Предисловие.
Целью данной статьи является не создание простого универсального кода для любой Captch'и, а прежде всего для объяснения и разбора многих алгоритмов и библиотек, которые в дальнейшем будут использованы для декодировании нашего текста.
В чём же проблема декодирования Captcha.
Данные картинки или другие виде тестов, например: математическая, аудио, текстовая или любая капча, построена таким образом, что машина не может её легко распознать, но из за чего же это происходит. Всё просто! На картинку данную нам добавлены различные шумы, зернистость, да и сами изображения небинарные (Цветные проще говоря). Но как мы знаем - прогресс не стоит на месте, всё в мире эволюционирует и это необратимый процесс и вскоре некоторые виды этих тестов всё же сумел распознать машины.
Приступаем!
Наш код будет состоять из двух частей и ещё паре побочных (Необязательных). Первое, что мы сделаем - распознаем какого цвета наш текст, который нам придётся "отделить от изображения", далее сам процесс разделения и определение текста с готовой картинке.
Для начала предлагаю взять три картинки разной сложности, длины слов и прочего и определить текст двумя способами.
Captcha_1

Captcha_2
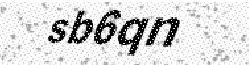
Captcha_3

Что же за два метода определения цвета текста капчи?
Можно использовать сторонние программы (Например ColorMania, ColorPicker) или использую гистограмму. Гистограмма - способ представления изображения в виде графика с соотношениям частот и их количеством.
А вот и первый код с помощью которого мы будем выводит гистограмму изображения.
И-ии-и вывод:
Но рассказывать как их читать я конечно не буду и не умею, но знать про эту функцию интересно. Зато могу рассказать о том, как работает функция .histogram. Через запятую у нас частота использования определённого пикселя на изображении, напоминаю, в формате png может содержатся только 255 значений каждого спектра (RGB - Red - Красный, Green - Зелёный, Blue - Голубой).
Далее - удаляем ненужные цвета с изображения.
К примеру у нас на изображении текст фиолетового цвета как показано на captcha_1. После небольших манипуляции я обнаружил, что самый тёмный фиолетовый пиксель - 140, 0, 116, а самый светлый - 122, 36, 94. Из этих данных можно составить такой алгоритм: если пиксель более тёмный чем 140, 0, 116, то его значение будет равно 255, 255, 255 (Белый цвет) и если пиксель светлее 122, 36, 94, то его значение будет равно 255, 255, 255.
Вот и сам код:
Вот изображение, которое у нас получилось:

Как мы видим - у нас остались полосы на тексте после шумов, которые мы удалили и у нас остались некоторые части зелёного фона. Видимо он находился в диапазоне между 140, 0, 116 и 122, 36, 94. Но по непонятной мне причине этот фон никак не удалялся.
Давайте без лишних слов я проведаю те же самые махинации и с другими двумя изображениями.
Вывод:
Ну а третья наша картинка слишком лёгкая, она была создана для того, чтобы пропустить этот шаг и сразу перейти к следующему")
Дальше всё просто. Нам нужно использовать библиотеку pytesseract, которая декодирует уже облегчённый текст. В нашем случае мы будем использовать функцию image_to_string.
Но Pytesseract отнюдь не самая простая в использовании библиотека. Для начала вам требуется установить tesseract-orc и потом установить pytesseract с помощью pip.
И далее всё довольно просто:
Было:
Стало:
Так как мы ранее загрузили pytesseract-orc, то во время исполнения нашего кода будет работать целая нейросеть, которую обучали с помощью целой базы из таких картинок. И именно из за этого она работает так хорошо! О нейросетях и о том как они работают советую почитать отдельно, а уже к этому времени мы заканчиваем нашу статью. Если же её укоротить, то можно уместить в два простых шага - удаление лишних пикселей изображения и использование pytesseract, которые можно соединить в один небольшой код.
Послесловие.
Огромное вам спасибо за прочтение данной статьи. Я ещё очень юн в написании авторских статей. Я бы с радостью принял вашу критику. Очень жаль, что я опоздал на конкурс статей, но главное, чтобы кого то вдохновили или даже обучили чему то по моим статьям.
Спасибо!
Целью данной статьи является не создание простого универсального кода для любой Captch'и, а прежде всего для объяснения и разбора многих алгоритмов и библиотек, которые в дальнейшем будут использованы для декодировании нашего текста.
В чём же проблема декодирования Captcha.
Данные картинки или другие виде тестов, например: математическая, аудио, текстовая или любая капча, построена таким образом, что машина не может её легко распознать, но из за чего же это происходит. Всё просто! На картинку данную нам добавлены различные шумы, зернистость, да и сами изображения небинарные (Цветные проще говоря). Но как мы знаем - прогресс не стоит на месте, всё в мире эволюционирует и это необратимый процесс и вскоре некоторые виды этих тестов всё же сумел распознать машины.
Приступаем!
Наш код будет состоять из двух частей и ещё паре побочных (Необязательных). Первое, что мы сделаем - распознаем какого цвета наш текст, который нам придётся "отделить от изображения", далее сам процесс разделения и определение текста с готовой картинке.
Для начала предлагаю взять три картинки разной сложности, длины слов и прочего и определить текст двумя способами.
Captcha_1
Captcha_2
Captcha_3
Что же за два метода определения цвета текста капчи?
Можно использовать сторонние программы (Например ColorMania, ColorPicker) или использую гистограмму. Гистограмма - способ представления изображения в виде графика с соотношениям частот и их количеством.
А вот и первый код с помощью которого мы будем выводит гистограмму изображения.
Код:
#Для начала импортируем библиотеку для работы с изображениями - PIL (Python Image Library)
from PIL import Image
#При помощи функции библиотеки Pillow открываем наше изображения для дальнейшей работы с ним.
picture = Image.open("captcha.png")
picture = picture.convert("P")
#И конечно же выводим гистограмму этого изображения
print(picture.histogram())И-ии-и вывод:
Код:
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 77, 4, 0, 0, 0, 0, 77, 5, 0, 0, 1, 619, 487, 0, 0, 0, 0, 142, 186, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,0, 139, 6, 0, 0, 1, 15, 445, 29, 0, 0, 381, 2605, 4324, 192, 0, 0, 2, 736, 5057, 5930, 27, 0, 0, 0, 3, 567, 738, 0, 0, 0, 0, 0, 0, 0, 56, 1, 358, 1257,0, 0, 56, 13, 482, 177, 5, 79, 2, 67, 233, 245, 17, 112, 0, 58, 870, 4616, 122, 0, 0, 0, 40, 1944, 20, 0, 0, 0, 0, 0, 0, 0, 151, 1, 86, 316, 0, 0, 151,1, 2, 10, 5, 64, 132, 179, 0, 259, 14, 174, 2, 11, 0, 16, 1, 0, 0, 0, 0, 0,0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 54, 69, 0, 0, 0, 0, 2, 3, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]Но рассказывать как их читать я конечно не буду и не умею, но знать про эту функцию интересно. Зато могу рассказать о том, как работает функция .histogram. Через запятую у нас частота использования определённого пикселя на изображении, напоминаю, в формате png может содержатся только 255 значений каждого спектра (RGB - Red - Красный, Green - Зелёный, Blue - Голубой).
Далее - удаляем ненужные цвета с изображения.
К примеру у нас на изображении текст фиолетового цвета как показано на captcha_1. После небольших манипуляции я обнаружил, что самый тёмный фиолетовый пиксель - 140, 0, 116, а самый светлый - 122, 36, 94. Из этих данных можно составить такой алгоритм: если пиксель более тёмный чем 140, 0, 116, то его значение будет равно 255, 255, 255 (Белый цвет) и если пиксель светлее 122, 36, 94, то его значение будет равно 255, 255, 255.
Вот и сам код:
Код:
#Импортируем библиотеку PIL (Python Image Library)
from PIL import Image
#Открываем изображение для дальнейшей работы с ним.
picture = Image.open("captcha.png")
#Придаём RGB значения некоторым цветам.
dark_purple = (140, 0, 116)
light_purple = (122, 36, 94)
white = (255, 255, 255)
#Указываем нашему коду на то, что размер нашего полотна равен соотношению его ширины (width) на его длину (height)
width, height = picture.size
#Начинаем работу с нашим полотном при помощи for
for x in range(width):
for y in range(height):
#если изображение темнее самого тёмного и светлее самого светлого фиолетового, то...
if picture.getpixel( (x,y) ) > dark_purple or picture.getpixel( (x,y) ) < light_purple:
#Они преобразуются из своего изначального в белый (255, 255, 255)
picture.putpixel( (x,y), white)
#И сохраняем наше изображение
picture.save("output_picture.png")Вот изображение, которое у нас получилось:
Как мы видим - у нас остались полосы на тексте после шумов, которые мы удалили и у нас остались некоторые части зелёного фона. Видимо он находился в диапазоне между 140, 0, 116 и 122, 36, 94. Но по непонятной мне причине этот фон никак не удалялся.
Давайте без лишних слов я проведаю те же самые махинации и с другими двумя изображениями.
Код:
from PIL import Image
picture = Image.open("captcha1.png")
black = (0, 0, 0)
gray = (40, 40, 40)
white = (255, 255, 255)
width, height = picture.size
for x in range(width):
for y in range(height):
if picture.getpixel( (x,y) ) < black or picture.getpixel( (x,y) ) > gray:
picture.putpixel( (x,y), white)
picture.save("output_picture1.png")Вывод:
Ну а третья наша картинка слишком лёгкая, она была создана для того, чтобы пропустить этот шаг и сразу перейти к следующему
Дальше всё просто. Нам нужно использовать библиотеку pytesseract, которая декодирует уже облегчённый текст. В нашем случае мы будем использовать функцию image_to_string.
Но Pytesseract отнюдь не самая простая в использовании библиотека. Для начала вам требуется установить tesseract-orc и потом установить pytesseract с помощью pip.
И далее всё довольно просто:
Код:
#Импортируем ранее использованную библиотеку PIL (Напомню, Python Image Library)
from PIL import Image
#И таким же образом импортируем функцию image_to_string из pytesseract
from pytesseract import image_to_string
#Задаём переменной image значение, которое открывает наше изображение.
image = Image.open("Output_picture1.jpg")
#И выводим его (Советую для точности на всякий случай указать, что текст на английском языке при помощи графы lang.
print(image_to_string(image, lang='eng'))Было:
Стало:
Код:
sb6qnТак как мы ранее загрузили pytesseract-orc, то во время исполнения нашего кода будет работать целая нейросеть, которую обучали с помощью целой базы из таких картинок. И именно из за этого она работает так хорошо! О нейросетях и о том как они работают советую почитать отдельно, а уже к этому времени мы заканчиваем нашу статью. Если же её укоротить, то можно уместить в два простых шага - удаление лишних пикселей изображения и использование pytesseract, которые можно соединить в один небольшой код.
Послесловие.
Огромное вам спасибо за прочтение данной статьи. Я ещё очень юн в написании авторских статей. Я бы с радостью принял вашу критику. Очень жаль, что я опоздал на конкурс статей, но главное, чтобы кого то вдохновили или даже обучили чему то по моим статьям.
Спасибо!