show1293@gmail.com","","","","","","",,
Обычный LibreOffice умеет отличать запятые внутри поля от запятых-разделителей и видит все правильно:

EmEditor видит строки с ошибкой:

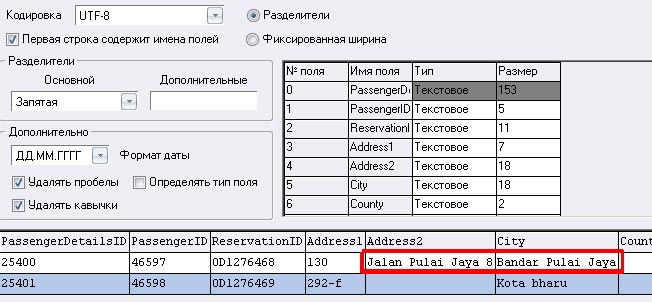
Cronos при конвертации видит с той же ошибкой, поля едут:
Это плохо, потому что часть имэйлов не попадают в поле email. В LibreOffice я не могу открыть файл на 7 гигабайт. Мне кажется, у EmEditor должна быть какая-то простая опция для таких случаев. Может кто-то подсказать решение?
Три строки из исходного csv, проблемные запятые во второй строке:
PassengerDetailsID,PassengerID,ReservationID,Address1,Address2,City,County,Postcode,CountryName,Fax,Telephone,Email,EmergContact_Title,EmergContact_FirstName,EmergContact_SurName,EmergContact_Relationship,EmergContact_AreaCode,EmergContact_Telephone,IsSendSMS,BusinessContactNo
25400,46597,"OD1276468","130,Jalan Pulai Jaya 8,Bandar Pulai Jaya","","Johor Bahru","","81300","Malaysia","","","farahdyra@gmail.com","","","","","","",,
25401,46598,"OD1276469","292-f","","Kota bharu","","15200","Malaysia","","0134999880","b.show1293@gmail.com","","","","","","",,
Обычный LibreOffice умеет отличать запятые внутри поля от запятых-разделителей и видит все правильно:
EmEditor видит строки с ошибкой:
Cronos при конвертации видит с той же ошибкой, поля едут:
Это плохо, потому что часть имэйлов не попадают в поле email. В LibreOffice я не могу открыть файл на 7 гигабайт. Мне кажется, у EmEditor должна быть какая-то простая опция для таких случаев. Может кто-то подсказать решение?
Последнее редактирование:

")
