Пожалуйста, обратите внимание, что пользователь заблокирован
Попалась мне тут в твиттерах одна тулза от @TinySecEx. Мне как человеку далекому от создания веб-приложух стало интересно какие технологии он использует. И в целом интересно было бы создать аналогичную тулзу для автоматизации рутины.
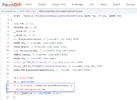
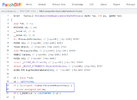
Судя по скринам, я понял следующее.



1. Основной модуль диффинга построен вокруг IDA и Bindiff.
Т.е. создается две базы IDA, затем консольной утилитой bindiff.exe создаются две базы .Binexport, ей же затем создается sqlite3 база .Bindiff.
Собственно потом .Bindiff база парсится на различия по полям name1, name2, address1, address2, similarity.


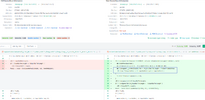
Правда я не нашел полей для удаленных и добавленных функций. Может плохо смотрел. На основе этой инфы на IDAPython пишется скрипт для декомпиляции функций по имени/адресу, данные сохраняются, например, в два текстовых файла. Т.к. не нужно декомпилировать всю базу, а только функции с similarity < 1, то это не занимает много времени. Потом, например, петухоновской либой difflib создается такой html (diaphora тоже юзает эту либу).

В Patchdiff конечно вывод поприятнее выглядит, скорее всего там использовалось что-то другое.
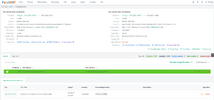
Ясно, что там много чего еще сделано, есть скорее всего парсинг KBшек и получение уязвимой, патченной версии бинарей, работа с API мелкософта для сопоставления бинарей c CVE и т.д.
В общем интересны ваши мысли по тому, как может быть устроена эта тулза, какие технологии используются.
Судя по скринам, я понял следующее.
1. Основной модуль диффинга построен вокруг IDA и Bindiff.
Т.е. создается две базы IDA, затем консольной утилитой bindiff.exe создаются две базы .Binexport, ей же затем создается sqlite3 база .Bindiff.
Собственно потом .Bindiff база парсится на различия по полям name1, name2, address1, address2, similarity.
Правда я не нашел полей для удаленных и добавленных функций. Может плохо смотрел. На основе этой инфы на IDAPython пишется скрипт для декомпиляции функций по имени/адресу, данные сохраняются, например, в два текстовых файла. Т.к. не нужно декомпилировать всю базу, а только функции с similarity < 1, то это не занимает много времени. Потом, например, петухоновской либой difflib создается такой html (diaphora тоже юзает эту либу).
В Patchdiff конечно вывод поприятнее выглядит, скорее всего там использовалось что-то другое.
Ясно, что там много чего еще сделано, есть скорее всего парсинг KBшек и получение уязвимой, патченной версии бинарей, работа с API мелкософта для сопоставления бинарей c CVE и т.д.
В общем интересны ваши мысли по тому, как может быть устроена эта тулза, какие технологии используются.