Всем привет! Надеюсь ваши праздники удались! Возвращаемся к работе!
Сегодня мы разберемся как редактировать машинный код!
Что это значит?
Мы будем редактировать игровой код таким образом, чтобы игра делала то что нужно нам!
Не стоит волноваться если за всю свою жизнь вы не написали ни строчки кода, так как перед тем как мы перейдем к практике мы рассмотрим минимально необходимую теорию.
Для начала разделим наш процесс на части:
1) Найти релевантный участок кода
2) Изменить код
3) Проверить, все ли работает так как мы задумали
Если вы вспомните наши предыдущие уроки, то мы делали что-то похожее:
1) Искали значение в памяти
2) Редактировали его
3) Проверяли результат
Похоже ли редактирование кода на редактирование значений? Отчасти да, но
в случае с редактированием значений в памяти нам нужно было лишь найти нужный адрес
и перезаписать исходный вариант в нужном формате и допустимых пределах.
Редактировать машинный же код значительно сложнее. Почему?
1) Необходимо более глубокое понимание принципов сканирования памяти, чтобы точно определить нужный участок кода
2) Необходимо понимание ассемблера (представление команда процесса доступным человеку языком) на базовым уровне
Для начала окунемся в небольшую теорию и рассмотрим, что же такое ассемблерный код, а уже потом посмотрим, как же его редактировать:
1) Ваш компьютер имеет CPU (процессор)
2) CPU способен запускать код
3) В зависимости от архитектуры вашего CPU определяется то, какой код можно запустить на вашем ПК (или не пк)
Современные ПК, консоли, и т.п. имеют архитектуры x86 / x64 (именно на них будет наш фокус).
Различные смартфоны / портативные консоли / планшеты часто имеют архитектуру ARM. (Она в чем то более современная, энергоэффективная, заточенная на низкое потребление энергии чтобы продлить цикл автономной работы портативных устройств)
Существуют также архитектуры M1 / M2 - вариации ARM от APPLE.
Если например у вас будет старая игра, то вы вряд ли сможете запустить ее на современной архитектуре, т.к. логика работы / набор инструкций и т.п. может отличаться, и для корректной работы вам придется запускать эмулятор, который как бы "воссоздаст" необходимую архитектуру виртуально.
Также необходимо отметить еще одну архитектуру - PowerPC. Возможно, когда-нибудь вам придет идея поломать консоли по типу Xbox, Nintendo, Wii (если мы говорим о прошлых поколениях, т.к. современные имеют часто архитектуру x64).
Зачем нам это знать? Спросите вы.
В зависимости от архитектуры будет отличаться и язык ассемблера.
Но при этом - если у вас есть базовое и концептуальное понимание, разобраться в любой архитектуре не должно стать для вас проблемой.
Вернемся к x86 / x64!
Как вы можете вспомнить из прошлых уроков:

Что мы знаем?
- В виртуальной памяти существуют наш скопированный образ (SAMPLE.EXE + необходимые DLL) = STATIC CODE
- Существуют выделенные объекты (аллоцированные / Alocated) = DATA

Что мы знаем о наших .EXE / .DLL?
Что каждый из них имеет две секции: DATA и CODE.
DATA - набор из нулей и единиц, который можно интерпретировать различным образом: массив байт, отдельные элементы которого представляют булевы (переключатели), целые числа, числа с плавающей точкой, строки и все остальные типы данных.
Сегодня наше внимание - CODE.
Это все тот же набор из нулей и единиц, но для восприятия кода нам нужно изменить нашу ментальную модель.
Этот набор нулей и единиц также можно группировать в массив байт - но только теперь мы получаем не данные, а набор машинных инструкций! Не беспокойтесь, если на примере ниже вы что-то из этого кода не поймете. Это нормально.
Все что вам нужно сейчас понимать - отдельная группа байт может быть интерпретирована как инструкция (набор инструкций).
То что вы видите слева - это машинный код (raw data), то что вы видите справа - и есть ассемблерный код.
Примерно по такому принципу работают любые инспекторы кода, т.е. они конвертируют "кашу" из машинных кодов в ассемблерный листинг, более удобный для нашего восприятия.
Как это нам поможет?
Чтобы изменить логику нам не нужно работать на уровне машинного кода в сыром виде.
Мы находим участок памяти - получаем сырой вид (столбец слева) - с помощью специальных инструментов конвертируем в удобночитаемый ассемблерный листинг - редактируем на уровне ассемблера - конвертируем полученный результат с исправленной логикой в сырой вид (машинный) - перезаписываем участок.
Для примера рассмотрим небольшой игровой код сгенерированный с помощью CHAT GPT:
Если бы мы захотели изменить угол атаки, мы бы пришли к поиску значения ANGLE DB в памяти и изменили значение переменной.
А как сделать это другим способом?
Если мы хотим изменить угол атаки, не меняя значение переменной в памяти, мы можем использовать метод, называемый "перехват виртуальных функций" (virtual function hooking). Этот метод позволяет нам перехватить вызов функции и заменить ее код на свой собственный.
В случае с углом атаки, мы можем применить перехват к функции, которая возвращает значение этого угла в игре. Затем мы можем заменить инструкцию, ответственную за получение угла атаки, на нашу собственную инструкцию прыжком. Это даст нам возможность контролировать угол атаки, не изменяя значение переменной напрямую в памяти.
Что представляет из себя этот "прыжок"?
Это просто переход на другой участок памяти (кода). Называется инструкцией безусловного перехода (jmp). Вот пример такой инструкции на языке ассемблера x86:
где 'kudato' - это метка, помечающая определенное место в коде, на которое нужно осуществить переход.
Например у нас есть следующий код на языке ассемблера x86:
Например, здесь можно заменить строчку "jne not_equal" на "jmp kudato".
Т.е. нивелировать сравнение и сделать его результат бесполезным, пустить ветвь исполнения кода по своему, нужному нам пути.
Возможно мы немного уже закипели на данном этапе, но скоро станет проще!
Сделаем небольшую паузу и обратимся к исторической справке:
Игра RollerCoaster Tycoon была написана на 99% на MASM - Microsoft Macro Assembler
И лишь 1% кода игры - на "C".
Да, когда то игры (как и любые другие приложения) писали прямо на ассемблере!
Но так как это требует большого количество времени и легко допустить ошибку, люди придумали языки более высокого уровня -
такие как C и C++ и т.п.
Одна строчка кода на C/C++ может заменить несколько десятков строк на ассемблере!
Все это позволяет организовать код, сделать его более читаемым и понятным.
Почему нам это важно знать?
Дело в том, что мы можем написать одно и тоже по логике работы но на разных языках - и в итоге получим набор именно машинных инструкций. (Скомпилированный, собранный файл).
Данный процесс называется компиляцией, т.е. преобразование кода будь то это язык высокого уровня (C/C++) или низкого - ассемблер, все равно его нужно скомпилировать чтобы получать файл на выходе.

Возможно, это не совсем точная формулировка (немного упрощено).
Но все что требуется знать на текущем этапе:
- Переход от кода на уровне ассемблера в машинный (нули и единицы) - ассемблирование
- Переход от машинного кода на ассемблер - дизассемблирование.
- Перевод ассемблерного кода в эквивалентный код на высоком уровне - декомпиляция.
Но в глобальном смысле мы рассматриваем сборку машинного кода с высокого уровня - компиляцией,
А разбор бинарного файла до примерного кода на высоком уровне - декомпиляцией, не упоминая промежуточные этапы.
Почему я говорю примерного?
Дело в том, что даже если наш код никак не будет защищен, получить его в самом первоначальном виде (так как задумал разработчик) у нас скорее всего не получится.
Обратимся к этому интересному сайт https://godbolt.org/
Здесь мы можем увидеть результат компиляции нашего кода:
Сделаем простой пример:
Не будем особо вникать в суть того что делает данный код. Условно - механика получение урона.
Можете взять вместе со мной и вставить этот код в наш онлайн Compiler Explorer:
Получим на выходе такой код:
Если вы вставите этот код в наш эксплорер, а после этого выделите любую область кода, то заметите, как слева и справа (взаимно) будут подсвечиваться соответствующие участки кода на ассемблере и на оборот.
Возьмем следующий участок отсюда и выделим его:
Что подсветилось справа?
Да, всего лишь одна строка.
А куда же делись health и damage?
Если вы взгляните на весь листинг целиком, то заметит, что имена переменных исчезли.
В процессе компиляции вся эта информация теряется - имена переменных, комментарии и т.п.
Именно поэтому мы не сможем воссоздать все в изначальном виде.
Но тем не менее анализ может помочь нам догадаться, за что отвечают те или иные участки кода, переменные, функции и т.д.
На каком же уровне будем работать мы?
Наша задача не редактировать машинный или декомпилированный код. Мы работаем с промежуточным вариантом - т.е. с виртуальной памятью. Это значит, что мы будем редактировать CODE секцию .EXE или .DLL загруженных в виртуальную память процесса!
Во всех ли случаях данный способ будет работать, и научившись этой технике, мы сможем взломать любую игру?
К сожалению, нет.
Для успешного взлома нам нужно понять какие технологии используются при разработке игры:
Т.е. мы определяем игровой движок -> определяем вектор атаки с учетом используемых движком технологий и его особенностей.
Рассмотрим основные сценарии:
1) Один из самых популярных языков программирования используемых в разработке игр - C#.
Огромное количество современных игр написано на Unity, который использует C#.
Учитывая этот факт, рассмотрим глобально, как происходит "компиляция":
На C# наш код собирается особым образом, так называемый "Just In Time" или просто "JIT".
Нам не нужно понимать детали этого процесса, только запомним - что компиляция происходит во время выполнения, а значит наш код не будет статичен!

Немного пояснений:
То есть после компиляции программы на C# мы получим некую оболочку и содержащийся в ней CIL-код, который затем будет интерпретирован и запущен с помощью специальной виртуальной машины средствами CLR (если очень упрощенно).
2) Примерно похожий сценарий используется в играх, написанных на JAVA.
Там у нас также есть промежуточный код (java байткод - .jar) + виртуальная машина JVM (Java Virtual Machine)

Таких игр не много, из тех что приходят в голову это Minecraft и Runescape.
3) Примерно по той же схеме работает и PowerPC, где также есть PowerPC Assembly + Dolphin (эмулятор в котором работают PPC Assembly), который, кстати, также написан на C++.
4) В этот пункт мы объединим сразу два типа: игры созданные на скриптовых движках + браузерные игры. Как они работают? Никакого ассемблерного кода не собирается в процессе сборки, все предкомпилированные сценарии работы уже содержатся в самом движке, а он только интерпретирует скрипты. Например, это GameMaker, где вся логика содержится в скриптах .GML
В браузере же все заточено на работе с кодом браузера (который также написаны на C++) и браузерными плагинами, а вся логика описана в JavaScript/HTML/Flash (устаревшее) коде.
5) И последний самый популярный сценарий - игры написанные на Python (огромное количество MMORPG уходящего времени), где вся логика - это байткод Python (.pyc) + виртуальная машина VPM (снова написанная на C++).
Тем самым мы можем выделить три категории, которые имеют четкие признаки:
1) Игры написанные на C++/совместимых движках - код статичен.
2) Игры написанные на C#/Java/консольные эмуляторы - JIT и его аналоги - код хранится в куче (вернемся к этому)
3) Код игровой логике не компилируется в принципе вообще - PYC / браузерные игры.
Где же редактирование ассемблерных инструкций нам понадобится?
1) Лучшие игры для взлома с помощью данной техники - написанные на C/C++
2) Сложный уровень взлома - (неудобный) C#/JAVA/эмуляторы
3) Невозможно взломать данным способом - заскриптованные игры по типу созданных на GameMaker/браузерные игры/PYC.
Если вы изучите исходный вариант в памяти -> отредактируете -> сохраните изменения и попробуете применить после перезагрузки игры - это сработает в играх 1 типа. Достаточно только определить новое место, куда будет загружен образ игры в памяти.
Если же применить эту технику с играми второго типа, то это не сработает. и чтобы применить ваши изменения, вам потребуется несколько доработать код, используя более продвинутые техники сканирования памяти для нахождения отдельных участков, которые перемешаются после перезагрузки.
В третьем варианте вы и вовсе редактируете код браузера, а не код игры. тем не менее это можно использовать НО крайне не рекомендуется.
Как нам определить к какому типу относится интересная нам игра?
Зачастую нам достаточно открыть папку с бинарными файлами игры, чтобы понять это.
Так как большинство игр написано на 2-3 самых популярных движках, мы можем зафиксировать их отличительные особенности.
Например, если вы найдете в директории игры папку "Mono" - игра написана на C#.
А если посмотреть какие .DLL загружаются в память процесса, то там мы заметим такие .DLL как Assembly-CSharp.DLL и т.п., характерно указывающие на применение C#, или вовсе прямо указывающие на применение конкретного движка, например "UnityEngine.dll".
Если же вы находите такие файлы как "UE3ShaderCompilerWorker.exe", или же библиотеки характерно указывающие на применение C/C++ (например, msvc.dll)
Данный способ вы можете применить к любой игре, а также можете самостоятельно загрузить версии различных игровых движков и попробовать собрать проекты, чтобы увидеть что получается в итоге, каждый раз плюс минус будет одна и та же картина из зависимых файлов/библиотек/похожая архитектура проекта.
Если же вы видите что проект содержит в себе только .EXE и несколько .DLL, скорее всего игра написана на C++ и в данном случае отсутствие информации и есть информация, т.к. чаще всего именно игры написанные на C++ содержат только те файлы, образ которых будет загружен в память и ничего лишнего.
Первый большой шаг к взлому:
Как же найти нужный код среди миллионов и миллионов инструкций в крупном проекте?
Например, нам нужно найти код, отвечающий за нанесение урона / и/или систему учета золота в инвентаре.
Давайте построим простой график:

Предположим, что игра содержит в себе окружение (World) + интерфейс (UI),
World содержит в свою очередь Player и Mob's, а объекты Player и Mob's содержат в себе собственные значение Health (HP).
Принцип работы всех инструментов (хакерских, скажем так), которые позволяют нам найти искомый участок, построены по следующему принципу:
Все процессорные архитектуры имеют определенные особенности, позволяющие отлаживать код и находить в нем ошибки. Мы и будем использовать эти особенности на свой лад.
Что это за особенности?
1 - Брейкпоинты (точки останова).
1) Т.е. мы можем используя отладчики установить некую "метку" на нужную нам переменную (которую мы нашли используя знания из предыдущих занятий).
2) Проследить в ходе выполнения игры, какие из участков кода с ней взаимодействуют (обновляют состояние / перезаписывают переменную).
3) Прыгнуть на них и посмотреть, что делают те или иные функции, которые так или иначе взаимодействуют с переменной.
Давайте рассмотрим практический пример:
В качестве подопытной программы возьмем классический WINMINE (сапер).

1. Запустим наш Cheat Engine, аттачимся к процессу.
При открытии любого окошка на поле - начинает тикать таймер, сбросить игру можно нажав на смайлик.
Начинаем игру и находим значение таймера (подсказка: целочисленное -> unknown initial value new scan -> каждый next scan increased value)

Нажимаем правой кнопкой по нашему таймеру и выбираем пункт "Wind out what writes to the address" - простой отладчик в CE каждый раз "улавливает" - кто и что записывает по нашему адресу.
Т.е. здесь и используются прерывания (брейкпоинты) для того чтобы понять, как работает этот участок кода. Только вам ничего не нужно делать руками - CE все сделает за вас!
2. Снова запустим игру!
Что мы видим?

Происходит инкрементация (увеличение) значение с помощью следующих инструкций.
Давайте сделаем самый примитивный хак?

Выбираем в меню (нажав по инструкциям) "Replace this code that does Nothing (NOP) - что означает "занопить" = заменить инструкции командой NOP - No Operation - т.е. НИЧЕГО.
Попробуем запустить игру - и вуаля. Ничего не происходит (таймер не бежит).

Мы заменили инструкцию инкрементации (INC) на NOP, остановив таймер.
Чтобы делать более интересные вещи нам нужно понимать базовый ассемблер.
Это не значит, что мы должны выучить его, но самые простые команды знать нужно, чтобы понимать что происходит, когда мы изучаем что делает тот или иной код в памяти.
Начнем с регистров:
Регистр - временная память в CPU.
Но перед тем как знакомиться с ними вспомним, как взаимодействуют CPU и RAM.
Вы уже знаете, что наш образ и его производные находятся в оперативной памяти после копирования из физической.
А что происходит дальше?
Дальше в работу вступает CPU.

Каждая инструкция строка за строкой "транслируется" в CPU.
Процессор по сути, это такой же участок памяти как и RAM, только значительно меньших размеров и еще быстрее по скорости.
Если в случае с жестким диском (или твердотельным / любым другим накопителем) - задача хранить данные и нет особых требований к скорости, то
RAM создана чтобы работать с теми данными что нам необходимо значительно быстрее. Процессор - содержит еще более быструю память - регистры.

Память процессора также имеет несколько уровней - от самого медленного - L3 (но бОльшего по объему) - до L1 и регистров - самых быстрых участков памяти.
Вся обработка данных происходит в нашем случае именно через регистры.
Не важно что это - очки здоровья, таймер или что-то другое - все это работает на уровне регистров.
Давайте рассмотрим некоторые из них на уровне 32-битной архитектуры:
EAX 00000064
EBX 00000005
ECX 0000002C
EDX 00000019
EDI 018B1000
ESI 018B1000
EBP 6FF930CC
ESP 6FF93070
EIP 02C1A07B
Это простой пример того, что могут содержать в себе регистры.
Например, в EAX может храниться здоровье равное 64 (HEX = 100 DEC), а EBX - величина урона.
Если мы рассмотрим 64-битную архитектуру, то можем увидеть следующую картину:
RAX 0000000000000064
RBX 0000000000000005
RCX 000000000000002C
RDX 0000000000000019
RDI 00000000018B1000
RSI 00000000018B1000
RBP 000000006FF930CC
RSP 000000006FF93070
RIP 0000000002C1A07B
Возможно вы уже видите отличия:
Отличается первая буква (указывающая нам что это 64битная архитектура) - а также больше нулей, т.е. больше свободных бит - больше памяти!
То есть они могут хранить больше информации.
В данном случае они хранят не 32 бита (4 байта), а 64 бита - 8 байт, откуда и берутся названия архитектур.
Но помимо отличия в названиях регистров и длины (вместительности) - появились также и новые регистры от R8 ... до R15 (включительно)
Работают они точно также как и RAX .... RIP.
Поэтому когда вы откроете инспектор в Cheat Engine и увидите там что-то вроде "push eax" или "push rax" - вы сразу можете понять, какое это приложение - x86 (x32) или x64.
В работе же с этими регистрами никаких различий нет - все одинаково.
Что нам нужно знать об этих регистрах?
Что не ломать голову, просто запомним:
Не работает с регистрами и не делаем никакое дерьмо, если они заканчивают на "P", например RBP, RSP, RIP, EIP и т.д.
Например, EIP и RIP содержат указатель на следующую инструкцию, которая должна выполниться, поэтому их изменение может изменить порядок выполнения программы и скорее всего вы просто все сломаете.
Давайте познакомимся с некоторыми из операторов прежде чем перейдем дальше.
Рассмотрим INC.
Что он делает?
Например, мы видим "inc ecx".
Чаще всего INC используется в сочетании с регистром (как в данном примере inc "регистр").
В ходе выполнения этой инструкции произойдет увеличение значения хранящегося в регистре (в данном случае ecx) на 1 единицу.
А что если мы видим конструкцию по типу "inc [eax]"? Что означают эти квадратные скобки?
В данном случае мы не меняем значение в самом EAX. Скобки означают, что регистр содержит в себе указатель на какой-то адрес, над которым нужно провести операцию.
Т.е. буквально inc [eax] будет означать "увеличить на 1 содержимое переменной хранящейся по адресу eax".
А что произойдет, если конструкция будет выглядеть так?
"inc [edi + 8]"
Прибавить к edi значение 8 и использовать его как указатель? Нет.
Если вспомните прошлые уроки, там мы рассматривали простую структуру данных.

В данном случае мы знаем, что ammo хранится на два этажа ниже чем health (health + 8)
И если мы используем
"inc [edi + 8]"
То мы буквально даем команду "увеличить значение переменной находящейся по адресу *указатель на адрес" на два уровня ниже".
DEC - декремент, работает по тому же принципу, но только вместо увеличения - уменьшение на 1.
Вся логика работы та же самая.
Также один из часто используемых операторов - ADD.
Что делает данный оператор?
Например, "add eax, 2".
Это операция сложения. Мы складываем значение в eax с 2 и перезаписываем результат в eax.
А что, если будет два регистра в качестве слагаемых?
Например, "add eax edx".
В какой из них будет записан результат?
Результат всегда записывается в первый оператор.
Если eax будет хранить значение 2, а edx = 4, то eax примет значение 6, а edx останется без изменений - 4.
Если мы используем скобки - add [eax], 10 или add [eax], edi, то происходит "сложение переменной находящейся по адресу (указателю) со значением справа (или значением регистра).
С SUB (сабстракт) принцип точно такой же, только теперь происходит вычетание.
И один из главных операторов - MOV, который обязательно нужно знать.
MOV позволяет вам перезаписать что-либо в ваш регистр.
Например "mov ebx, 200" запишет 200 в ebx.
Со скобками все точно также как в прошлых случаях.
Оператор NEG - самый простой. Он меняет знак, если вы хранили в переменной значение 100 - то после применения NEG - значение будет равно "-100".
MUL - (мультиплай) он же умножение.
DIV (dividing) - деление. И вот туn сделаем остановку.
Например, мы видим команду
"div ecx".
Возникает вопрос. А что же на что мы будем делить?
Куда будет записан результат?
Оператор DIV всегда взаимодействует с EAX и EDX (RAX и RDX в 64 бит).
Например, если EAX хранит 120, а ECX хранит 12,
То при вызове div ecx произойдет деление EAX на ECX.
Результат будет записан в EAX.
А что, если в EAX будет записано 10, а ECX хранит 12?
Как будет записано число, ведь 10 не делится целочислено на 12?
В EAX будет записан "0", а остаток выброшен.
Поэтому всегда будьте аккуратны с этой инструкцией.
Давайте попрактикуемся и сделаем что-то посложнее, чем NOP. Ведь теперь мы знаем и другие операторы, а значит можем не просто очистить логику и заменить на "ничего", а можем
изменять ее так, как нам нужно!
Вернемся к саперу и запустим его, а также CE. После этого найдем таймер снова и вынесем в таблицу.
При запуске игры значение увеличивается на 1 единицу.


Как сделать так, чтобы увеличивалось, например, на 2?
Снова аттачимся и ставим бряк, смотрим какой участок кода пишет в нашу переменную как мы и делали ранее.

Нажимаем на нашу INC инструкцию и выбираем справа "Add to the codelist".
Даем название этой функции и жмем ОК.

Жмем в появившемся окне ПКМ по нашему IncTimer и нажимаем "Open in the disassembler" (Открыть в дизассемблере).

Здесь мы можем видеть искомый нами участок кода.
Что если заменим инструкцию на следующую:

Попробуем заменить INC на ADD, и указать двойку в качестве слагаемого.

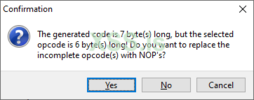
Но мы получаем предупреждение. Что же идет не так?
Все дело в том, что старая инструкция занимала 6 байт, новая же - 7 байт.
И мы просто не можем взять и уместить ее.
Что делать в таком случае? Если мы все таки перезапишем, то недостающий байт не будет вставлен между текущей инструкцией и следующей, нет. Память выделена не будет.
1 байт будет взят из следующей инструкции и перезапишет ее, сломав всю логику и ветвь исполнения, что скорее всего (99%) приведет к крашу.
Более правильным решением будет:
1) Выделить новый объект (выделить память)
2) Создать там необходимый нам код
3) Добавить в конце прыжок назад, т.е. к первоначальному этапу.
Все это можно сделать в рамках нашего урока через CE.
Для этого выделим нужную строчку с инструкцией INC (оригинальной), откроем "Tools" и выберем "Auto Assemble".
Создадим секции включения и выключения (Enable/Disable)

А далее в "Template" выберем готовый шаблон "Code Injection".
Должно получиться так:

Удалим секцию "originalcode".

Секции Enable и Disable выполняют роль аллоцирования/деаллоцирования нашего объекта (кода) с помощью alloc и dealloc.
Как можете видеть - будет происходить выделение "newmem" - там будет наш код.
И происходить "jmp newmem", т.е. прыжок к нашему коду.
Добавим в newmem нашу команду:

Теперь будет происходить сложение изначального значение с двойкой, а затем шаг к исходной инструкции (прыжок) -> которая в свою очередь будет снова вести нас на нашу область памяти с нашей улучшенной функцией инкрементации, где вместо нее будет сложение на 2.
Нажмем на "Assign to the current cheat table" в разделе "File" чтобы добавить наш шаблон в таблицу.
Включим его нажав на пустое окошко (должен появиться крест)

Запустив нашего сапера мы видим, как наш таймер увеличивается с каждой секундой на 2, вместо 1.

Выключив наш скрипт мы увидим в памяти следующее:

А теперь снова включим:

Появился jmp на "newmem", где содержится наша логика.
JMP весит 5 байт, старая же инструкция 6.
Пустой же байт заполнился инструкцией NOP (так как нельзя его просто убрать).
То есть несмотря на то, что места на команду add [регистр], 2 нам не хватало (она весила 7 байт), мы выделили для нее отдельное место, а здесь просто сделали прыжок, инструкция которого укладывается
в необходимый нам размер.
Это очень простой пример "хака", если его можно так назвать, но он доступно объясняет то, как работать с инструкциями.
Чтобы сделать что-то более интересное - нужно соответственно более глубокое понимание как самого ассемблера и регистров (для уверенной работы с ними), так и фантазия и понимание того, что вы хотите сделать и как это реализовать.
Дальше рассмотрим более интересные концепции.
Всех с Наступившим.
Специально для xss.pro от Албанца.
Сегодня мы разберемся как редактировать машинный код!
Что это значит?
Мы будем редактировать игровой код таким образом, чтобы игра делала то что нужно нам!
Не стоит волноваться если за всю свою жизнь вы не написали ни строчки кода, так как перед тем как мы перейдем к практике мы рассмотрим минимально необходимую теорию.
Для начала разделим наш процесс на части:
1) Найти релевантный участок кода
2) Изменить код
3) Проверить, все ли работает так как мы задумали
Если вы вспомните наши предыдущие уроки, то мы делали что-то похожее:
1) Искали значение в памяти
2) Редактировали его
3) Проверяли результат
Похоже ли редактирование кода на редактирование значений? Отчасти да, но
в случае с редактированием значений в памяти нам нужно было лишь найти нужный адрес
и перезаписать исходный вариант в нужном формате и допустимых пределах.
Редактировать машинный же код значительно сложнее. Почему?
1) Необходимо более глубокое понимание принципов сканирования памяти, чтобы точно определить нужный участок кода
2) Необходимо понимание ассемблера (представление команда процесса доступным человеку языком) на базовым уровне
Для начала окунемся в небольшую теорию и рассмотрим, что же такое ассемблерный код, а уже потом посмотрим, как же его редактировать:
1) Ваш компьютер имеет CPU (процессор)
2) CPU способен запускать код
3) В зависимости от архитектуры вашего CPU определяется то, какой код можно запустить на вашем ПК (или не пк)
Современные ПК, консоли, и т.п. имеют архитектуры x86 / x64 (именно на них будет наш фокус).
Различные смартфоны / портативные консоли / планшеты часто имеют архитектуру ARM. (Она в чем то более современная, энергоэффективная, заточенная на низкое потребление энергии чтобы продлить цикл автономной работы портативных устройств)
Существуют также архитектуры M1 / M2 - вариации ARM от APPLE.
Если например у вас будет старая игра, то вы вряд ли сможете запустить ее на современной архитектуре, т.к. логика работы / набор инструкций и т.п. может отличаться, и для корректной работы вам придется запускать эмулятор, который как бы "воссоздаст" необходимую архитектуру виртуально.
Также необходимо отметить еще одну архитектуру - PowerPC. Возможно, когда-нибудь вам придет идея поломать консоли по типу Xbox, Nintendo, Wii (если мы говорим о прошлых поколениях, т.к. современные имеют часто архитектуру x64).
Зачем нам это знать? Спросите вы.
В зависимости от архитектуры будет отличаться и язык ассемблера.
Но при этом - если у вас есть базовое и концептуальное понимание, разобраться в любой архитектуре не должно стать для вас проблемой.
Вернемся к x86 / x64!
Как вы можете вспомнить из прошлых уроков:
Что мы знаем?
- В виртуальной памяти существуют наш скопированный образ (SAMPLE.EXE + необходимые DLL) = STATIC CODE
- Существуют выделенные объекты (аллоцированные / Alocated) = DATA
Что мы знаем о наших .EXE / .DLL?
Что каждый из них имеет две секции: DATA и CODE.
DATA - набор из нулей и единиц, который можно интерпретировать различным образом: массив байт, отдельные элементы которого представляют булевы (переключатели), целые числа, числа с плавающей точкой, строки и все остальные типы данных.
Сегодня наше внимание - CODE.
Это все тот же набор из нулей и единиц, но для восприятия кода нам нужно изменить нашу ментальную модель.
Этот набор нулей и единиц также можно группировать в массив байт - но только теперь мы получаем не данные, а набор машинных инструкций! Не беспокойтесь, если на примере ниже вы что-то из этого кода не поймете. Это нормально.
Код:
C7 40 04 32 00 00 00 = mov [rax+04],32
90 = nop
83 6D F8 FC = sub dword ptr [rbp-08],-04
48 8D 02 24 = lea rax, [rsp]
FF D5 = call rbpТо что вы видите слева - это машинный код (raw data), то что вы видите справа - и есть ассемблерный код.
Примерно по такому принципу работают любые инспекторы кода, т.е. они конвертируют "кашу" из машинных кодов в ассемблерный листинг, более удобный для нашего восприятия.
Как это нам поможет?
Чтобы изменить логику нам не нужно работать на уровне машинного кода в сыром виде.
Мы находим участок памяти - получаем сырой вид (столбец слева) - с помощью специальных инструментов конвертируем в удобночитаемый ассемблерный листинг - редактируем на уровне ассемблера - конвертируем полученный результат с исправленной логикой в сырой вид (машинный) - перезаписываем участок.
Для примера рассмотрим небольшой игровой код сгенерированный с помощью CHAT GPT:
Код:
DATA SEGMENT
ANGLE DB 45 ; Заданное направление атаки в градусах
DATA ENDS
CODE SEGMENT
ASSUME DS:DATA, CS:CODE
; Инициализация
START:
MOV AX, DATA
MOV DS, AX
; Получение введенного значения угла атаки
MOV AH, 1 ; Чтение одного символа с клавиатуры
INT 21H
SUB AL, '0' ; Преобразование символа в число
MOV BL, AL ; BL содержит заданный угол атаки
; Вывод значения угла атаки на экран
MOV AH, 2 ; Вывод символа на экран
ADD BL, '0' ; Преобразование числа в символ
MOV DL, BL ; DL содержит символ угла атаки
INT 21H
; Дальнейший код игры...
; Конец программы
MOV AH, 4CH
INT 21H
CODE ENDS
END STARTЕсли бы мы захотели изменить угол атаки, мы бы пришли к поиску значения ANGLE DB в памяти и изменили значение переменной.
А как сделать это другим способом?
Если мы хотим изменить угол атаки, не меняя значение переменной в памяти, мы можем использовать метод, называемый "перехват виртуальных функций" (virtual function hooking). Этот метод позволяет нам перехватить вызов функции и заменить ее код на свой собственный.
В случае с углом атаки, мы можем применить перехват к функции, которая возвращает значение этого угла в игре. Затем мы можем заменить инструкцию, ответственную за получение угла атаки, на нашу собственную инструкцию прыжком. Это даст нам возможность контролировать угол атаки, не изменяя значение переменной напрямую в памяти.
Что представляет из себя этот "прыжок"?
Это просто переход на другой участок памяти (кода). Называется инструкцией безусловного перехода (jmp). Вот пример такой инструкции на языке ассемблера x86:
Код:
jmp kudatoгде 'kudato' - это метка, помечающая определенное место в коде, на которое нужно осуществить переход.
Например у нас есть следующий код на языке ассемблера x86:
Код:
section .text
global _start
_start:
mov eax, 1 ; устанавливаем значение 1 в регистр eax
cmp eax, 2 ; сравниваем значение из eax с 2
jne not_equal ; если значения не равны, перейти на метку not_equal
mov eax, 10 ; устанавливаем значение 10 в регистр eax
jmp end ; перейти на метку end
not_equal:
mov eax, 20 ; устанавливаем значение 20 в регистр eax
end:
; продолжение кода...Например, здесь можно заменить строчку "jne not_equal" на "jmp kudato".
Т.е. нивелировать сравнение и сделать его результат бесполезным, пустить ветвь исполнения кода по своему, нужному нам пути.
Возможно мы немного уже закипели на данном этапе, но скоро станет проще!
Сделаем небольшую паузу и обратимся к исторической справке:
Игра RollerCoaster Tycoon была написана на 99% на MASM - Microsoft Macro Assembler
И лишь 1% кода игры - на "C".
Да, когда то игры (как и любые другие приложения) писали прямо на ассемблере!
Но так как это требует большого количество времени и легко допустить ошибку, люди придумали языки более высокого уровня -
такие как C и C++ и т.п.
Одна строчка кода на C/C++ может заменить несколько десятков строк на ассемблере!
Все это позволяет организовать код, сделать его более читаемым и понятным.
Почему нам это важно знать?
Дело в том, что мы можем написать одно и тоже по логике работы но на разных языках - и в итоге получим набор именно машинных инструкций. (Скомпилированный, собранный файл).
Данный процесс называется компиляцией, т.е. преобразование кода будь то это язык высокого уровня (C/C++) или низкого - ассемблер, все равно его нужно скомпилировать чтобы получать файл на выходе.
Возможно, это не совсем точная формулировка (немного упрощено).
Но все что требуется знать на текущем этапе:
- Переход от кода на уровне ассемблера в машинный (нули и единицы) - ассемблирование
- Переход от машинного кода на ассемблер - дизассемблирование.
- Перевод ассемблерного кода в эквивалентный код на высоком уровне - декомпиляция.
Но в глобальном смысле мы рассматриваем сборку машинного кода с высокого уровня - компиляцией,
А разбор бинарного файла до примерного кода на высоком уровне - декомпиляцией, не упоминая промежуточные этапы.
Почему я говорю примерного?
Дело в том, что даже если наш код никак не будет защищен, получить его в самом первоначальном виде (так как задумал разработчик) у нас скорее всего не получится.
Обратимся к этому интересному сайт https://godbolt.org/
Здесь мы можем увидеть результат компиляции нашего кода:
Сделаем простой пример:
Код:
#include <cstdlib>
#include <stdio.h>
void killZombie()
{
printf("Zombie killed!");
}
int getDamage (int health, int damage)
{
health -= damage;
if (health <= 0)
{
killZombie();
health = 0;
}
}
int main()
{
int health = 5000;
int damage = rand() % 25;
health = getDamage(health, damage);
printf("%d", health);
}Не будем особо вникать в суть того что делает данный код. Условно - механика получение урона.
Можете взять вместе со мной и вставить этот код в наш онлайн Compiler Explorer:
Получим на выходе такой код:
Код:
.LC0:
.string "Zombie killed!"
killZombie():
push rbp
mov rbp, rsp
mov edi, OFFSET FLAT:.LC0
mov eax, 0
call printf
nop
pop rbp
ret
getDamage(int, int):
push rbp
mov rbp, rsp
sub rsp, 16
mov DWORD PTR [rbp-4], edi
mov DWORD PTR [rbp-8], esi
mov eax, DWORD PTR [rbp-8]
sub DWORD PTR [rbp-4], eax
cmp DWORD PTR [rbp-4], 0
jg .L3
call killZombie()
mov DWORD PTR [rbp-4], 0
.L3:
ud2
.LC1:
.string "%d"
main:
push rbp
mov rbp, rsp
sub rsp, 16
mov DWORD PTR [rbp-4], 5000
call rand
mov edx, eax
movsx rax, edx
imul rax, rax, 1374389535
shr rax, 32
sar eax, 3
mov ecx, edx
sar ecx, 31
sub eax, ecx
mov DWORD PTR [rbp-8], eax
mov ecx, DWORD PTR [rbp-8]
mov eax, ecx
sal eax, 2
add eax, ecx
lea ecx, [0+rax*4]
add eax, ecx
sub edx, eax
mov DWORD PTR [rbp-8], edx
mov edx, DWORD PTR [rbp-8]
mov eax, DWORD PTR [rbp-4]
mov esi, edx
mov edi, eax
call getDamage(int, int)
mov DWORD PTR [rbp-4], eax
mov eax, DWORD PTR [rbp-4]
mov esi, eax
mov edi, OFFSET FLAT:.LC1
mov eax, 0
call printf
mov eax, 0
leave
retЕсли вы вставите этот код в наш эксплорер, а после этого выделите любую область кода, то заметите, как слева и справа (взаимно) будут подсвечиваться соответствующие участки кода на ассемблере и на оборот.
Возьмем следующий участок отсюда и выделим его:
Код:
int health = 5000;
int damage = rand() % 25;
health = getDamage(health, damage);
printf("%d", health);Что подсветилось справа?
Да, всего лишь одна строка.
Код:
mov DWORD PTR [rbp-4], 5000А куда же делись health и damage?
Если вы взгляните на весь листинг целиком, то заметит, что имена переменных исчезли.
В процессе компиляции вся эта информация теряется - имена переменных, комментарии и т.п.
Именно поэтому мы не сможем воссоздать все в изначальном виде.
Но тем не менее анализ может помочь нам догадаться, за что отвечают те или иные участки кода, переменные, функции и т.д.
На каком же уровне будем работать мы?
Наша задача не редактировать машинный или декомпилированный код. Мы работаем с промежуточным вариантом - т.е. с виртуальной памятью. Это значит, что мы будем редактировать CODE секцию .EXE или .DLL загруженных в виртуальную память процесса!
Во всех ли случаях данный способ будет работать, и научившись этой технике, мы сможем взломать любую игру?
К сожалению, нет.
Для успешного взлома нам нужно понять какие технологии используются при разработке игры:
Т.е. мы определяем игровой движок -> определяем вектор атаки с учетом используемых движком технологий и его особенностей.
Рассмотрим основные сценарии:
1) Один из самых популярных языков программирования используемых в разработке игр - C#.
Огромное количество современных игр написано на Unity, который использует C#.
Учитывая этот факт, рассмотрим глобально, как происходит "компиляция":
На C# наш код собирается особым образом, так называемый "Just In Time" или просто "JIT".
Нам не нужно понимать детали этого процесса, только запомним - что компиляция происходит во время выполнения, а значит наш код не будет статичен!
Немного пояснений:
Common Intermediate Language — «высокоуровневый ассемблер» виртуальной машины .NET.
Common Language Runtime — исполняющая среда для байт-кода CIL, в который компилируются программы, написанные на .NET-совместимых языках программирования.
То есть после компиляции программы на C# мы получим некую оболочку и содержащийся в ней CIL-код, который затем будет интерпретирован и запущен с помощью специальной виртуальной машины средствами CLR (если очень упрощенно).
2) Примерно похожий сценарий используется в играх, написанных на JAVA.
Там у нас также есть промежуточный код (java байткод - .jar) + виртуальная машина JVM (Java Virtual Machine)
Таких игр не много, из тех что приходят в голову это Minecraft и Runescape.
3) Примерно по той же схеме работает и PowerPC, где также есть PowerPC Assembly + Dolphin (эмулятор в котором работают PPC Assembly), который, кстати, также написан на C++.
4) В этот пункт мы объединим сразу два типа: игры созданные на скриптовых движках + браузерные игры. Как они работают? Никакого ассемблерного кода не собирается в процессе сборки, все предкомпилированные сценарии работы уже содержатся в самом движке, а он только интерпретирует скрипты. Например, это GameMaker, где вся логика содержится в скриптах .GML
В браузере же все заточено на работе с кодом браузера (который также написаны на C++) и браузерными плагинами, а вся логика описана в JavaScript/HTML/Flash (устаревшее) коде.
5) И последний самый популярный сценарий - игры написанные на Python (огромное количество MMORPG уходящего времени), где вся логика - это байткод Python (.pyc) + виртуальная машина VPM (снова написанная на C++).
Тем самым мы можем выделить три категории, которые имеют четкие признаки:
1) Игры написанные на C++/совместимых движках - код статичен.
2) Игры написанные на C#/Java/консольные эмуляторы - JIT и его аналоги - код хранится в куче (вернемся к этому)
3) Код игровой логике не компилируется в принципе вообще - PYC / браузерные игры.
Где же редактирование ассемблерных инструкций нам понадобится?
1) Лучшие игры для взлома с помощью данной техники - написанные на C/C++
2) Сложный уровень взлома - (неудобный) C#/JAVA/эмуляторы
3) Невозможно взломать данным способом - заскриптованные игры по типу созданных на GameMaker/браузерные игры/PYC.
Если вы изучите исходный вариант в памяти -> отредактируете -> сохраните изменения и попробуете применить после перезагрузки игры - это сработает в играх 1 типа. Достаточно только определить новое место, куда будет загружен образ игры в памяти.
Если же применить эту технику с играми второго типа, то это не сработает. и чтобы применить ваши изменения, вам потребуется несколько доработать код, используя более продвинутые техники сканирования памяти для нахождения отдельных участков, которые перемешаются после перезагрузки.
В третьем варианте вы и вовсе редактируете код браузера, а не код игры. тем не менее это можно использовать НО крайне не рекомендуется.
Как нам определить к какому типу относится интересная нам игра?
Зачастую нам достаточно открыть папку с бинарными файлами игры, чтобы понять это.
Так как большинство игр написано на 2-3 самых популярных движках, мы можем зафиксировать их отличительные особенности.
Например, если вы найдете в директории игры папку "Mono" - игра написана на C#.
А если посмотреть какие .DLL загружаются в память процесса, то там мы заметим такие .DLL как Assembly-CSharp.DLL и т.п., характерно указывающие на применение C#, или вовсе прямо указывающие на применение конкретного движка, например "UnityEngine.dll".
Если же вы находите такие файлы как "UE3ShaderCompilerWorker.exe", или же библиотеки характерно указывающие на применение C/C++ (например, msvc.dll)
Данный способ вы можете применить к любой игре, а также можете самостоятельно загрузить версии различных игровых движков и попробовать собрать проекты, чтобы увидеть что получается в итоге, каждый раз плюс минус будет одна и та же картина из зависимых файлов/библиотек/похожая архитектура проекта.
Если же вы видите что проект содержит в себе только .EXE и несколько .DLL, скорее всего игра написана на C++ и в данном случае отсутствие информации и есть информация, т.к. чаще всего именно игры написанные на C++ содержат только те файлы, образ которых будет загружен в память и ничего лишнего.
Первый большой шаг к взлому:
Как же найти нужный код среди миллионов и миллионов инструкций в крупном проекте?
Например, нам нужно найти код, отвечающий за нанесение урона / и/или систему учета золота в инвентаре.
Давайте построим простой график:
Предположим, что игра содержит в себе окружение (World) + интерфейс (UI),
World содержит в свою очередь Player и Mob's, а объекты Player и Mob's содержат в себе собственные значение Health (HP).
Принцип работы всех инструментов (хакерских, скажем так), которые позволяют нам найти искомый участок, построены по следующему принципу:
Все процессорные архитектуры имеют определенные особенности, позволяющие отлаживать код и находить в нем ошибки. Мы и будем использовать эти особенности на свой лад.
Что это за особенности?
1 - Брейкпоинты (точки останова).
1) Т.е. мы можем используя отладчики установить некую "метку" на нужную нам переменную (которую мы нашли используя знания из предыдущих занятий).
2) Проследить в ходе выполнения игры, какие из участков кода с ней взаимодействуют (обновляют состояние / перезаписывают переменную).
3) Прыгнуть на них и посмотреть, что делают те или иные функции, которые так или иначе взаимодействуют с переменной.
Давайте рассмотрим практический пример:
В качестве подопытной программы возьмем классический WINMINE (сапер).
1. Запустим наш Cheat Engine, аттачимся к процессу.
При открытии любого окошка на поле - начинает тикать таймер, сбросить игру можно нажав на смайлик.
Начинаем игру и находим значение таймера (подсказка: целочисленное -> unknown initial value new scan -> каждый next scan increased value)
Нажимаем правой кнопкой по нашему таймеру и выбираем пункт "Wind out what writes to the address" - простой отладчик в CE каждый раз "улавливает" - кто и что записывает по нашему адресу.
Т.е. здесь и используются прерывания (брейкпоинты) для того чтобы понять, как работает этот участок кода. Только вам ничего не нужно делать руками - CE все сделает за вас!
2. Снова запустим игру!
Что мы видим?
Происходит инкрементация (увеличение) значение с помощью следующих инструкций.
Давайте сделаем самый примитивный хак?
Выбираем в меню (нажав по инструкциям) "Replace this code that does Nothing (NOP) - что означает "занопить" = заменить инструкции командой NOP - No Operation - т.е. НИЧЕГО.
Попробуем запустить игру - и вуаля. Ничего не происходит (таймер не бежит).
Мы заменили инструкцию инкрементации (INC) на NOP, остановив таймер.
Чтобы делать более интересные вещи нам нужно понимать базовый ассемблер.
Это не значит, что мы должны выучить его, но самые простые команды знать нужно, чтобы понимать что происходит, когда мы изучаем что делает тот или иной код в памяти.
Начнем с регистров:
Регистр - временная память в CPU.
Но перед тем как знакомиться с ними вспомним, как взаимодействуют CPU и RAM.
Вы уже знаете, что наш образ и его производные находятся в оперативной памяти после копирования из физической.
А что происходит дальше?
Дальше в работу вступает CPU.
Каждая инструкция строка за строкой "транслируется" в CPU.
Процессор по сути, это такой же участок памяти как и RAM, только значительно меньших размеров и еще быстрее по скорости.
Если в случае с жестким диском (или твердотельным / любым другим накопителем) - задача хранить данные и нет особых требований к скорости, то
RAM создана чтобы работать с теми данными что нам необходимо значительно быстрее. Процессор - содержит еще более быструю память - регистры.
Память процессора также имеет несколько уровней - от самого медленного - L3 (но бОльшего по объему) - до L1 и регистров - самых быстрых участков памяти.
Вся обработка данных происходит в нашем случае именно через регистры.
Не важно что это - очки здоровья, таймер или что-то другое - все это работает на уровне регистров.
Давайте рассмотрим некоторые из них на уровне 32-битной архитектуры:
EAX 00000064
EBX 00000005
ECX 0000002C
EDX 00000019
EDI 018B1000
ESI 018B1000
EBP 6FF930CC
ESP 6FF93070
EIP 02C1A07B
Это простой пример того, что могут содержать в себе регистры.
Например, в EAX может храниться здоровье равное 64 (HEX = 100 DEC), а EBX - величина урона.
Если мы рассмотрим 64-битную архитектуру, то можем увидеть следующую картину:
RAX 0000000000000064
RBX 0000000000000005
RCX 000000000000002C
RDX 0000000000000019
RDI 00000000018B1000
RSI 00000000018B1000
RBP 000000006FF930CC
RSP 000000006FF93070
RIP 0000000002C1A07B
Возможно вы уже видите отличия:
Отличается первая буква (указывающая нам что это 64битная архитектура) - а также больше нулей, т.е. больше свободных бит - больше памяти!
То есть они могут хранить больше информации.
В данном случае они хранят не 32 бита (4 байта), а 64 бита - 8 байт, откуда и берутся названия архитектур.
Но помимо отличия в названиях регистров и длины (вместительности) - появились также и новые регистры от R8 ... до R15 (включительно)
Работают они точно также как и RAX .... RIP.
Поэтому когда вы откроете инспектор в Cheat Engine и увидите там что-то вроде "push eax" или "push rax" - вы сразу можете понять, какое это приложение - x86 (x32) или x64.
В работе же с этими регистрами никаких различий нет - все одинаково.
Что нам нужно знать об этих регистрах?
Что не ломать голову, просто запомним:
Не работает с регистрами и не делаем никакое дерьмо, если они заканчивают на "P", например RBP, RSP, RIP, EIP и т.д.
Например, EIP и RIP содержат указатель на следующую инструкцию, которая должна выполниться, поэтому их изменение может изменить порядок выполнения программы и скорее всего вы просто все сломаете.
Давайте познакомимся с некоторыми из операторов прежде чем перейдем дальше.
Рассмотрим INC.
Что он делает?
Например, мы видим "inc ecx".
Чаще всего INC используется в сочетании с регистром (как в данном примере inc "регистр").
В ходе выполнения этой инструкции произойдет увеличение значения хранящегося в регистре (в данном случае ecx) на 1 единицу.
А что если мы видим конструкцию по типу "inc [eax]"? Что означают эти квадратные скобки?
В данном случае мы не меняем значение в самом EAX. Скобки означают, что регистр содержит в себе указатель на какой-то адрес, над которым нужно провести операцию.
Т.е. буквально inc [eax] будет означать "увеличить на 1 содержимое переменной хранящейся по адресу eax".
А что произойдет, если конструкция будет выглядеть так?
"inc [edi + 8]"
Прибавить к edi значение 8 и использовать его как указатель? Нет.
Если вспомните прошлые уроки, там мы рассматривали простую структуру данных.
В данном случае мы знаем, что ammo хранится на два этажа ниже чем health (health + 8)
И если мы используем
"inc [edi + 8]"
То мы буквально даем команду "увеличить значение переменной находящейся по адресу *указатель на адрес" на два уровня ниже".
DEC - декремент, работает по тому же принципу, но только вместо увеличения - уменьшение на 1.
Вся логика работы та же самая.
Также один из часто используемых операторов - ADD.
Что делает данный оператор?
Например, "add eax, 2".
Это операция сложения. Мы складываем значение в eax с 2 и перезаписываем результат в eax.
А что, если будет два регистра в качестве слагаемых?
Например, "add eax edx".
В какой из них будет записан результат?
Результат всегда записывается в первый оператор.
Если eax будет хранить значение 2, а edx = 4, то eax примет значение 6, а edx останется без изменений - 4.
Если мы используем скобки - add [eax], 10 или add [eax], edi, то происходит "сложение переменной находящейся по адресу (указателю) со значением справа (или значением регистра).
С SUB (сабстракт) принцип точно такой же, только теперь происходит вычетание.
И один из главных операторов - MOV, который обязательно нужно знать.
MOV позволяет вам перезаписать что-либо в ваш регистр.
Например "mov ebx, 200" запишет 200 в ebx.
Со скобками все точно также как в прошлых случаях.
Оператор NEG - самый простой. Он меняет знак, если вы хранили в переменной значение 100 - то после применения NEG - значение будет равно "-100".
MUL - (мультиплай) он же умножение.
DIV (dividing) - деление. И вот туn сделаем остановку.
Например, мы видим команду
"div ecx".
Возникает вопрос. А что же на что мы будем делить?
Куда будет записан результат?
Оператор DIV всегда взаимодействует с EAX и EDX (RAX и RDX в 64 бит).
Например, если EAX хранит 120, а ECX хранит 12,
То при вызове div ecx произойдет деление EAX на ECX.
Результат будет записан в EAX.
А что, если в EAX будет записано 10, а ECX хранит 12?
Как будет записано число, ведь 10 не делится целочислено на 12?
В EAX будет записан "0", а остаток выброшен.
Поэтому всегда будьте аккуратны с этой инструкцией.
Давайте попрактикуемся и сделаем что-то посложнее, чем NOP. Ведь теперь мы знаем и другие операторы, а значит можем не просто очистить логику и заменить на "ничего", а можем
изменять ее так, как нам нужно!
Вернемся к саперу и запустим его, а также CE. После этого найдем таймер снова и вынесем в таблицу.
При запуске игры значение увеличивается на 1 единицу.
Как сделать так, чтобы увеличивалось, например, на 2?
Снова аттачимся и ставим бряк, смотрим какой участок кода пишет в нашу переменную как мы и делали ранее.
Нажимаем на нашу INC инструкцию и выбираем справа "Add to the codelist".
Даем название этой функции и жмем ОК.
Жмем в появившемся окне ПКМ по нашему IncTimer и нажимаем "Open in the disassembler" (Открыть в дизассемблере).
Здесь мы можем видеть искомый нами участок кода.
Что если заменим инструкцию на следующую:
Попробуем заменить INC на ADD, и указать двойку в качестве слагаемого.
Но мы получаем предупреждение. Что же идет не так?
Все дело в том, что старая инструкция занимала 6 байт, новая же - 7 байт.
И мы просто не можем взять и уместить ее.
Что делать в таком случае? Если мы все таки перезапишем, то недостающий байт не будет вставлен между текущей инструкцией и следующей, нет. Память выделена не будет.
1 байт будет взят из следующей инструкции и перезапишет ее, сломав всю логику и ветвь исполнения, что скорее всего (99%) приведет к крашу.
Более правильным решением будет:
1) Выделить новый объект (выделить память)
2) Создать там необходимый нам код
3) Добавить в конце прыжок назад, т.е. к первоначальному этапу.
Все это можно сделать в рамках нашего урока через CE.
Для этого выделим нужную строчку с инструкцией INC (оригинальной), откроем "Tools" и выберем "Auto Assemble".
Создадим секции включения и выключения (Enable/Disable)
А далее в "Template" выберем готовый шаблон "Code Injection".
Должно получиться так:
Удалим секцию "originalcode".
Секции Enable и Disable выполняют роль аллоцирования/деаллоцирования нашего объекта (кода) с помощью alloc и dealloc.
Как можете видеть - будет происходить выделение "newmem" - там будет наш код.
И происходить "jmp newmem", т.е. прыжок к нашему коду.
Добавим в newmem нашу команду:
Теперь будет происходить сложение изначального значение с двойкой, а затем шаг к исходной инструкции (прыжок) -> которая в свою очередь будет снова вести нас на нашу область памяти с нашей улучшенной функцией инкрементации, где вместо нее будет сложение на 2.
Нажмем на "Assign to the current cheat table" в разделе "File" чтобы добавить наш шаблон в таблицу.
Включим его нажав на пустое окошко (должен появиться крест)
Запустив нашего сапера мы видим, как наш таймер увеличивается с каждой секундой на 2, вместо 1.
Выключив наш скрипт мы увидим в памяти следующее:
А теперь снова включим:
Появился jmp на "newmem", где содержится наша логика.
JMP весит 5 байт, старая же инструкция 6.
Пустой же байт заполнился инструкцией NOP (так как нельзя его просто убрать).
То есть несмотря на то, что места на команду add [регистр], 2 нам не хватало (она весила 7 байт), мы выделили для нее отдельное место, а здесь просто сделали прыжок, инструкция которого укладывается
в необходимый нам размер.
Это очень простой пример "хака", если его можно так назвать, но он доступно объясняет то, как работать с инструкциями.
Чтобы сделать что-то более интересное - нужно соответственно более глубокое понимание как самого ассемблера и регистров (для уверенной работы с ними), так и фантазия и понимание того, что вы хотите сделать и как это реализовать.
Дальше рассмотрим более интересные концепции.
Всех с Наступившим.
Специально для xss.pro от Албанца.

")

