- Автор темы
- Добавить закладку
- #21
Пожалуйста, обратите внимание, что пользователь заблокирован
ЭФФЕКТИВНОЕ ПОЛУЧЕНИЕ ХЕША ПАРОЛЕЙ В WINDOWS. ЧАСТЬ 3

В предыдущих двух статьях из серии, я рассказывал, как получить хеши паролей локальных пользователей (из SAM) и доменных пользователей (из файла NTDS.DIT на контроллере домена).
Автор: Bernardo Damele A. G
История паролей
В предыдущих двух статьях (1, 2) из серии, я рассказывал, как получить хеши паролей локальных пользователей (из SAM) и доменных пользователей (из файла NTDS.DIT на контроллере домена).
Если в настройках парольной политики включен параметр “Требовать неповторяемость паролей” (“Enforce password history”), то Windows сохраняет определенное количество старых паролей, прежде чем разрешить пользователю использовать старые пароли вновь. На следующем скриншоте показано, как именно включить ведение истории паролей:

Local Security Policy (secpol.msc) / Account Policies / Password Policy / Enforce password history
По умолчанию на обычных рабочих станциях параметр “Требовать неповторяемость паролей” установлен в 0, а на контроллерах домена – в 24. Благодаря таким установкам, существует вероятность, что при извлечении хешей из ntds.dit, вы также получите хеши старых паролей. В дальнейшем знание старых хешированных паролей может помочь вам найти закономерности в выборе паролей целевыми пользователями.
Кроме того, знание истории паролей может облегчить вам жизнь на дальнейших этапах проведения атаки. Поэтому никогда не пренебрегайте информацией, полученной из парольной истории.
Наряду с уже известными утилитами (Cain & Abel, PWDumpX) парольную историю можно слить с помощью утилиты pwhist от Toolcrypt.
LSA секреты
LSA секреты – это специальная область реестра, в которой Windows хранит важную информацию. В секреты входят:
LSA секреты хранятся в ветке реестра HKEY_LOCAL_MACHINE/Security/Policy/Secrets. Каждый секрет имеет свой собственный ключ. Родительский ключ HKEY_LOCAL_MACHINE/Security/Policy содержит информацию, необходимую для доступа и расшифровки секретов.
Cекреты LSA, как и хеши SAM, можно получить либо из файлов реестра, либо из памяти процесса lsass.exe.
Если вы владеете правами Администратора, а целевая система задействована на производстве, то я советую выбрать безопасный путь: скопировать системные файлы SYSTEM и SECURITY из реестра с помощью reg.exe/regedit.exe или посредством службы теневого копирования томов, как описано в первой статье. Извлечь секреты LSA из полученных файлов SYSTEM и SECURITY можно утилитой Cain & Abel.
Также существует множество утилит, которые сольют секреты LSA, внедрившись в процесс lsass.exe. Из всех таких утилит gsecdump считается самым надежным, поскольку работает на всех версиях и архитектурах Windows. Для 32-битных систем рекомендую также lsadump2. Несмотря на мои ожидания, двум утилитам от NirSoft (LSASecretsDump и LSASecretsView) ни на одной архитектуре не удалось получить пароли учетных записей служб. В независимости от того, какой именно метод вы использовали, все извлеченные пароли будут в кодировке UTF-16. То есть пароли, в отличие от хешей SAM, будут незашифрованы. Подробное описание формата секретов LSA, сделанное Бренданом Доланом-Гавитом (Brandon Dolan-Gavitt) вы можете найти здесь.
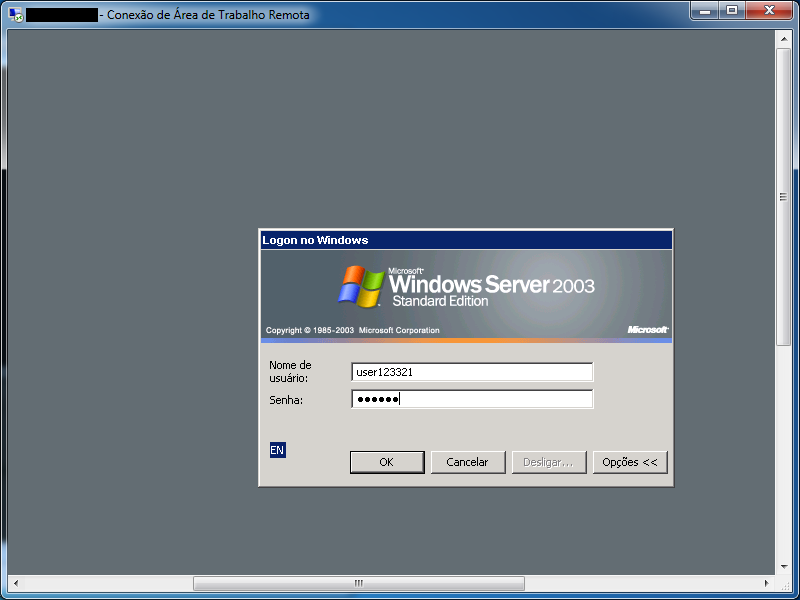
На следующем скриншоте показаны результаты работы gsecdump на Windows Server 2003 с запущенными в контексте пользователя СУБД IBM DB2 и PostgreSQL:

Результаты работы gsecdump.exe –l
К каким угрозам ведет раскрытие секретов LSA
Теперь представьте, что вы скомпрометировали сервер в домене Windows и получили доступ к командной строке с правами Local System.Если вы хотите расширить свой контроль на весь периметр сети, то проверьте, выполняется ли какой-либо сервис в контексте пользователя операционной системы, и если да, то извлеките пароль соответствующей учетной записи из секретов LSA.
Узнать, от какого пользователя запущен сервис можно, выполнив services.mscв Start/Runи отсортировав записи по полю “Вход от имени” (Log On As):

Сервисы, выполняемые в контексте локальных пользователей Windows
Получить информацию о сервисах можно также с помощью sc.exe и других, менее известных утилит. Обычно в контексте пользователей системы работает такое корпоративное программное обеспечение, как Veritas Netbackup, Microsoft SQL Server, Microsoft Exchange. Угрозу представляют случаи, когда системные администраторы запускают сервисы в контексте доменных пользователей или даже доменных администраторов. Подобные действия, конечно же, неправильны, и более того, ставят под угрозу безопасность всего домена, потому что нарушитель может слить секреты LSA, получить пароль администратора в незашифрованном виде, зайти на корневой контроллер домена, и, как следствие, получить контроль над всем доменом.
Описанные в этой статье утилиты я тоже добавил в таблицу. Буду рад вашим отзывам и предложениям!
ИСТОЧНИК: https://www.securitylab.ru/analytics/425268.php
В предыдущих двух статьях из серии, я рассказывал, как получить хеши паролей локальных пользователей (из SAM) и доменных пользователей (из файла NTDS.DIT на контроллере домена).
Автор: Bernardo Damele A. G
История паролей
В предыдущих двух статьях (1, 2) из серии, я рассказывал, как получить хеши паролей локальных пользователей (из SAM) и доменных пользователей (из файла NTDS.DIT на контроллере домена).
Если в настройках парольной политики включен параметр “Требовать неповторяемость паролей” (“Enforce password history”), то Windows сохраняет определенное количество старых паролей, прежде чем разрешить пользователю использовать старые пароли вновь. На следующем скриншоте показано, как именно включить ведение истории паролей:
Local Security Policy (secpol.msc) / Account Policies / Password Policy / Enforce password history
По умолчанию на обычных рабочих станциях параметр “Требовать неповторяемость паролей” установлен в 0, а на контроллерах домена – в 24. Благодаря таким установкам, существует вероятность, что при извлечении хешей из ntds.dit, вы также получите хеши старых паролей. В дальнейшем знание старых хешированных паролей может помочь вам найти закономерности в выборе паролей целевыми пользователями.
Кроме того, знание истории паролей может облегчить вам жизнь на дальнейших этапах проведения атаки. Поэтому никогда не пренебрегайте информацией, полученной из парольной истории.
Наряду с уже известными утилитами (Cain & Abel, PWDumpX) парольную историю можно слить с помощью утилиты pwhist от Toolcrypt.
LSA секреты
LSA секреты – это специальная область реестра, в которой Windows хранит важную информацию. В секреты входят:
- пароли учетных записей служб, требующих запуска в контексте пользователей операционной системы (например, учетные записи Local System, Network Service и Local Service).
- пароли входа в систему при включенном автоматическом входе (auto-logon); в общем случае: пароль пользователя, вошедшего на консоль (запись DefaultPassword).
LSA секреты хранятся в ветке реестра HKEY_LOCAL_MACHINE/Security/Policy/Secrets. Каждый секрет имеет свой собственный ключ. Родительский ключ HKEY_LOCAL_MACHINE/Security/Policy содержит информацию, необходимую для доступа и расшифровки секретов.
Cекреты LSA, как и хеши SAM, можно получить либо из файлов реестра, либо из памяти процесса lsass.exe.
Если вы владеете правами Администратора, а целевая система задействована на производстве, то я советую выбрать безопасный путь: скопировать системные файлы SYSTEM и SECURITY из реестра с помощью reg.exe/regedit.exe или посредством службы теневого копирования томов, как описано в первой статье. Извлечь секреты LSA из полученных файлов SYSTEM и SECURITY можно утилитой Cain & Abel.
Также существует множество утилит, которые сольют секреты LSA, внедрившись в процесс lsass.exe. Из всех таких утилит gsecdump считается самым надежным, поскольку работает на всех версиях и архитектурах Windows. Для 32-битных систем рекомендую также lsadump2. Несмотря на мои ожидания, двум утилитам от NirSoft (LSASecretsDump и LSASecretsView) ни на одной архитектуре не удалось получить пароли учетных записей служб. В независимости от того, какой именно метод вы использовали, все извлеченные пароли будут в кодировке UTF-16. То есть пароли, в отличие от хешей SAM, будут незашифрованы. Подробное описание формата секретов LSA, сделанное Бренданом Доланом-Гавитом (Brandon Dolan-Gavitt) вы можете найти здесь.
На следующем скриншоте показаны результаты работы gsecdump на Windows Server 2003 с запущенными в контексте пользователя СУБД IBM DB2 и PostgreSQL:
Результаты работы gsecdump.exe –l
К каким угрозам ведет раскрытие секретов LSA
Теперь представьте, что вы скомпрометировали сервер в домене Windows и получили доступ к командной строке с правами Local System.Если вы хотите расширить свой контроль на весь периметр сети, то проверьте, выполняется ли какой-либо сервис в контексте пользователя операционной системы, и если да, то извлеките пароль соответствующей учетной записи из секретов LSA.
Узнать, от какого пользователя запущен сервис можно, выполнив services.mscв Start/Runи отсортировав записи по полю “Вход от имени” (Log On As):
Сервисы, выполняемые в контексте локальных пользователей Windows
Получить информацию о сервисах можно также с помощью sc.exe и других, менее известных утилит. Обычно в контексте пользователей системы работает такое корпоративное программное обеспечение, как Veritas Netbackup, Microsoft SQL Server, Microsoft Exchange. Угрозу представляют случаи, когда системные администраторы запускают сервисы в контексте доменных пользователей или даже доменных администраторов. Подобные действия, конечно же, неправильны, и более того, ставят под угрозу безопасность всего домена, потому что нарушитель может слить секреты LSA, получить пароль администратора в незашифрованном виде, зайти на корневой контроллер домена, и, как следствие, получить контроль над всем доменом.
Описанные в этой статье утилиты я тоже добавил в таблицу. Буду рад вашим отзывам и предложениям!
ИСТОЧНИК: https://www.securitylab.ru/analytics/425268.php









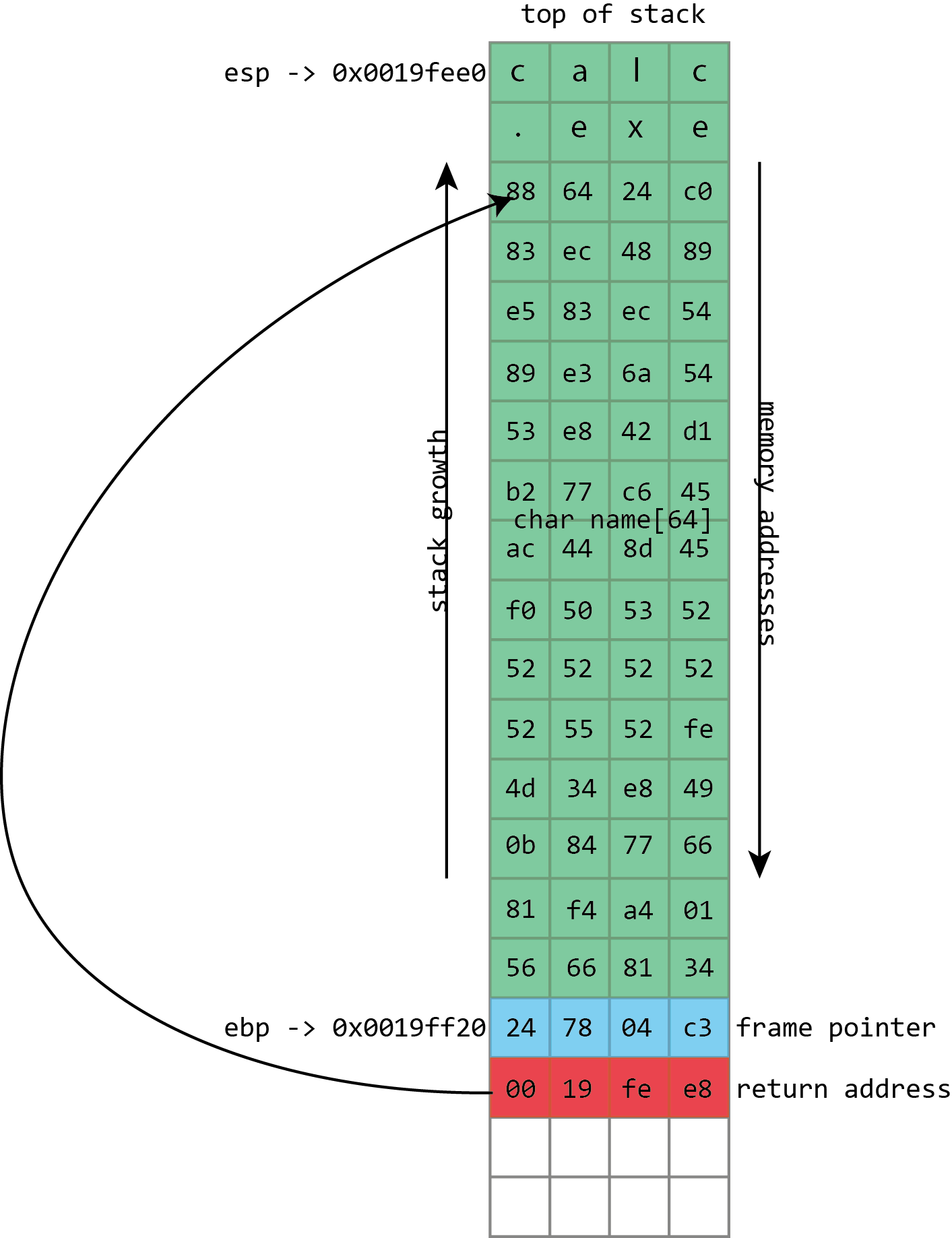

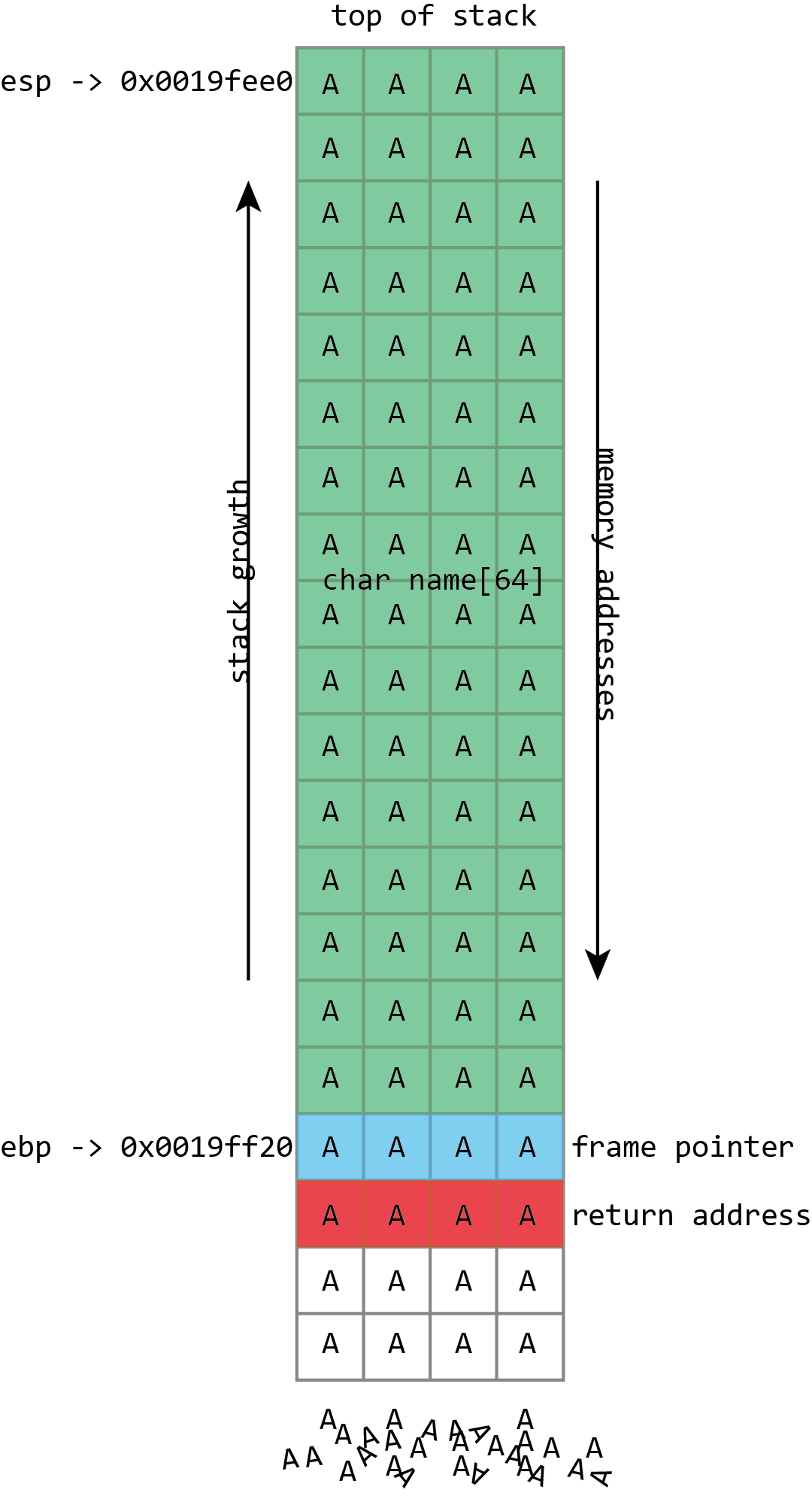
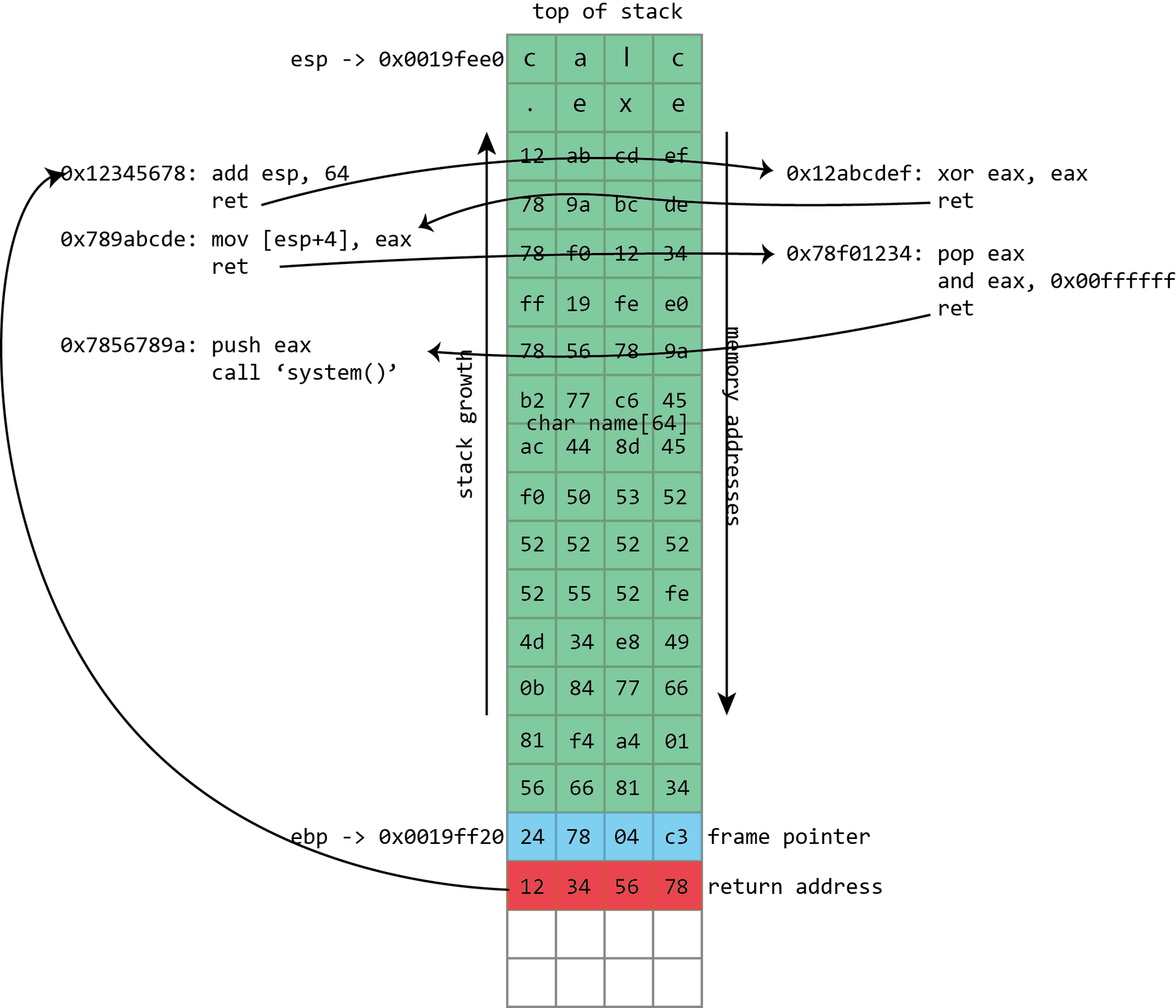


 )
)