
В первой части мы успешно проинспектировали легаси ендпоинты - https://xss.pro/threads/143649/
Отсортировав их получается список целей которые теперь нас интересуют с т.з. получения внутренней информации или маппинга API.
Поскольку часто swagger и openapi доки скрыты за логином мы будем искать подсказки где находится то что нам надо.
Содержание
- Список кандидатов
- TLS реверс
- Апгрейд словаря
- Парсинг значений ендпоинт директорий
- DevTools и поиск apibase
- Анализ данных для эксплуатации
Предыдущая статья содержала в конце целевой список url кандидатов.
В этой хочется расширить список ендпоинтов и потому будем добавлять вариации.
Проявляем изобретательность и копаем глубже.
Сначала зададим для команд наш файл с уже найдеными wayback директориям-
Bash:
FILE=/home/kali/candidates/ffuf_hits.txtContent-Type-
Bash:
while read -r u; do
echo -n "$u , "
curl -skI -L --max-redirs 3 -m 8 "$u" | awk 'BEGIN{sc="000";ct="";} /HTTP/{if($2) sc=$2} /Content-Type/ {ct=$2} END{print sc" , "ct}'
done < "$FILE" > /home/kali/report.txtПродолжим работу с этим списком.
TLS реверс
Поскольку ответы пришли ‘000’ то стоит проверить в целом валидность найденного енжпоинта swagger / openapi-
Bash:
curl -vkI https://hub.param.com.tr/api/openapi.jsonСохраняем swaggerui.html для поиска оставленных линков или хедеров-
Bash:
curl -k -sL 'https://hub.param.com.tr/api/swagger-ui' -o /home/kali/swaggerui.html
Bash:
egrep -o 'https?://[^"'"'"' >]*?(openapi|swagger|api-docs|openapi.json|swagger.json)[^"'"'"' >]*' /home/kali/swaggerui.html | sort -u
Bash:
grep -E '"(get|post|put|delete)"' swaggerui.html | head -n 20
Bash:
grep -oP '{[^}]*"openapi"[^}]*}' swaggerui.htmlТеперь стоит на основании уже имеющегося списка сделать шаг в сторону добавления параметров для фаззинга в словарь apiwl.txt из первой части-
Bash:
cat <<'EOF' > /home/kali/apiwl2.txt
openapi.json
swagger.json
openapi.yaml
swagger.yaml
api-docs
v2/api-docs
swagger-ui
docs
redoc
openapi/v1.json
r.php/api/openapi.json
r.php/api-docs
EOF
Bash:
mkdir -p /home/kali/ffufout2Используем fuff для фаззинга с дополненным словарем и используем список субдоменов цели-
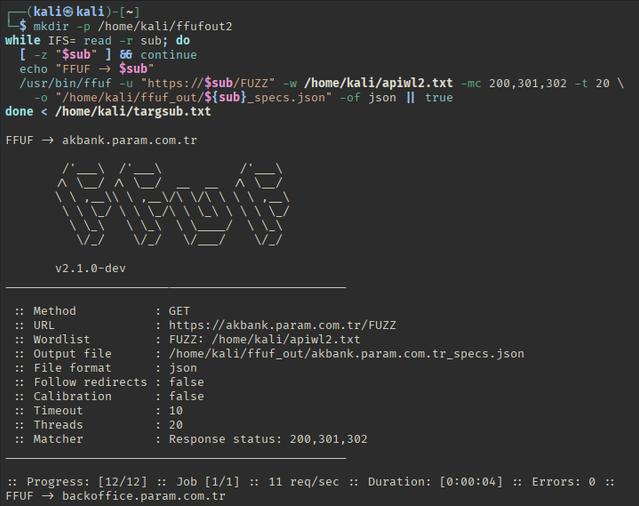
Bash:
while IFS= read -r sub; do
[ -z "$sub" ] && continue
echo "FFUF -> $sub"
/usr/bin/ffuf -u "https://$sub/FUZZ" -w /home/kali/apiwl2.txt -mc 200,301,302 -t 20 \
-o "/home/kali/ffuf_out/${sub}_specs.json" -of json || true
done < /home/kali/targsub.txtПо резульатам фаззинга выделились 3 субдомена
akbank.param.com.tr;
hub.param.com.tr;
isube.param.com.tr;
Особенно приглянулся домен hub.param.com.tr т.к. именно он ответил статусом ‘200’ с интересующими нас параметрами директорий и файлов-
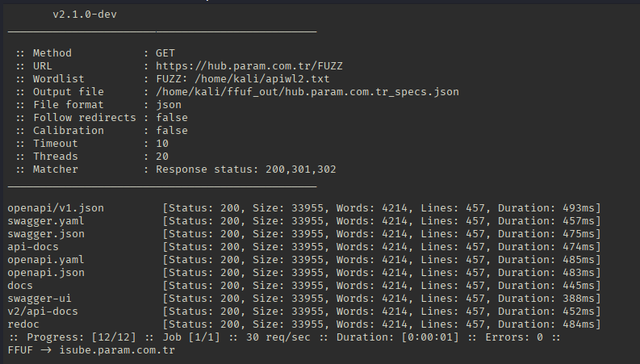
JSON:
openapi/v1.json [Status: 200, Size: 33955, Words: 4214, Lines: 457, Duration: 493ms]
swagger.yaml [Status: 200, Size: 33955, Words: 4214, Lines: 457, Duration: 457ms]
swagger.json [Status: 200, Size: 33955, Words: 4214, Lines: 457, Duration: 475ms]
api-docs [Status: 200, Size: 33955, Words: 4214, Lines: 457, Duration: 474ms]
openapi.yaml [Status: 200, Size: 33955, Words: 4214, Lines: 457, Duration: 485ms]
openapi.json [Status: 200, Size: 33955, Words: 4214, Lines: 457, Duration: 483ms]
docs [Status: 200, Size: 33955, Words: 4214, Lines: 457, Duration: 445ms]
swagger-ui [Status: 200, Size: 33955, Words: 4214, Lines: 457, Duration: 388ms]
v2/api-docs [Status: 200, Size: 33955, Words: 4214, Lines: 457, Duration: 452ms]
redoc [Status: 200, Size: 33955, Words: 4214, Lines: 457, Duration: 484ms]Парсинг ендпоинт директорий
Используем подобный скрипт-
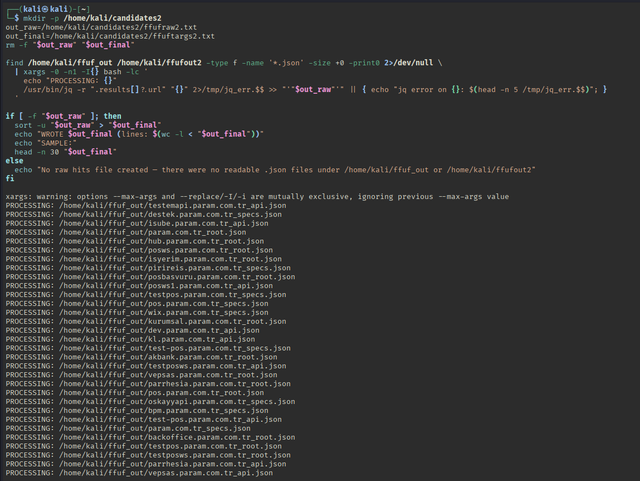
Bash:
mkdir -p /home/kali/candidates2
out_raw=/home/kali/candidates2/ffufraw2.txt
out_final=/home/kali/candidates2/ffuftargs2.txt
rm -f "$out_raw" "$out_final"
find /home/kali/ffuf_out /home/kali/ffufout2 -type f -name '*.json' -size +0 -print0 2>/dev/null \
| xargs -0 -n1 -I{} bash -lc '
echo "PROCESSING: {}"
/usr/bin/jq -r ".results[]?.url" "{}" 2>/tmp/jq_err.$$ >> "'"$out_raw"'" || { echo "jq error on {}: $(head -n 5 /tmp/jq_err.$$)"; }
'
if [ -f "$out_raw" ]; then
sort -u "$out_raw" > "$out_final"
echo "WROTE $out_final (lines: $(wc -l < "$out_final"))"
echo "SAMPLE:"
head -n 30 "$out_final"
else
echo "No raw hits file created — there were no readable .json files under /home/kali/ffuf_out or /home/kali/ffufout2"
fi- Мы создаем директорию для нового списка кандидатов для дедупликации
- Парсим все .json которые имеют значения внутри
- Экспортируем urls через jq
- Сохраняет raw xargs если таковые найдены
- Выдает значение ошибки если не было найдено raw params
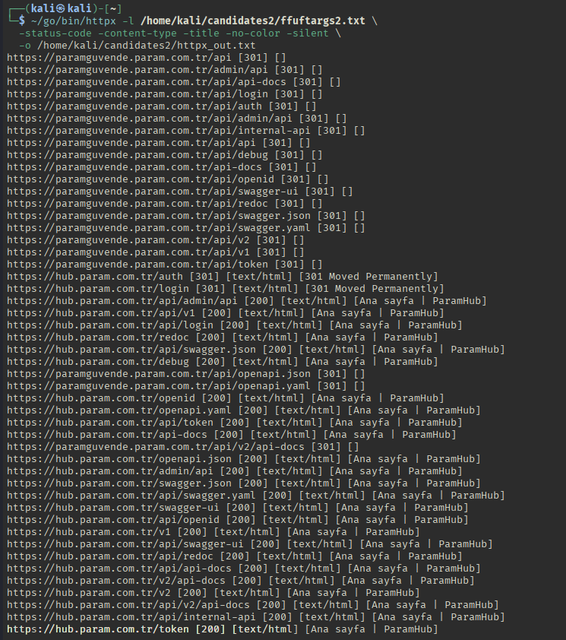
Bash:
~/go/bin/httpx -l /home/kali/candidates2/ffuftargs2.txt \ -status-code -content-type -title -no-color -silent \ -o /home/kali/candidates2/httpx_out.txt
Bash:
while read -r u; do
echo -n "$u -> "
ctype=$(curl -k -s -o /dev/null -D - "$u" | grep -i '^content-type:')
echo "$ctype"
done < /home/kali/candidates2/ffuftargs2.txtТеперь маленький лайвхак - сохраним swagger-ui страницу в формате .html-

Bash:
curl -k -sS -o /tmp/swag_full.html https://hub.param.com.tr/swagger-ui head -n 200 /tmp/swag_full.html > swagg,html
Bash:
grep -oE 'https?://[^"'"'"']+\.js' swagg.html | sort -u
Bash:
for j in $(grep -oE 'https?://[^"'"'"' >]+\.js' swagg.html | sort -u); do
curl -k -sS "$j" \
| egrep -i 'openapi|swagger|/api/|token|auth' \
| sed -n '1,120p'
doneВсе это можно сохранить в отдельный файл > jslist.txt и получить файлы или аргументы-

Bash:
cat jslist.txt | xargs -n1 -P8 -I% bash -c '
echo "=== % ===";
curl -k -sS --max-time 10 --range 0-8191 "%" 2>/dev/null | sed -n "1,160p" | egrep -i --color=auto "openapi|swagger|/api/|token|auth" || echo "(no hits in first 8KB)";
'DevTools стоит использовать в процессе реверса флоу.
Логирование шагов в итоге даст еще ключи для поиска или вовсе полезные;критические данные.
Открывем https://hub.param.com.tr/ и нажимаем f12-
Вкладка
Network - Preserve log - Fetch / XHR - обновляем страницу.Поскольку страница защищена логином то рассмотрим гоствеой неавторизированный лог подробнее сохранив .har файл-
По запросам мы уже увидели AJAX.
Кроме этого каждый запрос к серверу по типу https://hub.param.com.tr/lib/ajax/service.php?sesskey=<...>&info=core_site_get_site_info
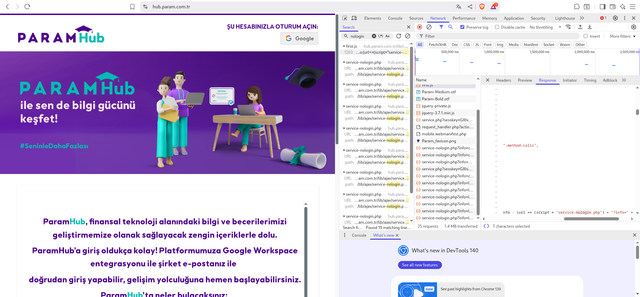
возвращает интересный JSON blob d виде m.cfg-
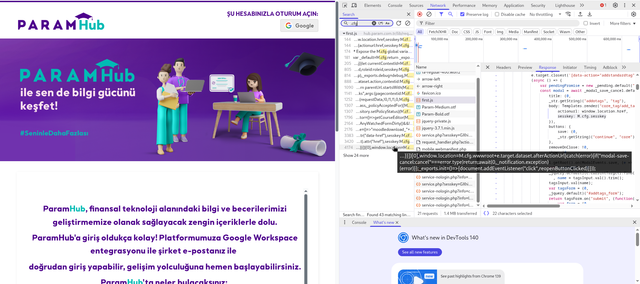
Дополниельно еще получаем там же указания на значения sesskey&apibase ответов.
Поскольку он такой не один это интересные параметры для разведки.
Добавив в список параметров снова проинспектируем .html-

Bash:
sed -n '1,400p' swagg.html | egrep -i 'apibase|M.cfg|sesskey|r.php|openapi|swagger|api-docs|/r.php/api' -n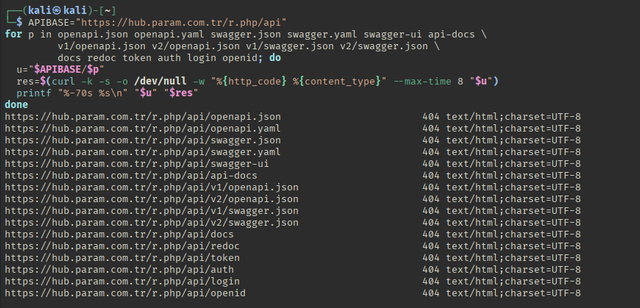
Bash:
APIBASE="https://hub.param.com.tr/r.php/api"
for p in openapi.json openapi.yaml swagger.json swagger.yaml swagger-ui api-docs \
v1/openapi.json v2/openapi.json v1/swagger.json v2/swagger.json \
docs redoc token auth login openid; do
u="$APIBASE/$p"
res=$(curl -k -s -o /dev/null -w "%{http_code} %{content_type}" --max-time 8 "$u")
printf "%-70s %s\n" "$u" "$res"
doneПоэтому проапгрейдим пайплайн для более широкого поиска и выгрузке при нахождении подходязих страниц .json;.yaml-
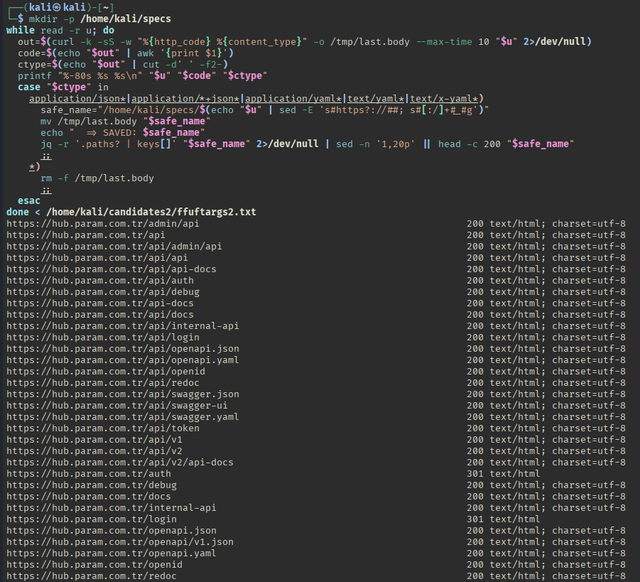
Bash:
mkdir -p /home/kali/specs
while read -r u; do
out=$(curl -k -sS -w "%{http_code} %{content_type}" -o /tmp/last.body --max-time 10 "$u" 2>/dev/null)
code=$(echo "$out" | awk '{print $1}')
ctype=$(echo "$out" | cut -d' ' -f2-)
printf "%-80s %s %s\n" "$u" "$code" "$ctype"
case "$ctype" in
application/json*|application/*+json*|application/yaml*|text/yaml*|text/x-yaml*)
safe_name="/home/kali/specs/$(echo "$u" | sed -E 's#https?://##; s#[:/]+#_#g')"
mv /tmp/last.body "$safe_name"
echo " => SAVED: $safe_name"
jq -r '.paths? | keys[]' "$safe_name" 2>/dev/null | sed -n '1,20p' || head -c 200 "$safe_name"
;;
*)
rm -f /tmp/last.body
;;
esac
done < /home/kali/candidates2/ffuftargs2.txtИтого еще в .har файле мы получили 11 bodie ответов.
Проанализировав их на application/json MIME мы можем найти довольно интересные пункты.
Самые внимательные заметили Moodle который указывает на обработку запросов AJAX-
Внутри них мы видим что сервер отдает нам json ответы которые содержат ендпоинты
service.php; service-nologin.php; sesskey=... прямо в url.До них доходят запросы и они записываются в браузер сессии.
Потенциально это значит что используя curl вполне можно дотянуться до спецификаций используя подставные значения в url без браузера или др. UI.
Сегодня мы лишь ищем api и потому не будет шалить и хулиганить подтверждая историю с подставными значенниями в url.
Ведь мы пришли к результату что сам AJAX RPC подбросил нам важных api&spec ендпоинтов таких как
/r.php/api;/openapi.json;/swagger.json;/lib/ajax/service.php;/edwiserreports/request_handler.php;И др-
В качестве дальнейшего развития можно анализировать каждый ендпоинт и это мы рассмотрим в заключительной части цикла.
Скачивая .html версии и проходя этапы парсинга дополнительных ендпоинтов; файлов; конфигов; спецификаций; функций; хедеров и тд.
Таким образом от маленького маппинга в таком виде будет построена полноценная карта взаимодействий api