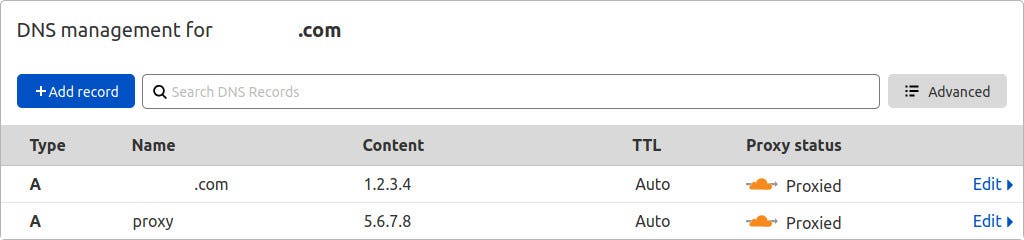
Python:
from requests_html import HTMLSession
session = HTMLSession()
session.proxies = { 'http': 'socks5h://<proxy>', 'https': 'socks5h://<proxy>' }
session.headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:63.0) Gecko/20100101 Firefox/63.0' }
request = session.get(<url>)
session.close()
request.html.render() # драйвер для JS
request.html.html #Получаем контент)
Последнее редактирование:

")