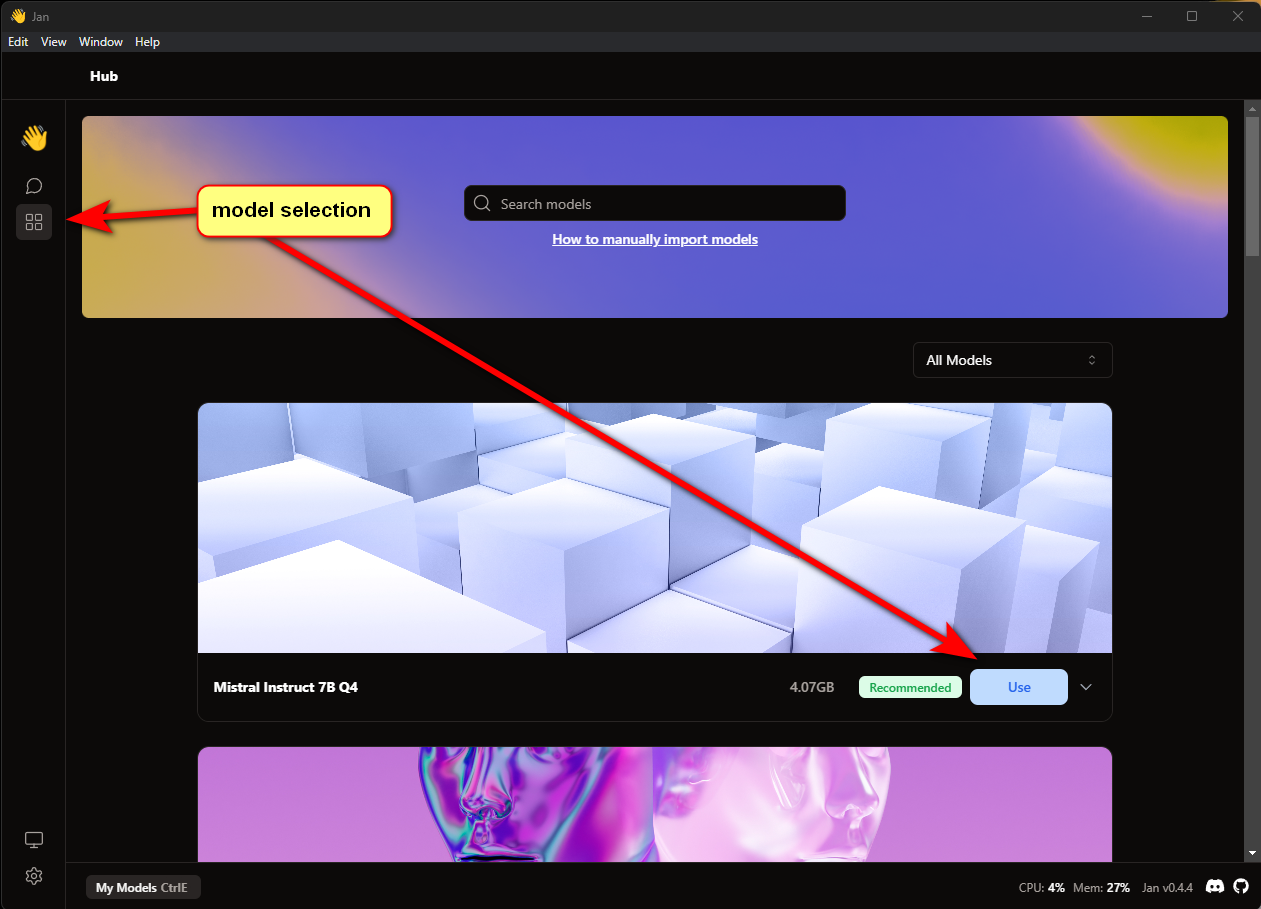
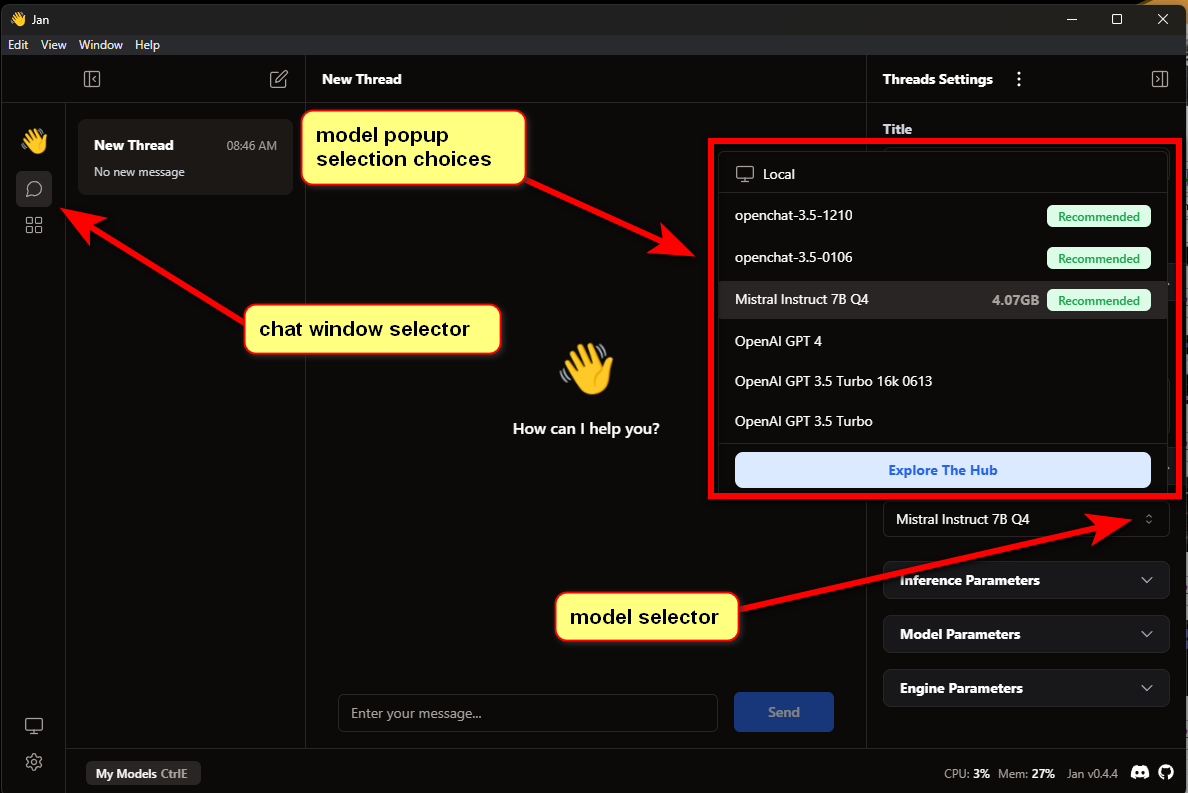
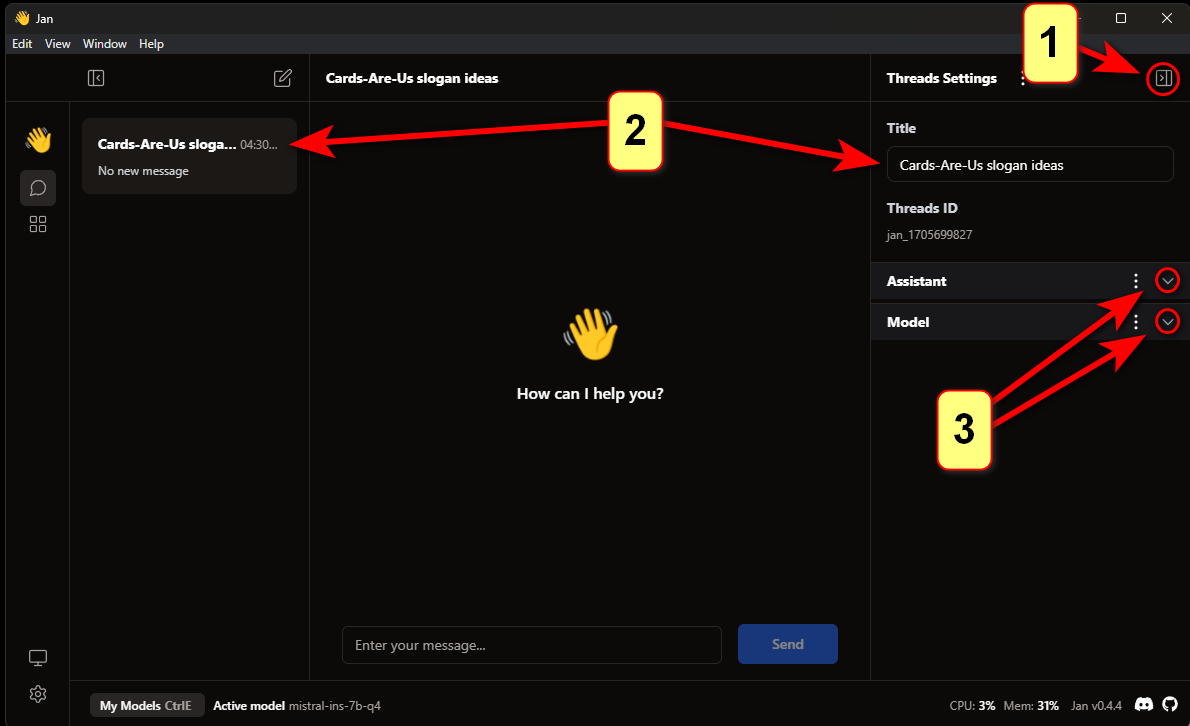
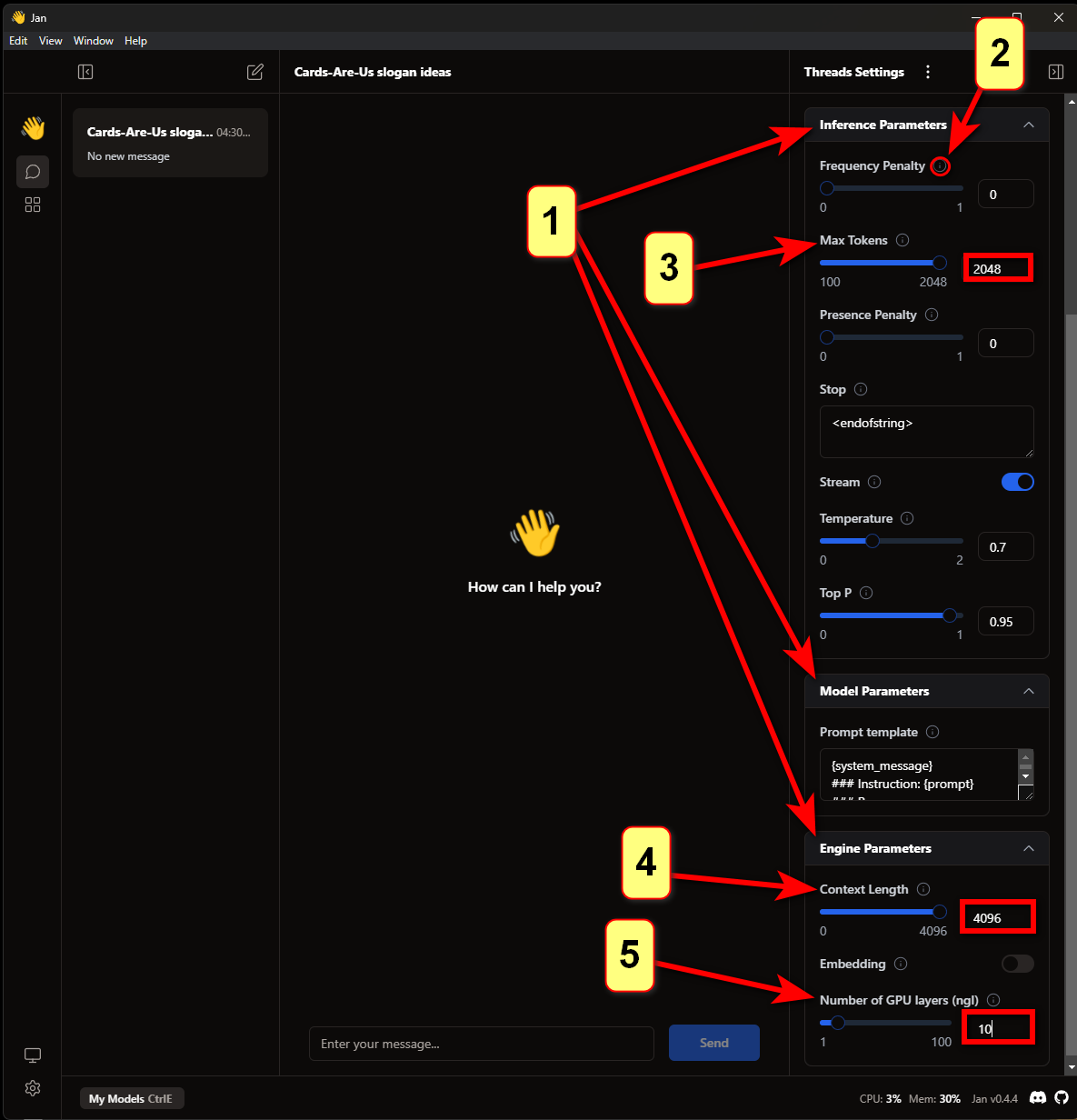
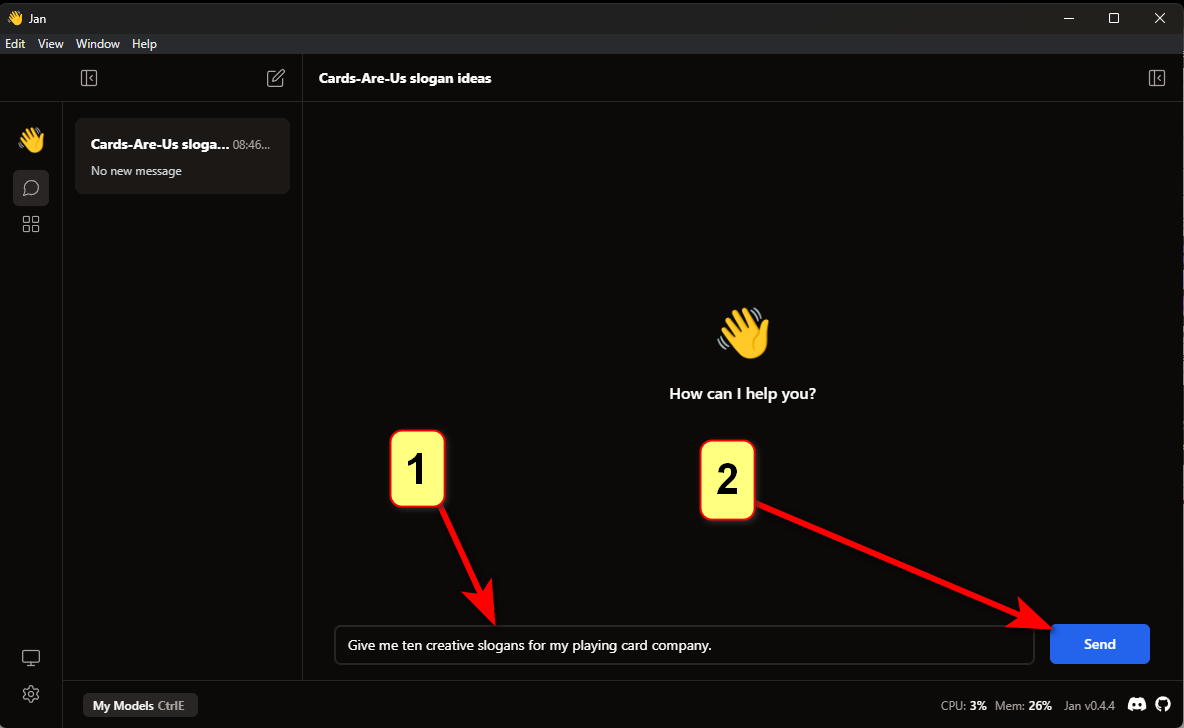
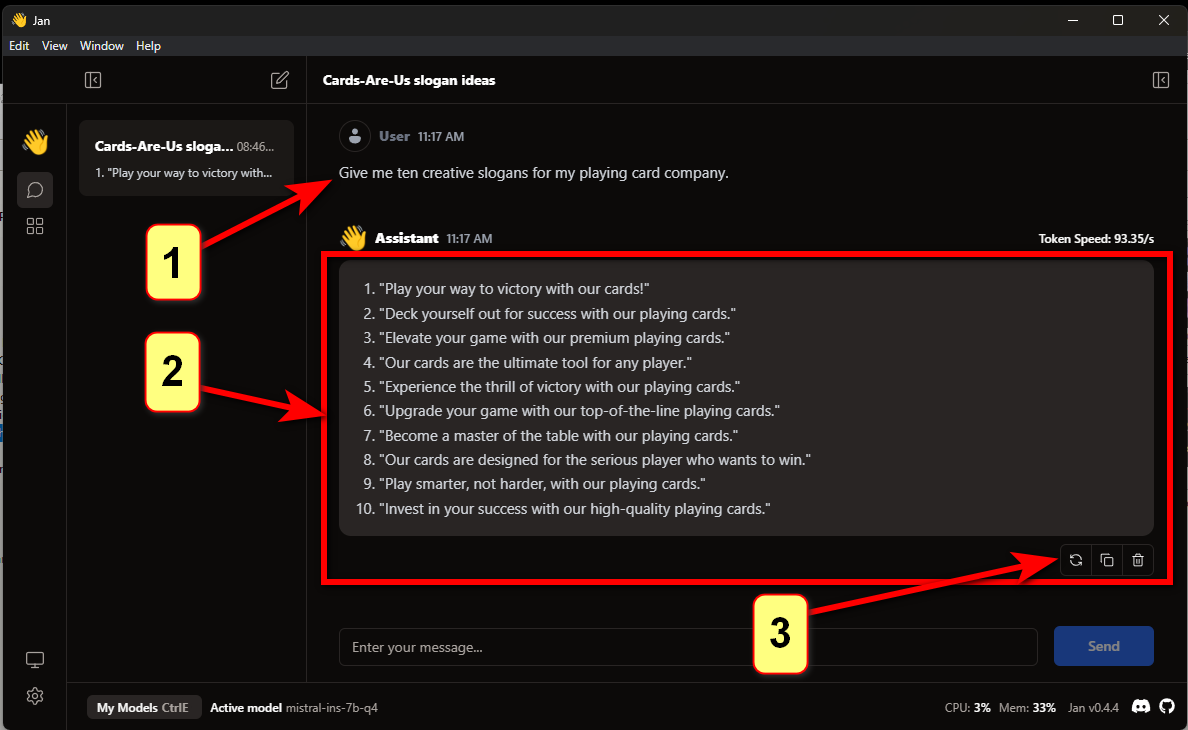
Приветствую всех, меня зовут Панда. Это мой первый пост.
Буду краток. Создание своей модели ИИ упростили до безобразия, но иногда кажется, что все мы капаемся в одном и том же, просто меняя шило на мыло. Сегодня я расскажу как развернуть локальный ИИ меньше чем за минуту и что с этим можно придумать. А так же дам список крутых моделей, которые упрощают жизнь разработчикам.
Маленькая предыстория.
Я познакомился с ИИ относительно недавно, когда начался бум на нейросети. С этого дня я понял, что я могу заняться тем, что давалось с трудом - программированием. Сейчас я пишу простые программы изучая темный лес блокчейна и мев. В погоне за автоматизацией я находил много разных моделей, их комбинации и потенциальные возможности - вплоть до полного контроля процессов ПК. Развернуть локально ИИ, сконфигурировать его модель на взаимодействие с bash и управлять через GUI интерфейс. Полет фантазии может быть безграничен, но дело в умениях.
Начнем со списка популярных ресурсов и их тезисное объяснение.
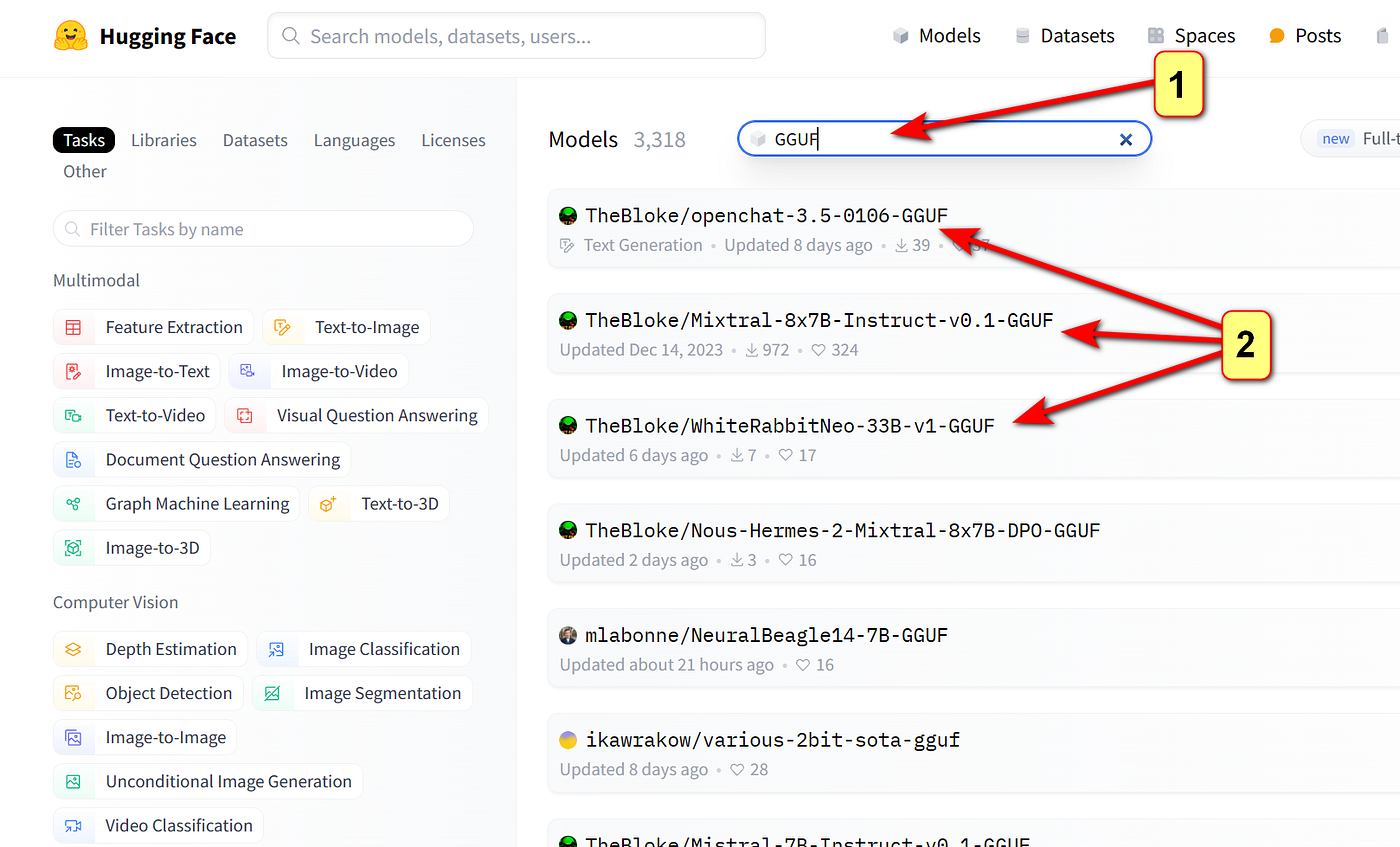
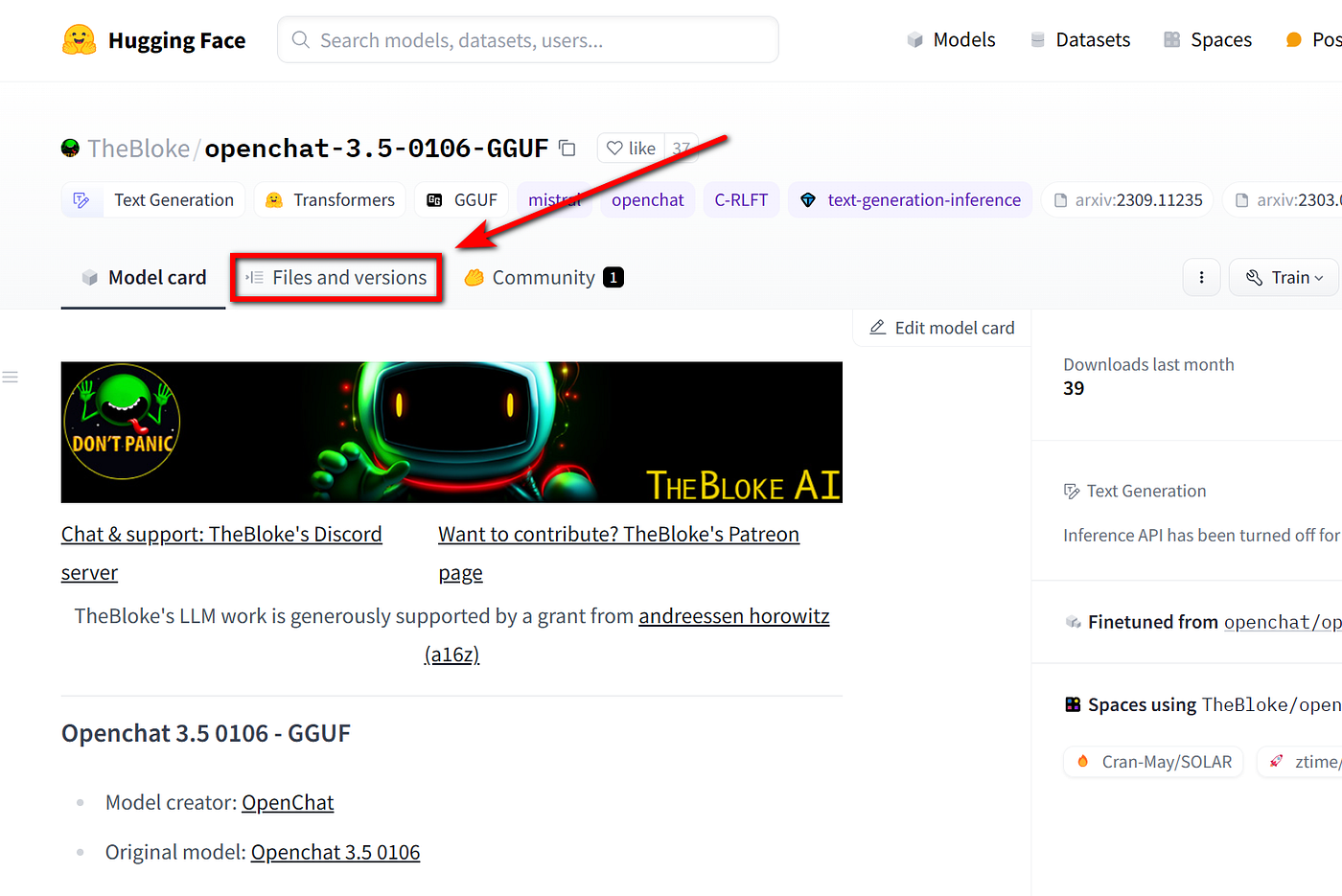
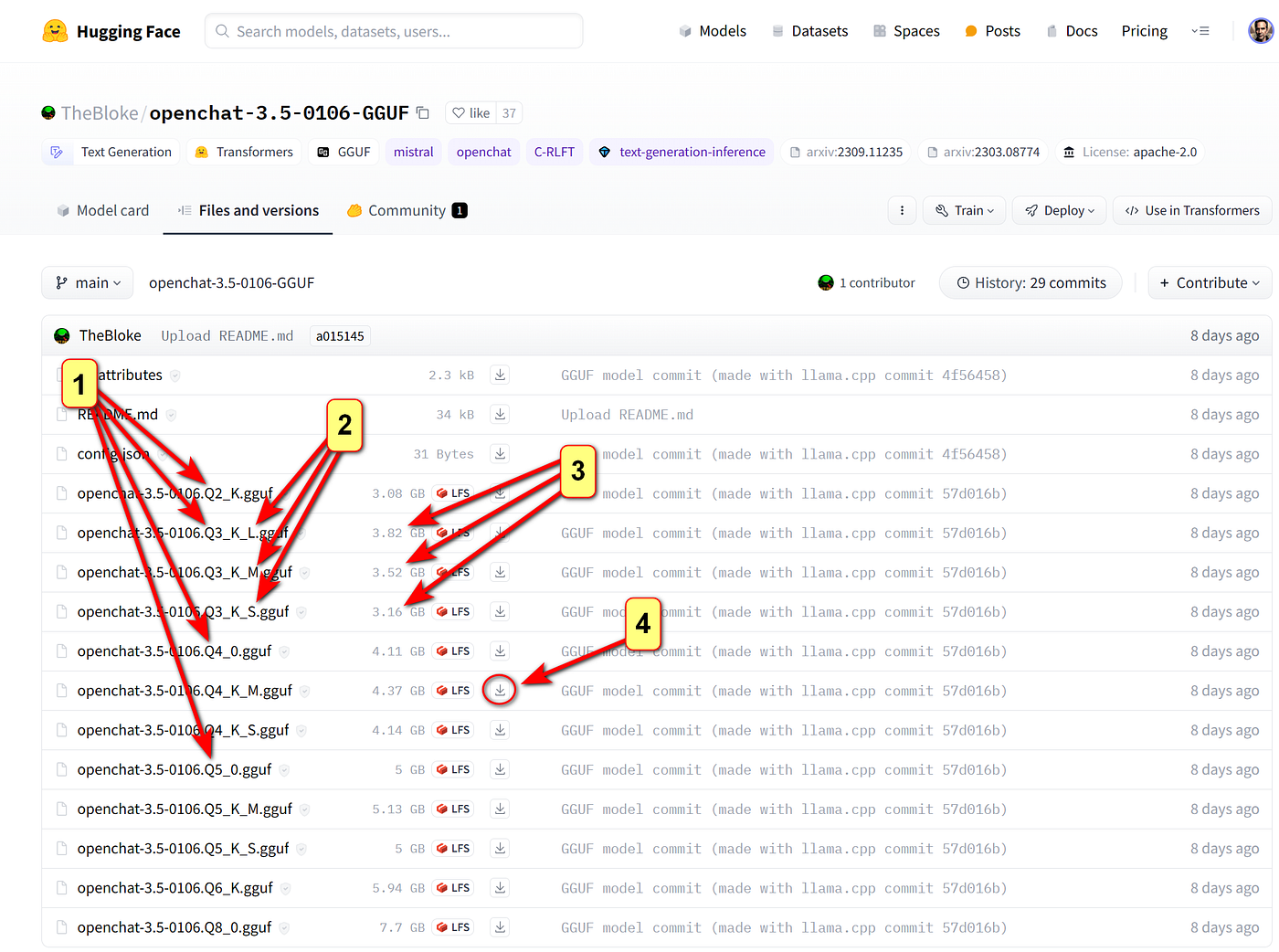
HuggingFace - популярный сервис в котором можно найти как готовые модели, развернутые на облаке, так и дата сеты, открытые конфигурации моделей. Сервис так же предоставляет создание своего облачного сервиса для обучения и тестирования моделей.
Vertex AI - Гугловский сервис который позволяет создавать, обучать и разворачивать свои модели.
LmStudio - сервис который позволяет локально развернуть модели нейросетей абсолютно бесплатно. Поддерживает популярные модели. Доступтно на MacOs.
RecurseChat - сервис для локального разворота ИИ. Сервис платный доступен только для владельцев Мак ( Дональст") ).
).
Coze.com - платформа для создания кастомных моделей с кучей встроенных плагинов, возможностью создавать свои действия, плагины и может синтезировать несколько ботов в один. Доступны бесплатно топовые версии чатгпт4 турбо 128т и возможность развернуть их в соц сетях, то есть сделать ботов. Телеграмм дискорд снэпчат и другие. Пользуюсь лично, создал своего бота для программирования. Встроенный парсинг страниц и возможность добавлять базу данных даже ОНЛАЙН страниц.
Flowgpt.com myshellapp.com character.ai - платформы для дрочеров)) . Шучу. Но чаще всего оно так и есть. На них собраны NSFW модели которые освобождены от цензуры. Можно встретить пародию на WormGpt но это просто кастомные боты, которые освобождены от ограничей. Очень ограничены и сверхмонетизированы.
Phind.com - недавно встретил эту нейросетку, функционал платный. Интегрируется с вашими ИДЕ и может захватывать все файлы проекта на анализ за один запрос. У них своя модель на 70б параметров, ничего такая. Удобно для devOPSOV которые парятся с кучей файлов.
Perplexity - интересный выбор для тех, кому нужен прямо таки широкий веб поиск. Есть платный контент и он того стоит. Реализованы 4 нейросетки, одна из которых сама перплексити. Как по мне лучший поисковый алгоритм на рынке, с точки зрения охвата веб поиска. Я думаю можно найти их апишку и интегрировать их поисковый алгоритм со своими нейросетками.
Replit.com - веб ИДЕ который интегрирован с ИИ. Можно сказать VSCode в веб интерфейсе, с ИИ, который имеет полный доступ к проекту. Выбор интересный, но мне не зашло.
Библиотеки для ИИ разработки и полезные штучки:
TensorFlow, LangChain - библиотеки и фреймворки для разработки, созданию и интеграции ИИ.
Stability.ai - с функционалом плохо знаком, но ресурс полезный для локального разворота ИИ.
Самые базовые и простые ресурсы, которыми я хотел поделиться и которые сам использую.
P.S. Я не претендую на истину в последней инстанции и моя терминалогия может быть в некоторых местах не корректной. Я энтузиаст и только начал свой путь в изучение темного леса, MEV стратегий и других прибыльных направлений. Так же я в поисках профессионалов и крутых кодеров, чтобы стать частью команды и зарабатывать деньги, используя наши знания. Я не обладаю передовыми знаниями в кодинге, но даже без них я уже пишу базовые простые арбитражные сканеры.
Для связи - panda404@onionmail.com
Буду краток. Создание своей модели ИИ упростили до безобразия, но иногда кажется, что все мы капаемся в одном и том же, просто меняя шило на мыло. Сегодня я расскажу как развернуть локальный ИИ меньше чем за минуту и что с этим можно придумать. А так же дам список крутых моделей, которые упрощают жизнь разработчикам.
Маленькая предыстория.
Я познакомился с ИИ относительно недавно, когда начался бум на нейросети. С этого дня я понял, что я могу заняться тем, что давалось с трудом - программированием. Сейчас я пишу простые программы изучая темный лес блокчейна и мев. В погоне за автоматизацией я находил много разных моделей, их комбинации и потенциальные возможности - вплоть до полного контроля процессов ПК. Развернуть локально ИИ, сконфигурировать его модель на взаимодействие с bash и управлять через GUI интерфейс. Полет фантазии может быть безграничен, но дело в умениях.
Начнем со списка популярных ресурсов и их тезисное объяснение.
HuggingFace - популярный сервис в котором можно найти как готовые модели, развернутые на облаке, так и дата сеты, открытые конфигурации моделей. Сервис так же предоставляет создание своего облачного сервиса для обучения и тестирования моделей.
Vertex AI - Гугловский сервис который позволяет создавать, обучать и разворачивать свои модели.
LmStudio - сервис который позволяет локально развернуть модели нейросетей абсолютно бесплатно. Поддерживает популярные модели. Доступтно на MacOs.
RecurseChat - сервис для локального разворота ИИ. Сервис платный доступен только для владельцев Мак ( Дональст
). Coze.com - платформа для создания кастомных моделей с кучей встроенных плагинов, возможностью создавать свои действия, плагины и может синтезировать несколько ботов в один. Доступны бесплатно топовые версии чатгпт4 турбо 128т и возможность развернуть их в соц сетях, то есть сделать ботов. Телеграмм дискорд снэпчат и другие. Пользуюсь лично, создал своего бота для программирования. Встроенный парсинг страниц и возможность добавлять базу данных даже ОНЛАЙН страниц.
Flowgpt.com myshellapp.com character.ai - платформы для дрочеров
)) . Шучу. Но чаще всего оно так и есть. На них собраны NSFW модели которые освобождены от цензуры. Можно встретить пародию на WormGpt но это просто кастомные боты, которые освобождены от ограничей. Очень ограничены и сверхмонетизированы.Phind.com - недавно встретил эту нейросетку, функционал платный. Интегрируется с вашими ИДЕ и может захватывать все файлы проекта на анализ за один запрос. У них своя модель на 70б параметров, ничего такая. Удобно для devOPSOV которые парятся с кучей файлов.
Perplexity - интересный выбор для тех, кому нужен прямо таки широкий веб поиск. Есть платный контент и он того стоит. Реализованы 4 нейросетки, одна из которых сама перплексити. Как по мне лучший поисковый алгоритм на рынке, с точки зрения охвата веб поиска. Я думаю можно найти их апишку и интегрировать их поисковый алгоритм со своими нейросетками.
Replit.com - веб ИДЕ который интегрирован с ИИ. Можно сказать VSCode в веб интерфейсе, с ИИ, который имеет полный доступ к проекту. Выбор интересный, но мне не зашло.
Библиотеки для ИИ разработки и полезные штучки:
TensorFlow, LangChain - библиотеки и фреймворки для разработки, созданию и интеграции ИИ.
Stability.ai - с функционалом плохо знаком, но ресурс полезный для локального разворота ИИ.
Самые базовые и простые ресурсы, которыми я хотел поделиться и которые сам использую.
P.S. Я не претендую на истину в последней инстанции и моя терминалогия может быть в некоторых местах не корректной. Я энтузиаст и только начал свой путь в изучение темного леса, MEV стратегий и других прибыльных направлений. Так же я в поисках профессионалов и крутых кодеров, чтобы стать частью команды и зарабатывать деньги, используя наши знания. Я не обладаю передовыми знаниями в кодинге, но даже без них я уже пишу базовые простые арбитражные сканеры.
Для связи - panda404@onionmail.com