Листая форум, наткнулся на интересное сообщение от Patr1ck
Мне, как человеку, работавшему в больших компаниях на высоконагруженных проектах, захотелось высказаться на эту тему. С петабайтными базами не работал, но с сотнями терабайт данных - очень даже. Проектировал, проводил различные манипуляции, в том числе и на проде. В основном это были postgres и oracle, то есть реляционки, но и Nosql тоже трогал, хоть и меньше.
Про БД можно писать очень долго и много, постараюсь быть краток, насколько это возможно. Вероятно, упущу какие-то важные и не очень моменты. Если буду вопросы, с радостью отвечу на них.
Без конкретики будет сложновато, поэтому представьте, что у вас есть такая реляционная БД простого форума. Пользователи, форумы, темы, посты, лайки к постам. Тут, конечно, очень многого не хватает, да и вообще, форумы сильно сложнее. Но это же пример, так? База развёрнута на каком-то сервере, нюансы пока не особо важны. Форум работает прекрасно. Тут и далее будем рассматривать всё только со стороны БД, безотносительно приложения (до шардинга).

И так - что же такое шардирование? А также партиционирование и репликация. Для тех, кто в танке. Краткий экскурс
Когда речь заходит о базах данных, стороной эту троицу не обходят.
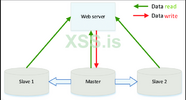
Начнём с репликации на примере нашей БД.
Ура! Ваш форум становится популярным! Но вместе с этим приходят и проблемы. У вашего сервера есть лимиты по CPU и RAM, у базы есть лимиты по подключениям и так далее. Когда пользователей мало – всё работает хорошо, сервер справляется. Но с ростом пользователей начинает расти количество обращений к базе, каждое открытие темы – селект запрос, а если их тысячи в секунду, база начинает тормозить, запросы попадают в очередь. Пользователи активно пишут посты и создают темы. Круто! Но объём базы растёт, таблицы становятся огромными. Индексы работают хуже. Темы на форуме загружаются долго, пользователи жалуются и в конечном итоге уходят к вашим конкурентам, вероятно, на XSS – форум, который не лагает, потому что использует крутой движок и нормальные сервера. Ваш сервер с базой отключили за неуплату – форум вообще перестал работать. Что же делать?
Бегство пользователей ещё можно остановить. В этом вам и поможет репликация.
Репликация (физическая) – это создание копии базы данных на другом физическом сервере.
Вы настроили репликацию, теперь у вас есть главный сервер (master) и реплики (slave, follower), которые обновляют копию базы при обновлении мастера.
Важно понимать, что репликацией масштабируется только чтение, но не запись.
Топологии (виды, если угодно) репликации:
Master-Slave
Пишем в мастер, читаем из слейвов или из мастера (поэтому разгрузка на чтение). В случае падения мастера – downtime на запись. Если мастер упал, выбираем другого мастера, это называется failover. Можно заранее определить реплику, которая будет мастером, если он упадёт (hot standby).

Master-master (multi-master)
Пишем в разных мастеров, читаем из слейвов или мастеров. В случае падения мастера нет downtime на запись, т.к. мастеров несколько.

Но тут появляются конфликты.
Write-write (два мастера апдейтят одну запись одновременно)

Unique (два мастера создают записи с одинаковым ключом одновременно)
Order (конфликты порядка операций, например insert-update на разных мастерах применяются в разном порядке).
Можно эти конфликты и разрешать: LWW, ранг реплик, CRDT…
Chain replication (редко встречается)
Запись в мастера, потом последовательно изменение реплик
Cascade replication (тоже редко)
Реплика может быть источником для изменений другой реплики
А ещё репликация может быть синхронная и асинхронная! Но сейчас не об этом, это же краткий эскурс. Однако стоит сказать, что в нагруженных системах чаще всего используется асинхронная, т.к. из-за объёмов синхронная будет приводить к большим задержкам и возможно перегрузки сети.
Репликация (логическая)
Это пригодится вам сильно реже, но если очень интересно – добро пожаловать сюда:

 www.postgresql.org
Грубо говоря, это копирование изменения данных (CRUD операций) из одной базы в другую. Таким образом, можно копировать часть таблиц, реплицироваться между разными СУБД и так далее.
www.postgresql.org
Грубо говоря, это копирование изменения данных (CRUD операций) из одной базы в другую. Таким образом, можно копировать часть таблиц, реплицироваться между разными СУБД и так далее.

Партиционирование
Годы идут, форум становится более популярным. 2025, 2026, 2027, 2028… Пользователей – сотни тысяч, постов – миллионы. Таблицы безудержно растут. База начинает тормозить. Очень сложно выполнять, например, аналитически запросы для сбора статистики. Все посты за текущий год/месяц, все сообщения пользователя Х (банально, чаще всего это есть в профиле на форумах) и так далее.
На помощь нам приходит партиционирование – это способ физически разбить одну большую таблицу на несколько маленьких по какому-то ключу. Каждая подтаблица будет хранить свой набор данных. Разбиение физическое, то есть логически таблица остаётся одной.
Партиционирование реализуется на уровне СУБД, как правило, на уровне приложения ничего менять не надо.
На примере нашего форума, у нас есть таблица posts, которая физически разбивается на куски, например, по годам. И появляются разные партиции posts_2025, posts_2026, posts_2027…
Теперь запрос по типу "выдай все посты за 2026" не лезет в многомилионную таблицу, а идёт только в таблицу с постами за 2026, ну и новые посты/темы/… ищутся быстрее, поскольку свежая партиция содержит не так много данных.
Партиционировать можно не только по дате, а вообще по чему угодно, в зависимости от требований, хоть по алфавиту. Обычно партиционирование работает через дерево партиций, где корень – сама таблица (posts), а узлы – отдельные партиции. И когда делается запрос, база по WHERE понимает, в какую партицию смотреть. Есть ещё вложенные партиции, например, сначала делим посты по году, а внутри каждого года – по месяцам (это subpartitioning).

Тут важно сказать, что если у вас таблица уже содержит много данных, то нельзя её превратить из posts в posts по годам разом. Нужно создать новую партиционированную таблицу, создать партиции, а потом мигрировать данные. Это касается большинства СУБД, но опять же, говорю про постгрес. Обычно в компаниях такое делают в тех. окно, чтобы избежать замедления для пользователей. Поскольку если вы просто сделаете INSTERT INTO new_partitioning_posts SELECT * FROM posts, то бд может блокировать табличку posts на изменения.
Такая миграция может суммарно занимать недели, говорю из реального опыта.
Ну и не забывайте пересмотреть индексы и триггеры, для партиций может быть другая структура, в отличие от исходной таблицы.
В общем-то про партиции всё, я думаю, что тут понятно.
Шардирование
Данных в базе уже настолько много, что один сервер не справляется с их количеством. Они буквально не помещаются на диск. Покупать сервера с более крутыми дисками (дорого, да и их может и не быть) - это, кстати, вертикальное масштабирование (улучшаем железо). А вот купить ещё один такой же сервер с такими же дисками - сильно дешевле, - это горизонтальное масштабирование (добавляем количество серверов).

Шардирование - это когда мы не просто делим базу на части на одном сервере, как это было с партиционированием, а распределяем данные по разным серверам. Каждый сервер теперь отвечает за свою часть данных. Такой сервер называют шардом.
Данных в базе уже настолько много, что один сервер не справляется с их количеством. Они буквально не помещаются на диск.
Шардирование чаще реализуется на уровне приложения, но есть СУБД с нативным шардингом (монго, кликхаус, кассандра и другие). Нативный шардинг я тут не рассматриваю, но концепция одна и та же.
Например, один шард хранит посты с id от 1 до миллиона, второй – от миллион+1 до 2 миллионов и так далее. Опять же, как и с партициями, деление на шарды может быть какое угодно (по id, по датам, по количеству овтетов в темах и так далее), в зависимосте о целей.
Получается, что у нас теперь не одна база, а много маленьких баз.
Но тут появляются свои сложности: нужно понять, где какие данные лежат и уметь совмещать данные из разных шардов. Например, пользователь вводит что-то в поиске форума, а в ответе содержатся посты как за 2025, так и за 2028, они лежат в разных шардах. Нужно выдать это пользователю единым ответом.
Шардирование бывает статическим и динамическим.
Статическое шардирование - когда изначально определяется формула для разбиения данных по шардам и количество шардов. Используется редко. Например, говорим, что у нас будет 4 шарда - posts_1, posts_2, posts_3, posts_4. Для выбора шарда можно взять, например, hash(key) % 4, где key - идентификатор объекта (например, thread_id, user_id и т.п.), а % - остаток от деления. Но использовать автоинкрементные и неравномерные ключи не нужно, это приведёт к hot spot.
Динамическое шардирование - чаще всего оно и используется. Грубо говоря, это способ шардирование, когда система (в данном случае, база или система, её использующая) умеет сама добавлять новые шарды и распределять данные между ними. Важно выбирать правильный ключ для шардинга, чтобы было равномерное распределение данных иначе можно получить hot spot, перекос нагрузки/объёма.
Часто используется схема с виртуальными бакетами, картинка ниже.
Есть ещё разные стратегии шардирования. Вот вам картинка:

Про шардирование можно ещё много что сказать... Например, один из шардов может стать слишком нагруженным, тогда нужно перекидывать часть данных в другой шард - это называется resharding. Связанные данные (условно, пользователи и их посты) лучше хранить вместе - все данные по одному пользователю в одном шарде. Но может возникнуть ситуация, когда данные для запроса размазаны по разным шардам, и нужно вводить карту шардов (shard map/lookup table), которая позволит быстро найти нужные записи.
Или, например, если запрос должен изменить данные в нескольких шардах сразу (межшардовая транзакция) - это тоже сложно, читайте про 2-phase-commit, eventual consistency, saga pattern.
Интересная статейка про шардирование в более общем виде:

 habr.com
habr.com
Ну, с базой более-менее понятно, давайте вернёмся к исходному вопросу. Что имеем?
"Предложи схему шардирования данных для системы, обрабатывающей петабайты данных, с учетом необходимости поддержки сложных аналитических запросов и hot spot митигации. Как бы ты решал проблему репартиционирования данных?"
Пойдём по порядку:
Петабайты данных - С петабайтами понятно, вряд ли мы найдём таком сервер, поэтому и нужно шардирование - разнесение данных по разным серверам.
сложные запросы - окей, хотелось бы знать доменную область, но наверное это не сильно важно для теории. Возможно пригодится какая-то OLAP (оперативная аналитическая обработка данных...бла-бла-бла...) система... Нужно учитывать порядок данных и возможно параллельных выборок, быстрый сбор агрегатов.
hot spot - это когда много запросов происходят одновременно на одних и тех же строках, в результате появляются блокировки, увеличиваются задержки и так далее. О причинах возникновения говорить сейчас не будем, но в том числе это может быть неудачный подбор ключей для шардинга. Вопрос в том, как бороться с такими штуками (mitigation - смягчение последствий, дословно)
репартиционирование, решардирование - ну тут понятно.
Что делаем?
Без знания доменной области сложновато, поэтому будем считать, что это про наш гипотетический форум. Для него это не так уж и сложно.
Схема шардирования
Будем использовать схему с виртуальными бакетами (virtual buckets). Генерируем, допустим, 1000 бакетов.
Кажется, что основной объект для аналитики - тема на форуме. Следующей по вероятности (имхо) - пользователей, но пусть будет тема.
У каждой темы есть уникальный thread_id (threads.id).
Находим нужный слот для шардинга: slot = hash(thread_id) % 1000
Всё связанное (посты, лайки, вложения) - идут в этот слот. Пользователи наверное отдельно.
Для распределения нагрузки и гибкости при масштабировании будем использовать таблицу shard_map (маппинг виртуальных шардов на физические). Это позволяет при необходимости быстро перебалансировать нагрузку, не затрагивая всю систему целиком. На одном сервере может находиться несколько бакетов. Первично можно распределить равномерно, потом подключим динамическую ребалансировку.
Такой подход минимизирует количество межшардовых транзакций.
Таблицы постов (и другие) партиционируем по месяцам/дням, чтобы ускорить аналитические и range-запросы.
Аналитические запросы
База нашего форума на постресе, что как бы не очень стакается с аналитическими запросами, поэтому тут можно сделать следующее:
Поднимаем OLAP-движок отдельно и туда сливаем копии или агрегаты нужных таблиц для аналитики. Но это какой-то костыль, не так ли? Обычно реализовывают отдельный ETL процесс с OLTP частью (транзакционная система) - где проходят все транзакции и бизнес-логика и OLAP -частью, с движком типа clickhouse, куда сливаются данные и где уже выполняются нужные запросы. На продовых шардах никто ничего не анализирует.
Можно сделать так, чтобы приложение стало Query-роутером (получаем запрос, определяем шарды и партиции, содержащие нужные данные, отправлям запросы на нужные шарды, агреггируем ответ). Не забываем про кеш, подрубаем какой-нибудь редис.
Ещё лучше - не используем сложные аналитические запросы для форума") Как правило, это и не нужно.
Как правило, это и не нужно.
Митигация
Если мы правильно выбрали стратегию шардинга и ключ, то скорее всего hot spot не произойдёт, но всё же.
Допустим, какая-то тема стала вирусной и туда летят миллионы просмотров, лайков. На один сервер приходится слишком большая доля нагрузки, а остальные - простаивают. Что тут можно сделать? ̶В̶с̶е̶ ̶в̶о̶п̶р̶о̶с̶ы̶ ̶к̶ ̶D̶B̶A̶,̶ ̶я̶ ̶в̶с̶е̶г̶о̶ ̶л̶и̶ш̶ь̶ ̶р̶а̶з̶р̶а̶б̶о̶т̶ч̶и̶к̶
Ну конечно же, в нашей крутой системе настроен мониторинг. Админам приходит алерт, как только появляется что-то красненькое в графане, даже заранее, такой вот превентивный подход.
Как только мы видим, что какому-то серверу плохо, используем балансировку, скорее всего это автоматически происходит. Можно держать отдельный кеш для этой темы, чтобы запросы на чтение летели в кеш и сервер не перегружался. Можно дробить слоты. И скорее всего у нас есть заранее зарезервированные пустые слоты для таких штук, куда можно переносить всё необходимое. Часто кешируют топ X ключей.
Репартиционирование
Тут скорее про решардинг. Всё это связанно и с прошлой темой. Давайте на примере, чтобы не так скучно:
Обнаруживаем перегрузку сервера
Добавляем новый сервер X
Копируем данные по слотам. Балком переносим все данные на новый сервер, затем включают dual_write, обновляют shard_map на новый сервер
Проверяем, что все данные на месте.
Убеждаемся в отсутствии потерять и каких-то конфликтов, внимательно мониторим логи.
Наслаждаемся. Вы прекрасны. А теперь подумайте о решениях, которые автоматически занимаются шардированием, ребалансировкой и минимизацией hot-spot.
И вообще, я почти на 100% уверен, что для такого запроса не используется постгрес (или не только он, скорее нереляционная БД), а там всё совсем иначе и правильней!
Опять же, всё это мало применимо к форуму, но я старался натянуть сову на глобус.
Я думал, что напишу эту статью за полчаса, но ушёл весь вечер. Начиная писать о какой-то теме, понял, что можно углубляться бесконечно. Старался себя останавливать и не идти слишком глубоко. Буду рад обратной связи.
Код:
Предложи схему шардирования данных для системы, обрабатывающей петабайты данных, с учетом необходимости поддержки сложных аналитических запросов и hot spot митигации. Как бы ты решал проблему репартиционирования данных?Мне, как человеку, работавшему в больших компаниях на высоконагруженных проектах, захотелось высказаться на эту тему. С петабайтными базами не работал, но с сотнями терабайт данных - очень даже. Проектировал, проводил различные манипуляции, в том числе и на проде. В основном это были postgres и oracle, то есть реляционки, но и Nosql тоже трогал, хоть и меньше.
Про БД можно писать очень долго и много, постараюсь быть краток, насколько это возможно. Вероятно, упущу какие-то важные и не очень моменты. Если буду вопросы, с радостью отвечу на них.
Без конкретики будет сложновато, поэтому представьте, что у вас есть такая реляционная БД простого форума. Пользователи, форумы, темы, посты, лайки к постам. Тут, конечно, очень многого не хватает, да и вообще, форумы сильно сложнее. Но это же пример, так? База развёрнута на каком-то сервере, нюансы пока не особо важны. Форум работает прекрасно. Тут и далее будем рассматривать всё только со стороны БД, безотносительно приложения (до шардинга).
Реальная схема БД одного из современных форумных движков. Как вам DDL на 10 тысяч строк? https://github.com/prisma/database-schema-examples/blob/main/postgres/discourse/schema.sql
И так - что же такое шардирование? А также партиционирование и репликация. Для тех, кто в танке. Краткий экскурс
Когда речь заходит о базах данных, стороной эту троицу не обходят.
Начнём с репликации на примере нашей БД.
Ура! Ваш форум становится популярным! Но вместе с этим приходят и проблемы. У вашего сервера есть лимиты по CPU и RAM, у базы есть лимиты по подключениям и так далее. Когда пользователей мало – всё работает хорошо, сервер справляется. Но с ростом пользователей начинает расти количество обращений к базе, каждое открытие темы – селект запрос, а если их тысячи в секунду, база начинает тормозить, запросы попадают в очередь. Пользователи активно пишут посты и создают темы. Круто! Но объём базы растёт, таблицы становятся огромными. Индексы работают хуже. Темы на форуме загружаются долго, пользователи жалуются и в конечном итоге уходят к вашим конкурентам, вероятно, на XSS – форум, который не лагает, потому что использует крутой движок и нормальные сервера. Ваш сервер с базой отключили за неуплату – форум вообще перестал работать. Что же делать?
Бегство пользователей ещё можно остановить. В этом вам и поможет репликация.
Репликация (физическая) – это создание копии базы данных на другом физическом сервере.
Вы настроили репликацию, теперь у вас есть главный сервер (master) и реплики (slave, follower), которые обновляют копию базы при обновлении мастера.
Важно понимать, что репликацией масштабируется только чтение, но не запись.
Топологии (виды, если угодно) репликации:
Master-Slave
Пишем в мастер, читаем из слейвов или из мастера (поэтому разгрузка на чтение). В случае падения мастера – downtime на запись. Если мастер упал, выбираем другого мастера, это называется failover. Можно заранее определить реплику, которая будет мастером, если он упадёт (hot standby).
Master-master (multi-master)
Пишем в разных мастеров, читаем из слейвов или мастеров. В случае падения мастера нет downtime на запись, т.к. мастеров несколько.
Но тут появляются конфликты.
Write-write (два мастера апдейтят одну запись одновременно)
Unique (два мастера создают записи с одинаковым ключом одновременно)
Order (конфликты порядка операций, например insert-update на разных мастерах применяются в разном порядке).
Можно эти конфликты и разрешать: LWW, ранг реплик, CRDT…
Chain replication (редко встречается)
Запись в мастера, потом последовательно изменение реплик
Cascade replication (тоже редко)
Реплика может быть источником для изменений другой реплики
А ещё репликация может быть синхронная и асинхронная! Но сейчас не об этом, это же краткий эскурс. Однако стоит сказать, что в нагруженных системах чаще всего используется асинхронная, т.к. из-за объёмов синхронная будет приводить к большим задержкам и возможно перегрузки сети.
Репликация (логическая)
Это пригодится вам сильно реже, но если очень интересно – добро пожаловать сюда:
Chapter 29. Logical Replication
Chapter 29. Logical Replication Table of Contents 29.1. Publication 29.2. Subscription 29.2.1. Replication Slot Management 29.2.2. Examples: Set Up Logical Replication 29.2.3. …
www.postgresql.org
Партиционирование
Годы идут, форум становится более популярным. 2025, 2026, 2027, 2028… Пользователей – сотни тысяч, постов – миллионы. Таблицы безудержно растут. База начинает тормозить. Очень сложно выполнять, например, аналитически запросы для сбора статистики. Все посты за текущий год/месяц, все сообщения пользователя Х (банально, чаще всего это есть в профиле на форумах) и так далее.
На помощь нам приходит партиционирование – это способ физически разбить одну большую таблицу на несколько маленьких по какому-то ключу. Каждая подтаблица будет хранить свой набор данных. Разбиение физическое, то есть логически таблица остаётся одной.
Партиционирование реализуется на уровне СУБД, как правило, на уровне приложения ничего менять не надо.
На примере нашего форума, у нас есть таблица posts, которая физически разбивается на куски, например, по годам. И появляются разные партиции posts_2025, posts_2026, posts_2027…
Теперь запрос по типу "выдай все посты за 2026" не лезет в многомилионную таблицу, а идёт только в таблицу с постами за 2026, ну и новые посты/темы/… ищутся быстрее, поскольку свежая партиция содержит не так много данных.
Партиционировать можно не только по дате, а вообще по чему угодно, в зависимости от требований, хоть по алфавиту. Обычно партиционирование работает через дерево партиций, где корень – сама таблица (posts), а узлы – отдельные партиции. И когда делается запрос, база по WHERE понимает, в какую партицию смотреть. Есть ещё вложенные партиции, например, сначала делим посты по году, а внутри каждого года – по месяцам (это subpartitioning).
Тут важно сказать, что если у вас таблица уже содержит много данных, то нельзя её превратить из posts в posts по годам разом. Нужно создать новую партиционированную таблицу, создать партиции, а потом мигрировать данные. Это касается большинства СУБД, но опять же, говорю про постгрес. Обычно в компаниях такое делают в тех. окно, чтобы избежать замедления для пользователей. Поскольку если вы просто сделаете INSTERT INTO new_partitioning_posts SELECT * FROM posts, то бд может блокировать табличку posts на изменения.
Такая миграция может суммарно занимать недели, говорю из реального опыта.
Ну и не забывайте пересмотреть индексы и триггеры, для партиций может быть другая структура, в отличие от исходной таблицы.
В общем-то про партиции всё, я думаю, что тут понятно.
Шардирование
Данных в базе уже настолько много, что один сервер не справляется с их количеством. Они буквально не помещаются на диск. Покупать сервера с более крутыми дисками (дорого, да и их может и не быть) - это, кстати, вертикальное масштабирование (улучшаем железо). А вот купить ещё один такой же сервер с такими же дисками - сильно дешевле, - это горизонтальное масштабирование (добавляем количество серверов).
Шардирование - это когда мы не просто делим базу на части на одном сервере, как это было с партиционированием, а распределяем данные по разным серверам. Каждый сервер теперь отвечает за свою часть данных. Такой сервер называют шардом.
Данных в базе уже настолько много, что один сервер не справляется с их количеством. Они буквально не помещаются на диск.
Шардирование чаще реализуется на уровне приложения, но есть СУБД с нативным шардингом (монго, кликхаус, кассандра и другие). Нативный шардинг я тут не рассматриваю, но концепция одна и та же.
Например, один шард хранит посты с id от 1 до миллиона, второй – от миллион+1 до 2 миллионов и так далее. Опять же, как и с партициями, деление на шарды может быть какое угодно (по id, по датам, по количеству овтетов в темах и так далее), в зависимосте о целей.
Получается, что у нас теперь не одна база, а много маленьких баз.
Но тут появляются свои сложности: нужно понять, где какие данные лежат и уметь совмещать данные из разных шардов. Например, пользователь вводит что-то в поиске форума, а в ответе содержатся посты как за 2025, так и за 2028, они лежат в разных шардах. Нужно выдать это пользователю единым ответом.
Шардирование бывает статическим и динамическим.
Статическое шардирование - когда изначально определяется формула для разбиения данных по шардам и количество шардов. Используется редко. Например, говорим, что у нас будет 4 шарда - posts_1, posts_2, posts_3, posts_4. Для выбора шарда можно взять, например, hash(key) % 4, где key - идентификатор объекта (например, thread_id, user_id и т.п.), а % - остаток от деления. Но использовать автоинкрементные и неравномерные ключи не нужно, это приведёт к hot spot.
Динамическое шардирование - чаще всего оно и используется. Грубо говоря, это способ шардирование, когда система (в данном случае, база или система, её использующая) умеет сама добавлять новые шарды и распределять данные между ними. Важно выбирать правильный ключ для шардинга, чтобы было равномерное распределение данных иначе можно получить hot spot, перекос нагрузки/объёма.
Часто используется схема с виртуальными бакетами, картинка ниже.
Есть ещё разные стратегии шардирования. Вот вам картинка:
Про шардирование можно ещё много что сказать... Например, один из шардов может стать слишком нагруженным, тогда нужно перекидывать часть данных в другой шард - это называется resharding. Связанные данные (условно, пользователи и их посты) лучше хранить вместе - все данные по одному пользователю в одном шарде. Но может возникнуть ситуация, когда данные для запроса размазаны по разным шардам, и нужно вводить карту шардов (shard map/lookup table), которая позволит быстро найти нужные записи.
Или, например, если запрос должен изменить данные в нескольких шардах сразу (межшардовая транзакция) - это тоже сложно, читайте про 2-phase-commit, eventual consistency, saga pattern.
Интересная статейка про шардирование в более общем виде:
ШаÑдиÑоваÑÑ Ð¸Ð»Ð¸ не ÑаÑдиÑоваÑÑ
Ðведение ÐÑимениÑелÑно к плаÑежнÑм ÑиÑÑемам ÑаÑдиÑование ÑвлÑеÑÑÑ Ð²Ð°Ð¶Ð½Ð¾Ð¹ возможноÑÑÑÑ, позволÑÑÑей делаÑÑ Ð³ÐµÑеÑогеннÑе ÑеÑвиÑÑ. ÐапÑимеÑ, оÑевидно, ÑÑо полÑзоваÑели Ñ Ð¿Ð»Ð°Ñежной...
habr.com
Ну, с базой более-менее понятно, давайте вернёмся к исходному вопросу. Что имеем?
"Предложи схему шардирования данных для системы, обрабатывающей петабайты данных, с учетом необходимости поддержки сложных аналитических запросов и hot spot митигации. Как бы ты решал проблему репартиционирования данных?"
Пойдём по порядку:
Петабайты данных - С петабайтами понятно, вряд ли мы найдём таком сервер, поэтому и нужно шардирование - разнесение данных по разным серверам.
сложные запросы - окей, хотелось бы знать доменную область, но наверное это не сильно важно для теории. Возможно пригодится какая-то OLAP (оперативная аналитическая обработка данных...бла-бла-бла...) система... Нужно учитывать порядок данных и возможно параллельных выборок, быстрый сбор агрегатов.
hot spot - это когда много запросов происходят одновременно на одних и тех же строках, в результате появляются блокировки, увеличиваются задержки и так далее. О причинах возникновения говорить сейчас не будем, но в том числе это может быть неудачный подбор ключей для шардинга. Вопрос в том, как бороться с такими штуками (mitigation - смягчение последствий, дословно)
репартиционирование, решардирование - ну тут понятно.
Что делаем?
Без знания доменной области сложновато, поэтому будем считать, что это про наш гипотетический форум. Для него это не так уж и сложно.
Схема шардирования
Будем использовать схему с виртуальными бакетами (virtual buckets). Генерируем, допустим, 1000 бакетов.
Кажется, что основной объект для аналитики - тема на форуме. Следующей по вероятности (имхо) - пользователей, но пусть будет тема.
У каждой темы есть уникальный thread_id (threads.id).
Находим нужный слот для шардинга: slot = hash(thread_id) % 1000
Всё связанное (посты, лайки, вложения) - идут в этот слот. Пользователи наверное отдельно.
Для распределения нагрузки и гибкости при масштабировании будем использовать таблицу shard_map (маппинг виртуальных шардов на физические). Это позволяет при необходимости быстро перебалансировать нагрузку, не затрагивая всю систему целиком. На одном сервере может находиться несколько бакетов. Первично можно распределить равномерно, потом подключим динамическую ребалансировку.
Такой подход минимизирует количество межшардовых транзакций.
Таблицы постов (и другие) партиционируем по месяцам/дням, чтобы ускорить аналитические и range-запросы.
Аналитические запросы
База нашего форума на постресе, что как бы не очень стакается с аналитическими запросами, поэтому тут можно сделать следующее:
Поднимаем OLAP-движок отдельно и туда сливаем копии или агрегаты нужных таблиц для аналитики. Но это какой-то костыль, не так ли? Обычно реализовывают отдельный ETL процесс с OLTP частью (транзакционная система) - где проходят все транзакции и бизнес-логика и OLAP -частью, с движком типа clickhouse, куда сливаются данные и где уже выполняются нужные запросы. На продовых шардах никто ничего не анализирует.
Можно сделать так, чтобы приложение стало Query-роутером (получаем запрос, определяем шарды и партиции, содержащие нужные данные, отправлям запросы на нужные шарды, агреггируем ответ). Не забываем про кеш, подрубаем какой-нибудь редис.
Ещё лучше - не используем сложные аналитические запросы для форума
Как правило, это и не нужно.Митигация
Если мы правильно выбрали стратегию шардинга и ключ, то скорее всего hot spot не произойдёт, но всё же.
Допустим, какая-то тема стала вирусной и туда летят миллионы просмотров, лайков. На один сервер приходится слишком большая доля нагрузки, а остальные - простаивают. Что тут можно сделать? ̶В̶с̶е̶ ̶в̶о̶п̶р̶о̶с̶ы̶ ̶к̶ ̶D̶B̶A̶,̶ ̶я̶ ̶в̶с̶е̶г̶о̶ ̶л̶и̶ш̶ь̶ ̶р̶а̶з̶р̶а̶б̶о̶т̶ч̶и̶к̶
Ну конечно же, в нашей крутой системе настроен мониторинг. Админам приходит алерт, как только появляется что-то красненькое в графане, даже заранее, такой вот превентивный подход.
Как только мы видим, что какому-то серверу плохо, используем балансировку, скорее всего это автоматически происходит. Можно держать отдельный кеш для этой темы, чтобы запросы на чтение летели в кеш и сервер не перегружался. Можно дробить слоты. И скорее всего у нас есть заранее зарезервированные пустые слоты для таких штук, куда можно переносить всё необходимое. Часто кешируют топ X ключей.
Репартиционирование
Тут скорее про решардинг. Всё это связанно и с прошлой темой. Давайте на примере, чтобы не так скучно:
Обнаруживаем перегрузку сервера
Добавляем новый сервер X
Копируем данные по слотам. Балком переносим все данные на новый сервер, затем включают dual_write, обновляют shard_map на новый сервер
Проверяем, что все данные на месте.
Убеждаемся в отсутствии потерять и каких-то конфликтов, внимательно мониторим логи.
Наслаждаемся. Вы прекрасны. А теперь подумайте о решениях, которые автоматически занимаются шардированием, ребалансировкой и минимизацией hot-spot.
И вообще, я почти на 100% уверен, что для такого запроса не используется постгрес (или не только он, скорее нереляционная БД), а там всё совсем иначе и правильней!
Опять же, всё это мало применимо к форуму, но я старался натянуть сову на глобус.
Я думал, что напишу эту статью за полчаса, но ушёл весь вечер. Начиная писать о какой-то теме, понял, что можно углубляться бесконечно. Старался себя останавливать и не идти слишком глубоко. Буду рад обратной связи.