Пожалуйста, обратите внимание, что пользователь заблокирован
Автор student / мой_телеграмм_канал
Источник: https://xss.pro
Приветствую, уже на пятой части. Решил, что пора начать ознакамливаться с парсингом") Это введение в recon с помощью парсера. Рассматривать будем следующее:
Это введение в recon с помощью парсера. Рассматривать будем следующее:
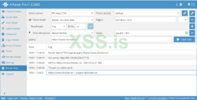
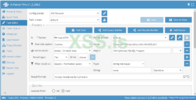
Инструмент A-Parser

1 - выбор потоков для задачи. Значение зависит от лимита прокси.
2 - пресет. Тут вы можете добавлять кастомные пресеты или же выгружать их.
3 - парсеры. Тут содержатся все встроенные парсеры. К слову их более 110
4 - формат результата. Тут вы указываете в каком формате выводить результат.
5 - запрос. Вы можете подавать запрос из файла или прямо в окне парсера.
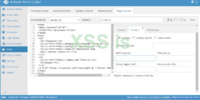
Есть различные опции, которые зависят от выбранного парсера. Из интересных могу отметить bypass cloudflare, разгадывание капчи, поддержка хромиума

В разделе Parsers Editor вы можете создать собственные парсеры, если знакомы с JavaScript.

В разделе Parser Test вы можете проводить тестовый парсинг с подробным выводом.

Парсинг при помощи Python
Чтобы разобраться в этом, нужно знать немного теории о http. Чтобы получить информацию от сервера МЫ отправляем заголовки такие как User-Agent и Accept(запрашиваем тип контента). Сервер в ответ возвращает нам html разметку. Сразу приступим к практике. К примеру у нас есть ресурс https://bsaber.com/wp-json/wp/v2/users из url уже понятно, что это сайт на wordpress. К примеру мы хотим собрать информацию о пользователях из JSON, то есть использовать будем ключ и значение. Давай взглянем на JSON поближе:

Мы видим, что значение ключа slug - это юзернейм. Значит все, что нам нужно это получить содержимое в формате JSON и просто обращаться как к словарю, запрашивать значение slug. И просто сохранять юзернеймы. Для начала узнаем значение заголовка Accept.

Accept: application/json
Приступим к созданию парсера юзернеймов для WP на python.

Импортируем библиотеку requests, которая поможет нам работать с веб приложением и json. Далее записываем в переменные значение User-Agent и Accept. Создаем словарик headers. Остается отправить get запрос и получить json.
output:
Это словарик. А значит мы можем обращаться по ключу 'slug'.
Можно еще сделать иначе
[x] - это номер элемента в списке, ['slug'] - это ключ элемента x. Как только появляется ошибка останавливаем цикл. Вроде все понятно. Но лучше использовать первый вариант.
Готовый вариант:
Можно еще добавить, чтобы юзер агенты подгружались из файла, добавить поддержку proxy, добавить подгрузку таргетов из файла, добавить, чтобы в случае ответа от сервера 400x перебручивало с другой прокси. Короче долго еще оптимизировать надо этот скрипт, чтобы его было не стыдно показать. Можно еще не создавать переменную data, а хранить json в переменной response:
response = requests.get(target, headers=headers).json()
Решение стандартных задач
1. Спарсить все email адреса с веб страничек. Допустим есть таргет https://www.shodan.io/ и нам нужно спарсить все емейлы из html разметки. Вот как это можно реализовать на python.
Импортируем две библиотеки requests и re, чтобы искать email по регулярному выражению. В переменную target записываем сайт с которого нужно получить емейлы, далее отправляем get запрос и записываем, как text. Если не указать метод text, то вы просто получите код 200 (ответ от сервера). Если постоянно обращаться к ресурсу, то можно получить временную блокировку поэтому сохраним полученную разметку в html файл.
Используем конструкцию with, потому что она удобна тем, что не надо прописывать close, т.к она автоматически закрывает файл. Теперь вся разметка хранится в переменной f. Открываем и читаем разметку.
Используем re.findall для поиска емейлов по регулярному выражению. Перезаписываем переменную email, как set(множества), чтобы не было дубликатов. Выводим полученные емейлы на экран.

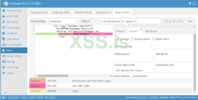
Решение на A-Parser:

Обворачиваем регулярное выражение в скобки, иначе не сработает, т.к A-Parser требует группировку. Мы использовали Parse custom result и записывали емейлы в переменную $email

Удобно правда? Намного лучше, чем python, тут даже поддержка прокси есть и многопоточность. Ну я показал, как реализовать это на A-Parser, но на самом деле в встроенных парсерах уже есть. Вот если надо готовое решение:

На вход подавать файл с ресурсами в формате https://domain.com
2. Спарсить информацию с известного html тэга.

Допустим мы хотим получить номер телефона. Для этого используем следующее регулярное выражение:

3. Получить пользователей WordPress с JSON.
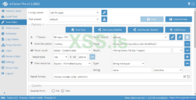
На python разобрал задачку, там было неудобно и слишком много телодвижений. Сейчас покажу как можно работать с JSON на A-Parser:

Кстати, если регулярное выражение неверное, то будет ошибка:

Также, в A-Parser есть инструмент для тестов регулярного выражения:

Извлечем кодировку utf-8

4. Потренируемся на настоящем таргете. Таргет предоставил grader спасибо!
К примеру у нас есть доступ в кастомную панель администратора.

В админке есть письма от клиентов. В таком формате:

Наша задача сп*здить емейлы, пока никого нет Посмотрим что меняется при переходе в другое письмо:
585
меняется только cid. Будем собирать email и номер телефона клиента.
Чуть потыкав админку, я понял, что айдишников не более 600. Значит будем перебирать с 1 до 600. Мыла будем собирать стандартным пресетом из A-Parser, а номера телефонов с помощью регулярного выражения, которое я составил в A-Parser.

Теперь осталось парсер научить заходить в админку. Добавляем опцию Cookies. И прописываем Cookie в формате key=value. Если надо несколько кук указать, то формат такой key=value; key=value
Куки копируем прямо из браузера


{num:600:0} это макросы подстановок. От 600 идем к 0. Кстати, они не работают в режиме тестового парсинга. Поэтому сразу перешел HTML:EmailExtractor
Всего удалось извлечь 541 емейлов.
Теперь самое время спарсить номера телефонов. Но беда. Предыдущая регулярка не сработала. Хз почему. Я сделал новую...

Далее нужно отфильтровать, чтобы исключить none из результатов.

Надеюсь вам понравился материал, который я для вас подготовил. Для богатых коши в подписи
Источник: https://xss.pro
Приветствую, уже на пятой части. Решил, что пора начать ознакамливаться с парсингом
Это введение в recon с помощью парсера. Рассматривать будем следующее:- Инструмент A-Parser
- Парсинг при помощи Python
- Решение стандартных задач
Инструмент A-Parser
1 - выбор потоков для задачи. Значение зависит от лимита прокси.
2 - пресет. Тут вы можете добавлять кастомные пресеты или же выгружать их.
3 - парсеры. Тут содержатся все встроенные парсеры. К слову их более 110
4 - формат результата. Тут вы указываете в каком формате выводить результат.
5 - запрос. Вы можете подавать запрос из файла или прямо в окне парсера.
Есть различные опции, которые зависят от выбранного парсера. Из интересных могу отметить bypass cloudflare, разгадывание капчи, поддержка хромиума
В разделе Parsers Editor вы можете создать собственные парсеры, если знакомы с JavaScript.
В разделе Parser Test вы можете проводить тестовый парсинг с подробным выводом.
Парсинг при помощи Python
Чтобы разобраться в этом, нужно знать немного теории о http. Чтобы получить информацию от сервера МЫ отправляем заголовки такие как User-Agent и Accept(запрашиваем тип контента). Сервер в ответ возвращает нам html разметку. Сразу приступим к практике. К примеру у нас есть ресурс https://bsaber.com/wp-json/wp/v2/users из url уже понятно, что это сайт на wordpress. К примеру мы хотим собрать информацию о пользователях из JSON, то есть использовать будем ключ и значение. Давай взглянем на JSON поближе:
Мы видим, что значение ключа slug - это юзернейм. Значит все, что нам нужно это получить содержимое в формате JSON и просто обращаться как к словарю, запрашивать значение slug. И просто сохранять юзернеймы. Для начала узнаем значение заголовка Accept.
Bash:
curl -I https://bsaber.com/wp-json/wp/v2/users | grep "Content-Type"Accept: application/json
Приступим к созданию парсера юзернеймов для WP на python.
Импортируем библиотеку requests, которая поможет нам работать с веб приложением и json. Далее записываем в переменные значение User-Agent и Accept. Создаем словарик headers. Остается отправить get запрос и получить json.
Python:
import requests
import json
accept = "application/json"
user_agent = "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.61 Safari/537.36"
headers = {"Accept": accept,
"User-Agent": user_agent
}
target = "https://bsaber.com/wp-json/wp/v2/users"
response = requests.get(target, headers=headers)
data = response.json()
print(data)
Python:
[{'id': 202208, 'name': '[xavier]', 'url': '', 'description': 'Hi My name is Robert. I am From Beautiful Bc Canada :)\xa0 Long time player and new to the mapping scene', 'link': 'https://bsaber.com/members/rippinrob/', 'slug': 'rippinrob', 'avatar_urls': {'24': 'https://bsaber.com/wp-content/uploads/avatars/202208/602863e4c40c2-bpthumb.jpg', '48': 'https://bsaber.com/wp-content/uploads/avatars/202208/602863e4c40c2-bpthumb.jpg', '96': 'https://bsaber.com/wp-content/uploads/avatars/202208/602863e49c78c-bpfull.jpg'}, 'meta': [], '_links': {'self': [{'href': 'https://bsaber.com/wp-json/wp/v2/users/202208'}], 'collection': [{'href': 'https://bsaber.com/wp-json/wp/v2/users'}]}}, {'id': 400641, 'name': '1stAfterHundred', 'url': '', 'description': '', 'link': 'https://bsaber.com/members/1stafterhundred/', 'slug': '1stafterhundred', 'avatar_urls': {'24': 'https://bsaber.com/wp-content/uploads/avatars/400641/6164bb64b6486-bpthumb.jpg', '48': 'https://bsaber.com/wp-content/uploads/avatars/400641/6164bb64b6486-bpthumb.jpg', '96': 'https://bsaber.com/wp-content/uploads/avatars/400641/6164bb64a240f-bpfull.jpg'}, 'meta': [], '_links': {'self': [{'href': 'https://bsaber.com/wp-json/wp/v2/users/400641'}], 'collection': [{'href': 'https://bsaber.com/wp-json/wp/v2/users'}]}}, {'id': 1910, 'name': 'AaltopahWi', 'url': 'https://beatsaver.com/profile/4284269', 'description': 'Piece of radioactive cardboard', 'link': 'https://bsaber.com/members/aaltopahwi/', 'slug': 'aaltopahwi', 'avatar_urls': {'24': 'https://bsaber.com/wp-content/uploads/avatars/1910/6240e9a5d1f28-bpthumb.png', '48': 'https://bsaber.com/wp-content/uploads/avatars/1910/6240e9a5d1f28-bpthumb.png', '96': 'https://bsaber.com/wp-content/uploads/avatars/1910/6240e9a5a4636-bpfull.png'}, 'meta': [], '_links': {'self': [{'href': 'https://bsaber.com/wp-json/wp/v2/users/1910'}], 'collection': [{'href': 'https://bsaber.com/wp-json/wp/v2/users'}]}}, {'id': 132126, 'name': 'aCake', 'url': 'https://discord.gg/eaDRbZY8aG', 'description': "<strong>Hey there!</strong>\r\n\r\nWe're Alex and Ava, otherwise known as aCake! We have been mapping since June 2020 and doing commissions since November 2020!\r\n\r\nGet ahold of us on discord, username aCake#0202\r\n\r\n**<b>Formally known as Alekcake**</b>", 'link': 'https://bsaber.com/members/acake/', 'slug': 'acake', 'avatar_urls': {'24': 'https://bsaber.com/wp-content/uploads/avatars/132126/61838f417c2e9-bpthumb.jpg', '48': 'https://bsaber.com/wp-content/uploads/avatars/132126/61838f417c2e9-bpthumb.jpg', '96': 'https://bsaber.com/wp-content/uploads/avatars/132126/61838f4165eaf-bpfull.jpg'}, 'meta': [], '_links': {'self': [{'href': 'https://bsaber.com/wp-json/wp/v2/users/132126'}], 'collection': [{'href': 'https://bsaber.com/wp-json/wp/v2/users'}]}}, {'id': 307564, 'name': 'Acubens', 'url': '', 'description': 'I map yes', 'link': 'https://bsaber.com/members/Acubens/', 'slug': 'Acubens', 'avatar_urls': {'24': 'https://bsaber.com/wp-content/uploads/avatars/307564/64de115fb7bb0-bpthumb.jpg', '48': 'https://bsaber.com/wp-content/uploads/avatars/307564/64de115fb7bb0-bpthumb.jpg', '96': 'https://bsaber.com/wp-content/uploads/avatars/307564/64de115fa2330-bpfull.jpg'}, 'meta': [], '_links': {'self': [{'href': 'https://bsaber.com/wp-json/wp/v2/users/307564'}], 'collection': [{'href': 'https://bsaber.com/wp-json/wp/v2/users'}]}}, {'id': 636, 'name': 'aggrogahu', 'url': '', 'description': 'I hate meta and I map whatever flows to me.', 'link': 'https://bsaber.com/members/aggrogahu/', 'slug': 'aggrogahu', 'avatar_urls': {'24': 'https://bsaber.com/wp-content/uploads/avatars/636/5c3fa60e8c059-bpthumb.jpg', '48': 'https://bsaber.com/wp-content/uploads/avatars/636/5c3fa60e8c059-bpthumb.jpg', '96': 'https://bsaber.com/wp-content/uploads/avatars/636/5c3fa60e8a2ab-bpfull.jpg'}, 'meta': [], '_links': {'self': [{'href': 'https://bsaber.com/wp-json/wp/v2/users/636'}], 'collection': [{'href': 'https://bsaber.com/wp-json/wp/v2/users'}]}}, {'id': 467, 'name': 'Agoza', 'url': 'https://www.twitch.tv/ag0za', 'description': "A Malaysian streamer with VR play space of about 2m x 1.8m. Using both Oculus & SteamVR interchangeably along my trusted Oculus Rift, I connect with people who have passion to get better at Beat Saber. Ignore me on Easy, Normal & Hard mode leaderboards; I just don't bother turning on No Fail while play-testing. You can think of it as target practice. Snipe me off top 10 if you see me.", 'link': 'https://bsaber.com/members/agoza/', 'slug': 'agoza', 'avatar_urls': {'24': 'https://bsaber.com/wp-content/uploads/avatars/467/5b468814b7941-bpthumb.jpg', '48': 'https://bsaber.com/wp-content/uploads/avatars/467/5b468814b7941-bpthumb.jpg', '96': 'https://bsaber.com/wp-content/uploads/avatars/467/5b468814b54c9-bpfull.jpg'}, 'meta': [], '_links': {'self': [{'href': 'https://bsaber.com/wp-json/wp/v2/users/467'}], 'collection': [{'href': 'https://bsaber.com/wp-json/wp/v2/users'}]}}, {'id': 206165, 'name': 'Alice', 'url': '', 'description': 'https://scoresaber.com/u/76561198038084750', 'link': 'https://bsaber.com/members/alice/', 'slug': 'alice', 'avatar_urls': {'24': 'https://bsaber.com/wp-content/uploads/avatars/206165/60d57f7c09bde-bpthumb.png', '48': 'https://bsaber.com/wp-content/uploads/avatars/206165/60d57f7c09bde-bpthumb.png', '96': 'https://bsaber.com/wp-content/uploads/avatars/206165/60d57f7be310b-bpfull.png'}, 'meta': [], '_links': {'self': [{'href': 'https://bsaber.com/wp-json/wp/v2/users/206165'}], 'collection': [{'href': 'https://bsaber.com/wp-json/wp/v2/users'}]}}, {'id': 322655, 'name': 'AllieCatVR', 'url': '', 'description': '', 'link': 'https://bsaber.com/members/alliecatvr/', 'slug': 'alliecatvr', 'avatar_urls': {'24': 'https://bsaber.com/wp-content/uploads/avatars/322655/61ecc61dab667-bpthumb.png', '48': 'https://bsaber.com/wp-content/uploads/avatars/322655/61ecc61dab667-bpthumb.png', '96': 'https://bsaber.com/wp-content/uploads/avatars/322655/61ecc61d8cb01-bpfull.png'}, 'meta': [], '_links': {'self': [{'href': 'https://bsaber.com/wp-json/wp/v2/users/322655'}], 'collection': [{'href': 'https://bsaber.com/wp-json/wp/v2/users'}]}}, {'id': 161260, 'name': 'Alphabeat', 'url': '', 'description': '', 'link': 'https://bsaber.com/members/alphabeat/', 'slug': 'alphabeat', 'avatar_urls': {'24': 'https://bsaber.com/wp-content/uploads/avatars/161260/5f5121bfa935f-bpthumb.png', '48': 'https://bsaber.com/wp-content/uploads/avatars/161260/5f5121bfa935f-bpthumb.png', '96': 'https://bsaber.com/wp-content/uploads/avatars/161260/5f5121bf89ea0-bpfull.png'}, 'meta': [], '_links': {'self': [{'href': 'https://bsaber.com/wp-json/wp/v2/users/161260'}], 'collection': [{'href': 'https://bsaber.com/wp-json/wp/v2/users'}]}}]
Process finished with exit code 0Это словарик. А значит мы можем обращаться по ключу 'slug'.
Python:
for username in data:
print(username['slug'])
Python:
for x in range(0,1000):
try:
print(data[x]['slug'])
except:
breakГотовый вариант:
Python:
import requests
import json
accept = "application/json"
user_agent = "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.61 Safari/537.36"
headers = {"Accept": accept,
"User-Agent": user_agent
}
target = "https://bsaber.com/wp-json/wp/v2/users"
response = requests.get(target, headers=headers)
data = response.json()
print(data[0]['slug'])response = requests.get(target, headers=headers).json()
Решение стандартных задач
1. Спарсить все email адреса с веб страничек. Допустим есть таргет https://www.shodan.io/ и нам нужно спарсить все емейлы из html разметки. Вот как это можно реализовать на python.
Python:
import requests
import re
target='https://www.shodan.io/'
response = requests.get(target).text
Python:
with open('index.html', 'w') as f:
f.write(response)
Python:
file = open('index.html')
page = file.read()
Python:
emails=re.findall('\w+@\w+.\w+', page)
emails=set(emails)
print(emails)Решение на A-Parser:
Обворачиваем регулярное выражение в скобки, иначе не сработает, т.к A-Parser требует группировку. Мы использовали Parse custom result и записывали емейлы в переменную $email
Удобно правда? Намного лучше, чем python, тут даже поддержка прокси есть и многопоточность. Ну я показал, как реализовать это на A-Parser, но на самом деле в встроенных парсерах уже есть. Вот если надо готовое решение:
На вход подавать файл с ресурсами в формате https://domain.com
2. Спарсить информацию с известного html тэга.
Допустим мы хотим получить номер телефона. Для этого используем следующее регулярное выражение:
Код:
phone">(.*)</h1>3. Получить пользователей WordPress с JSON.
На python разобрал задачку, там было неудобно и слишком много телодвижений. Сейчас покажу как можно работать с JSON на A-Parser:
Кстати, если регулярное выражение неверное, то будет ошибка:
Также, в A-Parser есть инструмент для тестов регулярного выражения:
Извлечем кодировку utf-8
4. Потренируемся на настоящем таргете. Таргет предоставил grader спасибо!
К примеру у нас есть доступ в кастомную панель администратора.
В админке есть письма от клиентов. В таком формате:
Наша задача сп*здить емейлы, пока никого нет
Посмотрим что меняется при переходе в другое письмо:585
меняется только cid. Будем собирать email и номер телефона клиента.
| <h5>From: Wolfgangthiele30@gmx.net | |
|
Код:
(.+?)<h5>Iphone:(.+?)<Теперь осталось парсер научить заходить в админку. Добавляем опцию Cookies. И прописываем Cookie в формате key=value. Если надо несколько кук указать, то формат такой key=value; key=value
Куки копируем прямо из браузера
{num:600:0} это макросы подстановок. От 600 идем к 0. Кстати, они не работают в режиме тестового парсинга. Поэтому сразу перешел HTML:EmailExtractor
Всего удалось извлечь 541 емейлов.
Теперь самое время спарсить номера телефонов. Но беда. Предыдущая регулярка не сработала. Хз почему. Я сделал новую...
Код:
<h5>Iphone:(.*[0-9])(.*<span)Далее нужно отфильтровать, чтобы исключить none из результатов.
Надеюсь вам понравился материал, который я для вас подготовил. Для богатых коши в подписи