Написал: rand
Эксклюзивно для: xss.pro
Отдельная благодарность в помощи и тестировании: antikrya, celty, Bertor, Eject, Zeta
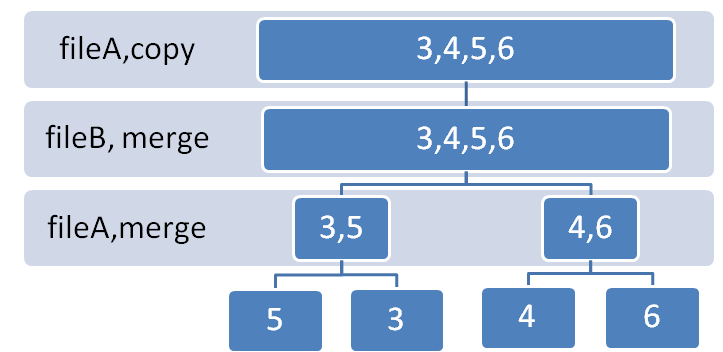
Всем привет, не так давно у меня появилась идея (после того как я прочитал этот тред https://xss.pro/threads/122300/) реализовать на питоне скрипт который делает быструю сортировку и очистку дублей строк в огромном текстовом файле без колоссального потребления ресурсов ОЗУ в операционной системе.
Минимальные системные требования: Python 3.12, 4 ядра CPU, 4 гигабайта ОЗУ, 200% свободного места на накопителе от размера импортируемого файла+10%. (При работе этого алгоритма приходится расплачиваться свободной памятью и ресурсом накопителя).
Скрины отработки 100-гигового ULP:






Скрипт работает на встроенных библиотеках питона, кроме одной библиотеки используемой для разметки выдачи цвета лога (в общем все подробно объяснил в комментариях к коду, может быть потом исправлю тут на полноценную статью, если настроение будет):
Мультипроцессорно-многопоточная версия, работает быстрее, но и к ресурсам требовательна по процу и памяти раз в 5-10 (пример отработки ".txt файл 100 миллионов строк, размером в 2GB (Ryzen 5600 4700mhz, 32GB DDR4 3600MHZ):

Скриншот отработки 300 гигового сгенерированного лога без дублей на 4.5 миллиарда строк, чем больше уникальных строк, тем ниже скорость обработки (AMD Ryzen 7 3700x, 64GB ОЗУ, 1TB NVME в Raid 1 из двух накопителей по 1TB, Linux Ubuntu 22.04):

Эксклюзивно для: xss.pro
Отдельная благодарность в помощи и тестировании: antikrya, celty, Bertor, Eject, Zeta
Всем привет, не так давно у меня появилась идея (после того как я прочитал этот тред https://xss.pro/threads/122300/) реализовать на питоне скрипт который делает быструю сортировку и очистку дублей строк в огромном текстовом файле без колоссального потребления ресурсов ОЗУ в операционной системе.
Минимальные системные требования: Python 3.12, 4 ядра CPU, 4 гигабайта ОЗУ, 200% свободного места на накопителе от размера импортируемого файла+10%. (При работе этого алгоритма приходится расплачиваться свободной памятью и ресурсом накопителя).
Скрины отработки 100-гигового ULP:
Скрипт работает на встроенных библиотеках питона, кроме одной библиотеки используемой для разметки выдачи цвета лога (в общем все подробно объяснил в комментариях к коду, может быть потом исправлю тут на полноценную статью, если настроение будет):
Bash:
pip install colorlog==6.8.2main.py
Python:
import os
import tempfile
import heapq
import time
import logging
from concurrent.futures import ThreadPoolExecutor, as_completed
from colorlog import ColoredFormatter # Для цветного логирования
# Настраиваем цветное логирование
formatter = ColoredFormatter(
"%(log_color)s%(asctime)s - %(levelname)s - %(message)s", # Формат вывода логов
datefmt=None, # Формат даты, по умолчанию
reset=True, # Сброс цветов после каждой строки
log_colors={ # Задаем цвета для различных уровней логов
'DEBUG': 'cyan',
'INFO': 'green',
'WARNING': 'yellow',
'ERROR': 'red',
'CRITICAL': 'bold_red',
}
)
# Настройка обработчика логов с UTF-8
handler = logging.StreamHandler() # Логи выводятся в консоль
handler.setFormatter(formatter) # Применяем цветной формат
logger = logging.getLogger() # Получаем объект логгера
logger.addHandler(handler) # Добавляем к нему наш обработчик
logger.setLevel(logging.INFO) # Устанавливаем уровень логирования INFO (можно изменять на DEBUG для более детальных логов)
# Создаем путь к папке TEMP для временных файлов
temp_dir = os.path.join(os.getcwd(), 'TEMP') # Директория для хранения временных файлов
if not os.path.exists(temp_dir): # Если папки нет, создаем её в корне скрипта
os.makedirs(temp_dir)
# Функция для обработки чанков: удаление дублей и сортировка
def process_chunk(chunk, temp_dir):
try:
logger.info(f"Начало обработки чанка размером {len(chunk)} строк") # Логируем количество строк в чанке
unique_items = set(chunk) # Превращаем список в множество для удаления дублей
logger.info(f"Удалено {len(chunk) - len(unique_items)} дублей в чанке") # Логируем, сколько дублей удалено
sorted_chunk = sorted(unique_items) # Сортируем уникальные строки
# Создаем временный файл, который не будет удален автоматически (delete=False)
with tempfile.NamedTemporaryFile(delete=False, mode='w', encoding='utf-8', errors='ignore', dir=temp_dir) as temp_file:
temp_file.write('\n'.join(sorted_chunk) + '\n') # Записываем отсортированный чанк во временный файл
logger.info(f"Чанк записан во временный файл {temp_file.name}") # Логируем путь к временному файлу
return temp_file.name # Возвращаем имя временного файла
except Exception as e:
logger.error(f"Ошибка при обработке чанка: {e}") # Логируем ошибку, если что-то пошло не так
return None # Возвращаем None, если произошла ошибка
# Функция для пакетного слияния временных файлов в один общий файл
def merge_files(temp_files, output_file):
try:
logger.info(f"Окончательное слияние {len(temp_files)} временных файлов") # Логируем количество файлов для слияния
unique_count = 0 # Счетчик уникальных строк
duplicate_count = 0 # Счетчик дублей
# Открываем выходной файл для записи
with open(output_file, 'w', encoding='utf-8', errors='replace') as outfile:
# Открываем все временные файлы и создаем итераторы
file_iters = [open(f, 'r', encoding='utf-8', errors='replace') for f in temp_files]
merged_iter = heapq.merge(*file_iters) # Сливаем отсортированные временные файлы в один поток
prev_line = None # Переменная для отслеживания предыдущей строки
# Проходим по слитым строкам
for line in merged_iter:
if line != prev_line: # Если строка не совпадает с предыдущей (уникальная)
outfile.write(line) # Записываем строку в выходной файл
prev_line = line # Обновляем предыдущую строку
unique_count += 1 # Увеличиваем счетчик уникальных строк
else:
duplicate_count += 1 # Если строка дублируется, увеличиваем счетчик дублей
# Закрываем временные файлы
for f in file_iters:
f.close()
logger.info(f"Слияние завершено. Уникальных строк: {unique_count}, дублей удалено: {duplicate_count}") # Логируем результаты
return unique_count, duplicate_count # Возвращаем количество уникальных строк и дублей
except Exception as e:
logger.error(f"Ошибка при слиянии файлов: {e}") # Логируем ошибку, если слияние не удалось
return 0, 0 # Возвращаем нули в случае ошибки
# Функция для пакетного слияния временных файлов
def batch_merge(temp_files, batch_size, temp_dir):
try:
logger.info(f"Начало пакетного слияния с размером пакета {batch_size}") # Логируем начало пакетного слияния
merged_files = [] # Список для хранения результатов пакетного слияния
total_unique_count = 0 # Общий счетчик уникальных строк
total_duplicate_count = 0 # Общий счетчик дублей
# Обрабатываем файлы по частям (батчами)
for i in range(0, len(temp_files), batch_size):
batch = temp_files[i:i + batch_size] # Берем очередной пакет файлов
logger.info(f"Слияние пакета с файлов {i+1} по {min(i + batch_size, len(temp_files))}") # Логируем диапазон файлов
# Создаем временный файл для результата слияния пакета
with tempfile.NamedTemporaryFile(delete=False, mode='w', encoding='utf-8', dir=temp_dir) as temp_merged_file:
unique_count, duplicate_count = merge_files(batch, temp_merged_file.name) # Сливаем пакет файлов
merged_files.append(temp_merged_file.name) # Добавляем результат слияния в список
total_unique_count += unique_count # Обновляем общий счетчик уникальных строк
total_duplicate_count += duplicate_count # Обновляем общий счетчик дублей
# Удаляем временные файлы после слияния
logger.info(f"Удаление временных файлов пакета с {i+1} по {min(i + batch_size, len(temp_files))}")
for temp_file in batch:
if os.path.exists(temp_file):
os.remove(temp_file) # Удаляем временный файл
return merged_files, total_unique_count, total_duplicate_count # Возвращаем список объединенных файлов и итоговые счетчики
except Exception as e:
logger.error(f"Ошибка при пакетном слиянии: {e}") # Логируем ошибку при пакетном слиянии
return temp_files, 0, 0 # Возвращаем исходные файлы и нули в случае ошибки
# Основная функция сортировки и удаления дубликатов с параллельной обработкой чанков
def sort_and_uniq_streaming(input_file, output_file, chunk_size=2000000, batch_size=10):
temp_files = [] # Список для хранения временных файлов
chunk = [] # Текущий чанк строк
original_count = 0 # Счетчик всех строк в исходном файле
logger.info(f"Чтение файла {input_file}...") # Логируем начало чтения файла
try:
with open(input_file, 'r', encoding='utf-8', errors='ignore') as infile: # Открываем файл для чтения
with ThreadPoolExecutor() as executor: # Создаем пул потоков для параллельной обработки
futures = [] # Список задач для параллельной обработки
for line in infile:
chunk.append(line.strip()) # Добавляем строку в чанк
original_count += 1 # Увеличиваем счетчик строк
if len(chunk) >= chunk_size: # Если размер чанка достиг предела
futures.append(executor.submit(process_chunk, chunk, temp_dir)) # Запускаем обработку чанка в отдельном потоке
chunk = [] # Очищаем чанк для следующего набора строк
if chunk: # Если остались необработанные строки после завершения чтения файла
futures.append(executor.submit(process_chunk, chunk, temp_dir)) # Обрабатываем последний чанк
for future in as_completed(futures): # Ждем завершения всех задач
temp_file = future.result() # Получаем результат обработки (имя временного файла)
if temp_file:
temp_files.append(temp_file) # Добавляем временный файл в список
logger.info(f"Все чанки обработаны. Начинается пакетное слияние временных файлов...") # Логируем завершение обработки всех чанков
total_unique_count = 0 # Общий счетчик уникальных строк
total_duplicate_count = 0 # Общий счетчик дублей
# Пока временных файлов больше, чем размер батча, продолжаем пакетное слияние
while len(temp_files) > batch_size:
temp_files, unique_count, duplicate_count = batch_merge(temp_files, batch_size, temp_dir) # Выполняем пакетное слияние
total_unique_count += unique_count # Увеличиваем общий счетчик уникальных строк
total_duplicate_count += duplicate_count # Увеличиваем общий счетчик дублей
# Если остался больше одного временного файла, выполняем финальное слияние
if len(temp_files) > 1:
logger.info("Завершающий этап слияния крупных оставшихся файлов") # Логируем финальный этап
unique_count, duplicate_count = merge_files(temp_files, output_file) # Финальное слияние временных файлов
total_unique_count += unique_count # Добавляем количество уникальных строк
total_duplicate_count += duplicate_count # Добавляем количество дублей
else:
# Если остался только один временный файл, переименовываем его в выходной файл
os.rename(temp_files[0], output_file) # Переименование файла
# Удаляем все оставшиеся временные файлы
for temp_file in temp_files:
if os.path.exists(temp_file): # Проверяем существование файла перед удалением
os.remove(temp_file) # Удаляем временный файл
logger.info("Все временные файлы удалены") # Логируем успешное удаление всех временных файлов
unique_count = original_count - total_duplicate_count # Рассчитываем количество уникальных строк
logger.info(f"Итоговые результаты: Уникальных строк: {unique_count}, Дублей удалено: {total_duplicate_count}") # Выводим результаты
return original_count # Возвращаем общее количество строк в исходном файле
except Exception as e:
logger.error(f"Ошибка при обработке файла: {e}") # Логируем ошибку при обработке файла
return 0 # Возвращаем 0 в случае ошибки
# Точка входа
if __name__ == '__main__':
tic = time.perf_counter() # Замеряем время начала выполнения программы
input_file = "large_random_emails.txt" # Исходный файл с данными
output_file = "output-sorted-unique.txt" # Выходной файл для сохранения результатов
original_count = sort_and_uniq_streaming(input_file, output_file) # Запускаем процесс сортировки и удаления дублей
tac = time.perf_counter() # Замеряем время завершения выполнения программы
logging.info(f"Всего обработано строк: {original_count}") # Логируем общее количество обработанных строк
logging.info(f"Удаление дублей и сортировка заняли {tac - tic:0.4f} секунд") # Логируем время выполнения программыМультипроцессорно-многопоточная версия, работает быстрее, но и к ресурсам требовательна по процу и памяти раз в 5-10 (пример отработки ".txt файл 100 миллионов строк, размером в 2GB (Ryzen 5600 4700mhz, 32GB DDR4 3600MHZ):
Скриншот отработки 300 гигового сгенерированного лога без дублей на 4.5 миллиарда строк, чем больше уникальных строк, тем ниже скорость обработки (AMD Ryzen 7 3700x, 64GB ОЗУ, 1TB NVME в Raid 1 из двух накопителей по 1TB, Linux Ubuntu 22.04):
main-multi.py:
Python:
# Импорт необходимых библиотек
import os # Для работы с операционной системой и файловой системой
import heapq # Для эффективного слияния отсортированных последовательностей
import time # Для измерения времени выполнения скрипта
import logging # Для ведения логов
import shutil # Для удаления файлов и директории TEMP
import uuid # Для генерации уникальных идентификаторов
from concurrent.futures import ProcessPoolExecutor, ThreadPoolExecutor, as_completed # Для параллельного выполнения задач
from colorlog import ColoredFormatter # Для создания цветных логов
# Настройка цветного логирования
formatter = ColoredFormatter(
"%(log_color)s%(asctime)s - %(levelname)s - %(message)s",
datefmt=None,
reset=True,
log_colors={
'DEBUG': 'cyan',
'INFO': 'green',
'WARNING': 'yellow',
'ERROR': 'red',
'CRITICAL': 'bold_red',
}
)
# Создание и настройка обработчика логов
handler = logging.StreamHandler() # Создаем обработчик для вывода логов в консоль
handler.setFormatter(formatter) # Устанавливаем форматтер для обработчика
logger = logging.getLogger() # Получаем объект логгера
logger.addHandler(handler) # Добавляем обработчик к логгеру
logger.setLevel(logging.INFO) # Устанавливаем уровень логирования
# Создание временной директории
temp_dir = os.path.join(os.getcwd(), 'TEMP') # Путь к временной директории в текущей рабочей директории
if not os.path.exists(temp_dir): # Если директория не существует
os.makedirs(temp_dir) # Создаем её
def create_temp_merged_file(temp_dir):
"""
Создает временный файл для слияния данных.
:param temp_dir: Путь к временной директории
"""
unique_filename = os.path.join(temp_dir, f"tempfile_{uuid.uuid4().hex}.tmp") # Генерируем уникальное имя файла
temp_merged_file = open(unique_filename, 'w', encoding='utf-8') # Открываем файл для записи
return temp_merged_file, unique_filename # Возвращаем объект файла и его имя
def heavy_computation(n):
"""
Выполняет тяжелое вычисление (для симуляции нагрузки, процентов на 5 по моим замерам увеличивает скорость обработки лога).
:param n: Число для вычислений
:return: Результат вычисления
"""
logger.debug(f"Запуск тяжелого вычисления с параметром: {n}")
result = 0
for i in range(n):
result += i * i # Выполняем сложение квадратов чисел
logger.debug(f"Результат тяжелого вычисления: {result}")
return result
def process_chunk_and_write_multiprocess(chunk, temp_dir):
"""
Обрабатывает чанк данных и записывает результат во временный файл.
:param chunk: Список строк для обработки
:param temp_dir: Путь к временной директории
:return: Имя созданного временного файла или None в случае ошибки
"""
try:
logger.info(f"Начало обработки чанка размером {len(chunk)} строк (процесс)")
heavy_computation(10000000) # Симуляция тяжелых вычислений
unique_items = set(chunk) # Убираем дубликаты на уровне чанка
sorted_chunk = sorted(unique_items) # Сортируем уникальные элементы
unique_filename = os.path.join(temp_dir, f"tempfile_{uuid.uuid4()}.tmp") # Генерируем уникальное имя файла
with open(unique_filename, 'w', encoding='utf-8') as temp_file:
temp_file.write("\n".join(sorted_chunk) + "\n") # Сохраняем только уникальные строки
return unique_filename
except Exception as e:
logger.error(f"Ошибка при обработке чанка: {e}")
return None
def merge_files_parallel(temp_files, output_file, num_threads=24):
"""
Выполняет параллельное слияние временных файлов.
:param temp_files: Список временных файлов для слияния
:param output_file: Имя выходного файла
:param num_threads: Количество потоков для использования
:return: (количество уникальных строк, количество дубликатов, имя выходного файла)
"""
try:
logger.info(f"Параллельное слияние {len(temp_files)} временных файлов с использованием {num_threads} потоков")
unique_count = 0
duplicate_count = 0
file_iters = []
try:
for temp_file in temp_files:
file_iters.append(open(temp_file, 'r', encoding='utf-8', errors='replace')) # Открываем все временные файлы
merged_iter = heapq.merge(*[iter(f) for f in file_iters]) # Создаем итератор для слияния
with open(output_file, 'w', encoding='utf-8', errors='replace') as outfile:
prev_line = None
for line in merged_iter:
line = line.strip()
if line != prev_line: # Если текущая строка отличается от предыдущей
outfile.write(line + '\n') # Записываем её в выходной файл
prev_line = line
unique_count += 1
else:
duplicate_count += 1 # Увеличиваем счетчик дубликатов
except Exception as e:
logger.error(f"Ошибка при слиянии файлов: {e}")
return 0, 0
finally:
for f in file_iters:
f.close() # Закрываем все открытые файлы
logger.info(f"Слияние завершено. Уникальных строк: {unique_count}, дублей удалено: {duplicate_count}")
return unique_count, duplicate_count, output_file
except Exception as e:
logger.error(f"Ошибка при параллельном слиянии файлов: {e}")
return 0, 0
def batch_merge(temp_files, batch_size, temp_dir, num_merge_processes=24):
"""
Выполняет пакетное слияние временных файлов.
:param temp_files: Список временных файлов
:param batch_size: Размер пакета для слияния
:param temp_dir: Путь к временной директории
:param num_merge_processes: Количество процессов для слияния
:return: (список объединенных файлов, общее количество уникальных строк, общее количество дубликатов)
"""
try:
logger.info(f"Начало пакетного слияния с размером пакета {batch_size}")
merged_files = []
total_unique_count = 0
total_duplicate_count = 0
with ProcessPoolExecutor(max_workers=num_merge_processes) as merge_executor:
futures = []
for i in range(0, len(temp_files), batch_size):
batch = temp_files[i:i + batch_size] # Формируем пакет файлов
logger.info(f"Слияние пакета с файлов {i + 1} по {min(i + batch_size, len(temp_files))}")
temp_merged_file, unique_filename = create_temp_merged_file(temp_dir)
temp_merged_file.close()
futures.append(merge_executor.submit(merge_files_parallel, batch, unique_filename))
for future in as_completed(futures):
unique_count, duplicate_count, temp_file = future.result() # Получаем результат слияния
if unique_count or duplicate_count:
merged_files.append(temp_file) # Добавляем временный файл в список
total_unique_count += unique_count
total_duplicate_count += duplicate_count
for temp_file in temp_files:
if os.path.exists(temp_file):
logger.info(f"Удаление временного файла: {temp_file}")
os.remove(temp_file) # Удаляем обработанные временные файлы
else:
logger.warning(f"Файл не найден для удаления: {temp_file}")
return merged_files, total_unique_count, total_duplicate_count
except Exception as e:
logger.error(f"Ошибка при пакетном слиянии: {e}")
return temp_files, 0, 0
def final_merge(temp_dir, output_file):
"""
Выполняет финальное слияние всех оставшихся временных файлов.
:param temp_dir: Путь к временной директории
:param output_file: Имя выходного файла
:return: (количество уникальных строк, количество удаленных дубликатов)
"""
logger.info(f"Финальная стадия слияния временных файлов из папки {temp_dir}.")
temp_files = [os.path.join(temp_dir, f) for f in os.listdir(temp_dir) if os.path.isfile(os.path.join(temp_dir, f))] # Список временных файлов для финального слияния
if len(temp_files) > 1: # Если файлов больше одного, запускаем слияние
unique_count, duplicate_count, output_file = merge_files_parallel(temp_files, output_file) # Параллельно сливаем файлы
elif len(temp_files) == 1: # Если остался только один файл
logger.info(f"Остался один файл. Переименование {temp_files[0]} в {output_file}")
os.rename(temp_files[0], output_file) # Переименовываем файл в выходной
unique_count, duplicate_count = 0, 0 # Устанавливаем нулевые значения для счетчиков
else:
logger.error("Не осталось временных файлов для слияния!")
return 0, 0 # Возвращаем нули в случае ошибки
logger.info(f"Финальное слияние завершено. Уникальных строк: {unique_count}, дублей удалено: {duplicate_count}")
try:
shutil.rmtree(temp_dir) # Удаляем временную директорию
logger.info(f"Временная папка {temp_dir} успешно удалена.")
except Exception as e:
logger.error(f"Ошибка при удалении временной папки {temp_dir}: {e}")
return unique_count, duplicate_count # Возвращаем количество уникальных строк и дубликатов
def read_and_process_chunks_multiprocess(input_file, chunk_size=2000000, num_processes=24):
"""
Читает входной файл по чанкам и обрабатывает их в многопроцессорном режиме.
:param input_file: Имя входного файла
:param chunk_size: Размер чанка (количество строк)
:param num_processes: Количество процессов для обработки
:return: (список временных файлов, общее количество прочитанных строк)
"""
temp_files = [] # Список для временных файлов
chunk = [] # Буфер для хранения чанка строк
original_count = 0 # Счетчик общего числа строк
logger.info(f"Чтение и обработка файла {input_file} в {num_processes} процессах...")
try:
with open(input_file, 'r', encoding='utf-8', errors='ignore') as infile: # Открываем входной файл для чтения
with ProcessPoolExecutor(max_workers=num_processes) as executor: # Создаем процессный пул для обработки чанков
futures = [] # Список задач для выполнения
for line in infile: # Читаем файл построчно
chunk.append(line.strip()) # Добавляем строку в чанк
original_count += 1 # Увеличиваем счетчик строк
if len(chunk) >= chunk_size: # Если чанк достиг нужного размера
futures.append(executor.submit(process_chunk_and_write_multiprocess, chunk, temp_dir)) # Отправляем чанк на обработку в пул процессов
chunk = [] # Очищаем чанк
if chunk: # Если остались строки после завершения цикла
futures.append(executor.submit(process_chunk_and_write_multiprocess, chunk, temp_dir)) # Обрабатываем оставшийся чанк
for future in as_completed(futures): # Ожидаем завершения всех задач
temp_file = future.result() # Получаем результат задачи
if temp_file:
temp_files.append(temp_file) # Добавляем временный файл в список
logger.info(f"Чтение и обработка завершены (процессами). Всего строк: {original_count}") # Логируем завершение обработки файла
except Exception as e:
logger.error(f"Ошибка при чтении файла (процессы): {e}") # Логируем ошибку в случае сбоя
return temp_files, original_count # Возвращаем список временных файлов и общее количество строк
def sort_and_uniq_streaming_multiprocess(input_file, output_file, chunk_size=2000000, batch_size=10, num_processes=24, num_merge_processes=24):
"""
Основная функция для сортировки и удаления дубликатов из большого файла с использованием многопроцессорной обработки.
:param input_file: Имя входного файла
:param output_file: Имя выходного файла
:param chunk_size: Размер чанка для обработки
:param batch_size: Размер пакета для слияния
:param num_processes: Количество процессов для обработки чанков
:param num_merge_processes: Количество процессов для слияния
:return: (общее количество строк, количество уникальных строк)
"""
logger.info(f"Старт обработки файла {input_file}...") # Логируем начало процесса
temp_files, original_count = read_and_process_chunks_multiprocess(input_file, chunk_size, num_processes) # Читаем и обрабатываем файл по чанкам
logger.info(f"Начинается пакетное слияние временных файлов...") # Логируем начало пакетного слияния
total_unique_count = 0 # Инициализируем счетчик всех уникальных строк
total_duplicate_count = 0 # Инициализируем счетчик всех дубликатов
while len(temp_files) > batch_size: # Пока временных файлов больше, чем размер пакета
temp_files, unique_count, duplicate_count = batch_merge(temp_files, batch_size, temp_dir, num_merge_processes) # Выполняем пакетное слияние
total_unique_count += unique_count # Обновляем общий счетчик уникальных строк
total_duplicate_count += duplicate_count # Обновляем общий счетчик дубликатов
unique_count, duplicate_count = final_merge(temp_dir, output_file) # Выполняем финальное слияние
total_unique_count += unique_count # Обновляем счетчик уникальных строк
total_duplicate_count += duplicate_count # Обновляем счетчик дубликатов
return original_count, unique_count # Возвращаем общее количество строк и количество уникальных строк
# Точка входа
if __name__ == '__main__': # Если этот файл запускается как основная программа
tic = time.perf_counter() # Начало отсчета времени
input_file = "input.txt" # Указываем импортируемый файл
output_file = "output.txt" # Указываем экспортируемый файл
original_count, unique_count = sort_and_uniq_streaming_multiprocess(input_file, output_file, num_processes=24, num_merge_processes=24) # Запускаем основную функцию обработки
tac = time.perf_counter() # Конец отсчета времени
logging.info(f"Все временные файлы удалены. Уникальных строк: {unique_count}, Дублей удалено (на всех этапах процессов слияния): {original_count - unique_count}") # Логируем результаты
logging.info(f"Всего обработано строк: {original_count}") # Логируем количество обработанных строк
logging.info(f"Удаление дублей и сортировка заняли {tac - tic:0.2f} секунд") # Логируем время выполнения
Последнее редактирование:
 На своем M2 накопителе я бы побоялся такие объемы прогонять. И не столкнулся бы с массой багов при обработке таких больших ULP =)
На своем M2 накопителе я бы побоялся такие объемы прогонять. И не столкнулся бы с массой багов при обработке таких больших ULP =)